写在前面
、、、
WordCount为例
直接执行这个段代码,根据执行结果,进行分析
object WCApp {
def main(args:Array[String]) = {
val conf = new SparkConf().setMaster("local[2]").setAppName("WCApp")
val sc = new SparkContext(conf)
// 做一个简单的wc统计
sc.textFile("f:/ttt.txt")
.flatMap(_.split(","))
.map((_, 1))
.reduceByKey(_+_)
.foreach(println)
Thread.sleep(10000000)
sc.stop()
}
}
查看执行结果之前,我们先分析一下上面的代码:
包含
textFile() 会将执行路径的数据input进来
flatMap() map() reduceByKey() 这三个转换类型算子
foreach()一个 action 类型的算子
打开127.0.0.1:4040
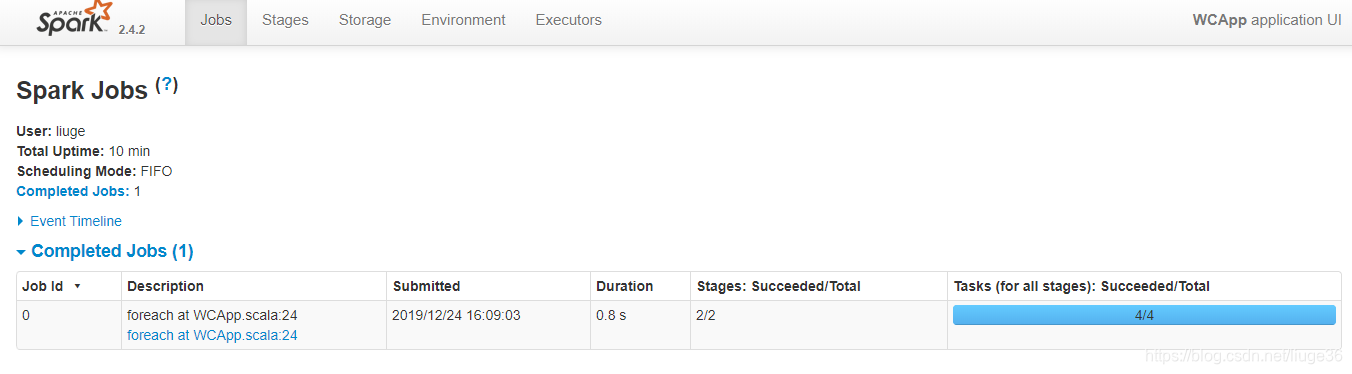
上图分析:

Job 为 1
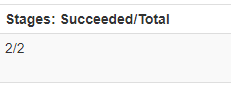
Stage 为 2
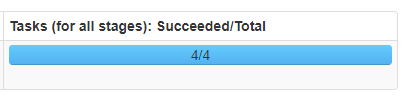
Task 为 4
分析:说明该Application 应用程序只有一个1Job, 这个作业包含2个Stage,2个Stage一共包含4个Task
这里说明一下各个词汇的概念:

所谓一个 job,就是由一个 rdd 的 action 触发的动作,可以简单的理解为,当你需要执行一个 rdd 的 action 的时候,会生成一个 job.比如save &collect

stage 是一个 job 的组成单位,就是说,一个 job 会被切分成 1 个或 1 个以上的 stage,然后各个 stage 会按照执行顺序依次执行。产生shuffle就是一个新的Stage.

Task 是一个工作单元,执行在Executor端,一般来说,一个 rdd 有多少个 partition,就会有多少个 task,因为每一个 task 只是处理一个 partition 上的数据。
从 web ui 截图上我们可以看到,这个 job 一共有 2 个 stage,4 个 task,平均下来每个 stage 有 2个 task,相当于每个 stage 的数据都有 2 个 partition。这也恰恰就是默认的partition数量。

[注意:这里是平均下来的哦,并不都是每个 stage 有 2 个 task,有时候也会有一个 stage 多,另外一个 stage 少的情况,就看你有没有在不同的 stage 进行 repartition 类似的操作了。
运行流程之 : job

一般来说,只要 rdd 触发 action 就会产生一个Job.


