技术选型
下载器是Requests
解析使用的是正则表达式
效果图:

准备好各个包
# -*- coding: utf-8 -*-
import requests #第三方下载器
import re #正则表达式
import json #格式化数据用
from requests.exceptions import RequestException #做异常处理
from multiprocessing import Pool #使用多进程
开始编写代码,new一个py文件
1.requests下载页面
response =requests.get(url)
url:当前需要爬取的链接
requests.get()获取页面
这里需要注意编码的问题;
就像下面这样:
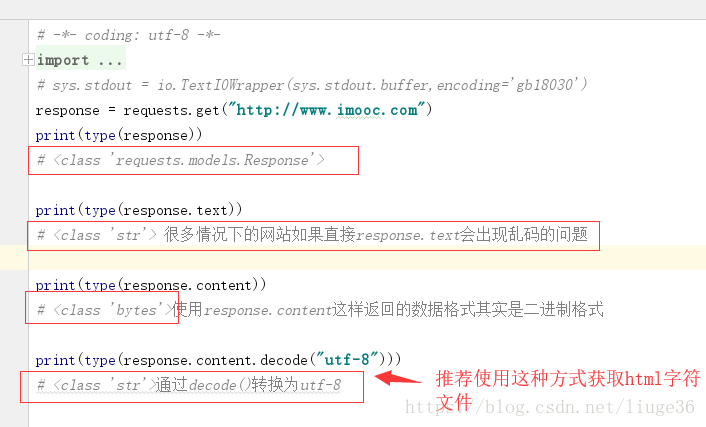
response = requests.get(url)
if response.status_code == 200:
return response.content.decode("utf-8")
return None
这样返回的就是一个string类型的数据
2.except RequestException:捕捉异常
为了代码更加健壮,我们在可能发生异常的地方做异常捕获
try:
response = requests.get(url)
if response.status_code == 200:
return response.content.decode("utf-8")
return None
except RequestException:
return None
更多异常介绍官网
http://www.python-requests.org/en/master/_modules/requests/exceptions/#RequestException
到这里,我们就可以编写main方法进行调用程序了
代码如下:
# -*- coding: utf-8 -*-
import requests
from requests.exceptions import RequestException
def get_one_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.content.decode("utf-8")
return None
except RequestException:
return None
def main():
url = 'https://coding.imooc.com/?page=1'
html = get_one_page(url)
print(html)
if __name__ == '__main__':
main()
这样就可以把页面下载下来了
接着,就是解析页面
3.正则表达式介绍
re.compile()方法:编译正则表达式
通过一个正则表达式字符串 编译生成 一个字符串对象
re.findall(pattern,html)方法:找到所有匹配的内容
参数:
pattern:编译过的正则表达式
html:用response.content.decode("utf-8")得到的页面内容
def parse_one_page(html):
pattern = re.compile('<div class="box">.*?lecturer-info.*?<span>(.*?)</span>.*?shizhan-intro-box.*?title=".*?">'
'(.*?)</p>.*?class="grade">(.*?)</span>.*?imv2-set-sns.*?</i>'
'(.*?)</span>.*?class="big-text">(.*?)</p>.*?shizan-desc.*?>'
'(.*?)</p>.*?</div>',re.S)
items = re.findall(pattern,html)
for item in items:
#格式化每一条数据为字典类型的数据
yield {
'teacher': item[0],
'title': item[1],
'grade': item[2],
'people':item[3],
'score': item[4],
'describe': item[5]
}
完整代码:
# -*- coding: utf-8 -*-
import requests
import re
from requests.exceptions import RequestException
def get_one_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.content.decode("utf-8")
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('<div class="box">.*?lecturer-info.*?<span>(.*?)</span>.*?shizhan-intro-box.*?title=".*?">'
'(.*?)</p>.*?class="grade">(.*?)</span>.*?imv2-set-sns.*?</i>'
'(.*?)</span>.*?class="big-text">(.*?)</p>.*?shizan-desc.*?>'
'(.*?)</p>.*?</div>',re.S)
items = re.findall(pattern,html)
for item in items:
yield {
'teacher': item[0],
'title': item[1],
'grade': item[2],
'people':item[3],
'score': item[4],
'describe': item[5]
}
def main():
url = 'https://coding.imooc.com/?page=1'
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
if __name__ == '__main__':
main()
保存解析后的数据到本地文件
4.保存文件操作
with open('imooctest.txt','a',encoding='utf-8') as f
with as :打开自动闭合的文件并设立对象f进行操作
参数:
imooctest.txt:文件名字
a:追加方式
encoding:编码格式 不这样设置可能保存的数据会乱码
f.write(json.dumps(content,ensure_ascii =False)+'
')
json.dumps:将刚才被格式化后的字典转为字符串
ensure_ascii =False 不这样设置可能保存的数据会乱码
+'
' 每条数据为一行
代码如下:
# -*- coding: utf-8 -*-
import requests
import re
import json
from requests.exceptions import RequestException
def get_one_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.content.decode("utf-8")
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('<div class="box">.*?lecturer-info.*?<span>(.*?)</span>.*?shizhan-intro-box.*?title=".*?">'
'(.*?)</p>.*?class="grade">(.*?)</span>.*?imv2-set-sns.*?</i>'
'(.*?)</span>.*?class="big-text">(.*?)</p>.*?shizan-desc.*?>'
'(.*?)</p>.*?</div>',re.S)
items = re.findall(pattern,html)
for item in items:
yield {
'teacher': item[0],
'title': item[1],
'grade': item[2],
'people':item[3],
'score': item[4],
'describe': item[5]
}
def write_to_file(content):
with open('imooctest.txt','a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False)+'
')
f.close()
def main():
url = 'https://coding.imooc.com/?page=1'
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
main()
5.爬取所有页面并以多进程方式
分析页面,会发现,需要爬取的页面如下
https://coding.imooc.com/?page=1
https://coding.imooc.com/?page=2
https://coding.imooc.com/?page=3
https://coding.imooc.com/?page=4
我们需要构造这种格式的页面
主函数可以类似这样:
for i in range(4):
main(i+1)
完整代码:
# -*- coding: utf-8 -*-
import requests
import re
import json
from requests.exceptions import RequestException
from multiprocessing import Pool
def get_one_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.content.decode("utf-8")
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('<div class="box">.*?lecturer-info.*?<span>(.*?)</span>.*?shizhan-intro-box.*?title=".*?">'
'(.*?)</p>.*?class="grade">(.*?)</span>.*?imv2-set-sns.*?</i>'
'(.*?)</span>.*?class="big-text">(.*?)</p>.*?shizan-desc.*?>'
'(.*?)</p>.*?</div>',re.S)
items = re.findall(pattern,html)
for item in items:
yield {
'teacher': item[0],
'title': item[1],
'grade': item[2],
'people':item[3],
'score': item[4],
'describe': item[5]
}
def write_to_file(content):
with open('imoocAll.txt','a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False)+'
')
f.close()
def main(page):
url = 'https://coding.imooc.com/?page='+str(page)
html = get_one_page(url)
# parse_one_page(html)
# print(html)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
pool = Pool()
pool.map(main,[i+1 for i in range(4)])
# for i in range(4):
# main(i+1)
到这里,我们就能够把慕课网上面的全部实战课程的信息爬取下来,拿到这些数据,你就可以做自己喜爱的分析了