示例: spark-submit [--option value] <application jar> [application arguments]
|
参数名称 |
含义 |
|
--master MASTER_URL |
yarn |
|
--deploy-mode DEPLOY_MODE |
Driver程序运行的地方:client、cluster |
|
--class CLASS_NAME |
The FQCN of the class containing the main method of the application. For example, org.apache.spark.examples.SparkPi. 应用程序主类名称,含包名 |
|
--name NAME |
应用程序名称 |
|
--jars JARS |
Driver和Executor依赖的第三方jar包 |
|
--properties-file FILE |
应用程序属性的文件路径,默认是conf/spark-defaults.conf |
|
以下设置Driver |
|
|
--driver-cores NUM |
Driver程序使用的CPU核数(只用于cluster),默认为1 |
|
--driver-memory MEM |
Driver程序使用内存大小 |
|
--driver-library-path |
Driver程序的库路径 |
|
--driver-class-path |
Driver程序的类路径 |
|
--driver-java-options |
|
|
以下设置Executor |
|
|
--num-executors NUM |
The total number of YARN containers to allocate for this application. Alternatively, you can use the spark.executor.instances configuration parameter. 启动的executor的数量,默认为2 |
|
--executor-cores NUM |
Number of processor cores to allocate on each executor 每个executor使用的CPU核数,默认为1 |
|
--executor-memory MEM |
The maximum heap size to allocate to each executor. Alternatively, you can use the spark.executor.memory configuration parameter. 每个executor内存大小,默认为1G |
|
--queue QUEUE_NAME |
The YARN queue to submit to.
提交应用程序给哪个YARN的队列,默认是default队列 |
|
--archives ARCHIVES |
|
|
--files FILES |
用逗号隔开的要放置在每个executor工作目录的文件列表
|
1.部署模式概述
2.部署模式:Cluster
In cluster mode, the driver runs in the ApplicationMaster on a cluster host chosen by YARN.
This means that the same process, which runs in a YARN container, is responsible for both driving the application and requesting resources from YARN.
The client that launches the application doesn't need to continue running for the entire lifetime of the application.
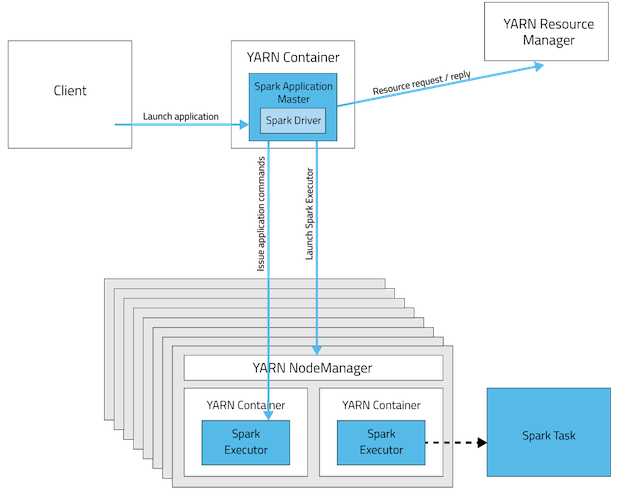
Cluster mode is not well suited to using Spark interactively.
Spark applications that require user input, such as spark-shell and pyspark, need the Spark driver to run inside the client process that initiates the Spark application.
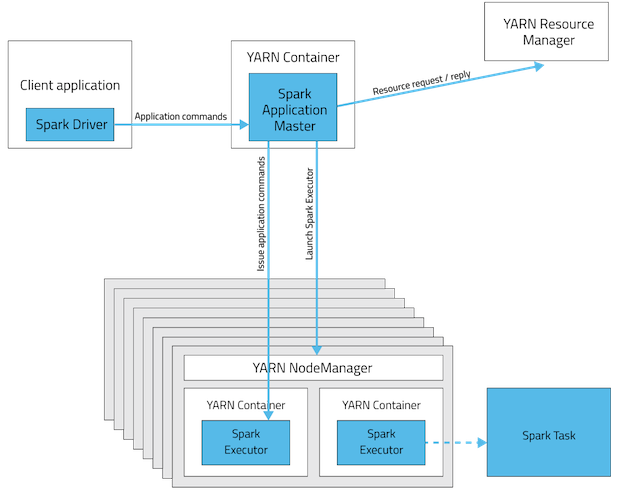
3.部署模式:Client
In client mode, the driver runs on the host where the job is submitted.
The ApplicationMaster is merely present to request executor containers from YARN.
The client communicates with those containers to schedule work after they start:
4.参考文档:
https://www.cloudera.com/documentation/enterprise/5-4-x/topics/cdh_ig_running_spark_on_yarn.html
http://spark.apache.org/docs/1.3.0/running-on-yarn.html