运行流程之 : stage
我们这个 spark 应用,生成了一个 job,这个 job 由 2 个 stage 组成,并且每个 stage 都有 2 个task,说明每个 stage 的数据都在 2 个 partition 上,这下我们就来看看,这两个 stage 的情况。
stage的划分是以shuffle操作作为边界的。也就是说某个action导致了shuffle,就会划分出两个stage.这里给大家罗列一些常用的并且可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等
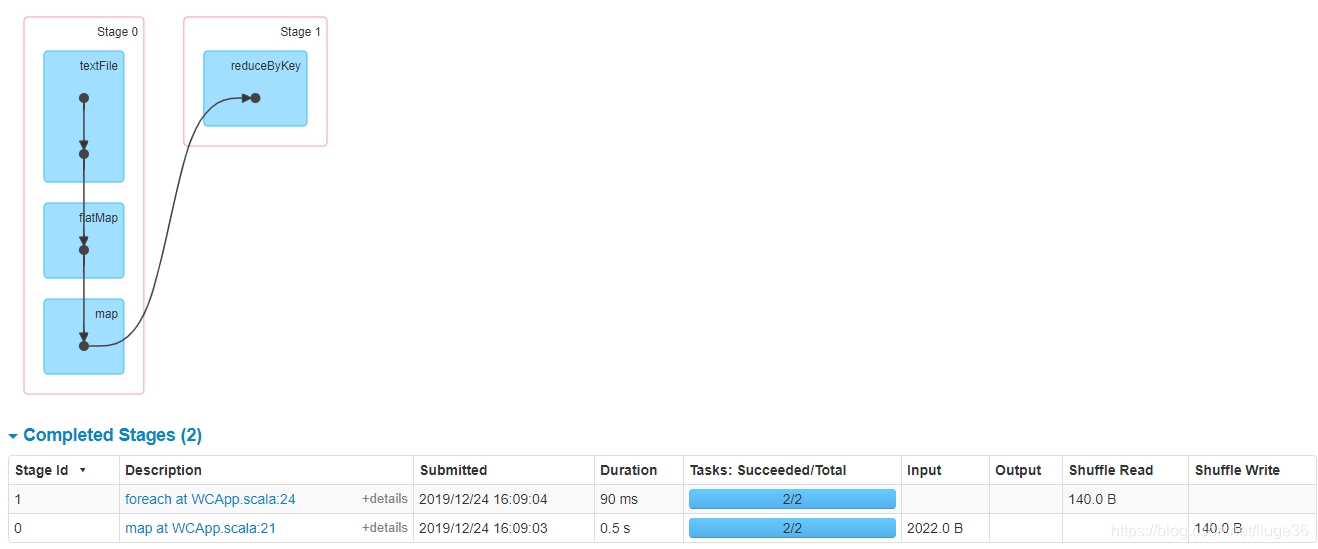
再次回顾上面那张图:这下应该就明了了,关于两个 stage 的情况:

第一个 stage,即截图中 stage id 为 0 的 stage,其执行了sc.testFile().flatMap().map().reduceByKey() 这几个步骤,因为这是一个 Shuffle 操作,所以后面会有 Shuffle Read 和 Shuffle Write。具体来说,就是在 stage 0 这个 stage 中,发生了一个 Shuffle 操作,这个操作读入 2022.0 B 的数据,生成 140.0 B 的数据,并把生成的数据写在了硬盘上。
第二个 stage,即截图中 stage id 为 1 到 stage,其执行了 foreach 这个操作,因为这是一个 action 操作,并且它上一步是一个 Shuffle 操作,且没有后续操作,所以这里 collect() 这个操作被独立成一个 stage 了。这里它把上一个 Shuffle 写下的数据读取进来,然后一起返回到 driver 端,所以这里可以看到他的 Shuffle Read 这里刚好读取了上一个 stage 写下的数据。
运行流程之 : task
Spark应用程序 在群集上作为独立的 进程集运行,由主程序(称为驱动程序)中的SparkContext对象协调。
具体来说,要在集群上运行,SparkContext可以连接到几种类型的集群管理器(Spark自己的独立集群管理器Mesos或YARN),它们可以在应用程序之间分配资源。
连接后,Spark将在集群中的节点上获取执行程序,这些节点是运行计算并为您的应用程序存储数据的进程。
接下来,它将您的应用程序代码(由传递给SparkContext的JAR) 发送给执行者。
最后,SparkContext将 task 发送给 执行程序 以运行。
task = partition
这里引出一个重点
Spark性能优化之数据倾斜篇
https://tech.meituan.com/2016/05/12/spark-tuning-pro.html