1: 字节流和字符流:
InputStream / OutputStream: 两个是为字节流设计的,主要用来处理字节或二进制对象.
Reader / Writer : 两个是为字符流(一个字符占两个字节)设计的,主要用来处理字符或字符串..
字符流处理的单元为2个字节的Unicode字符,分别操作字符、字符数组或字符串,而字节流处理单元为1个字节,操作字节和字节数组。所以字符流是由Java虚拟机将字节转化为2个字节的Unicode字符为单位的字符而成的,所以它对多国语言支持性比较好!如果是音频文件、图片、歌曲,就用字节流好点,如果是关系到中文(文本)的,用字符流好点。
所有文件的储存是都是字节(byte)的储存,在磁盘上保留的并不是文件的字符而是先把字符编码成字节,再储存这些字节到磁盘。在读取文件(特别是文本文件)时,也是一个字节一个字节地读取以形成字节序列。
字节流是最基本的,所有的InputStrem和OutputStream的子类都是,主要用在处理二进制数据,它是按字节来处理的 但实际中很多的数据是文本,又提出了字符流的概念,它是按虚拟机的encode来处理,也就是要进行字符集的转化 这两个之间通过 InputStreamReader,OutputStreamWriter来关联,实际上是通过byte[]和String来关联 在实际开发中出现的汉字问题实际上都是在字符流和字节流之间转化不统一而造成的.
Reader类的read()方法返回类型为int :作为整数读取的字符(占两个字节共16位),范围在 0 到 65535 之间 (0x00-0xffff),如果已到达流的末尾,则返回 -1
inputStream的read()虽然也返回int,但由于此类是面向字节流的,一个字节占8个位,所以返回 0 到 255范围内的 int 字节值。如果因为已经到达流末尾而没有可用的字节,则返回值 -1。因此对于不能用0-255来表示的值就得用字符流来读取!比如说汉字.
2: 操作流程:
操作文件的流程:
a: 使用File类打开一个文件
b: 通过字符流或字节流的子类,指定输出位置。
c: 进行读写操作
d: 关闭!关闭!关闭!
3: 创建文件:
file.exists() // true表示存在; false 表示不存在
如果存在,就可以操作了,如果不存在,可以调用file.createNewFile() 创建文件。但是如果文件的父亲文件夹不存在,则createNewFile()会失败。
所以正确的操作是:
File parent = file.getParentFile() // 获取父文件
if( !parent.exists() ) parent.mkdirs(); //创建所有父文件夹
如果 D:\test 存在,但是D:\test\parent 不存在,下面的代码会抛出异常。
File f = new File("D:\test\parent\myfile.txt"); if( !f.exists()) { try { f.createNewFile(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } }
正确的代码如下:
File f = new File("D:\test\parent\myfile.txt"); if( !f.exists()) { f.getParentFile().mkdirs(); // 会创建所有nessary文件夹 try { f.createNewFile(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } }
4: FileInputStream 是否有缓冲区?
有,所以用完一定要close,否则内存会被沾满
InputStream streamReder = null; try { streamReder = new FileInputStream(new File("folder1/fsdfsdf/fsdffd/fileName4.txt")); while(streamReder.read() != -1) { count++; }
5: OutStream.flush() 的作用?
如果OutputStream 的实现使用了缓存,这个方法用于清空缓存里的数据,并通知底层去进行实际的写操作
如果FileOutputStream 没有使用缓存,因此这个方法调用与否在这个例子的运行结果没有影响。
FileOutputStream 继承 OutputStream ,flush方法查看源码方法体为空,所以flush没起到清除缓存的作用,改用BufferedOutputStream再调用flush()能成功清除缓存
6: ObjectInputStream 和ObjectOutputStream
实现这种功能,被读取和写入的类必须实现Serializable接口,其实该接口并没有什么方法,可能相当于一个标记而已,但是确实不合缺少的。ObjectInputStream与ObjectOutputStream类所读写的对对象中的transient和static类型成员变量不会被读取和写入。
7: BufferedWriter用法,flush作用?
flush: 如果你关闭了字符流就不用flush, 如果你不关闭字符流的话只能刷新调用flush后才能写入,并且清空缓冲区.。flush是为了减少缓冲区堆积过多数据,造成溢出.。
如下例子中同时使用FileWriter, BufferedFileWRiter, 如果同时使用2者,那么性能会大大提高,而单独使用FileWriter操作字符,每写一次数据,磁盘就有一个写操作,性能很差
如果加了缓冲,那么会等到缓冲满了以后才会有写操作,效率和性能都有很大提高。
FileWriter wr = null; BufferedWriter writer = null; try { wr = new FileWriter(new File("D:\test\parent\myfile.txt")); writer = new BufferedWriter(wr); writer.write("string string"); } catch (IOException e1) { } finally { if (wr!=null) { try { wr.close(); } catch (IOException e) { e.printStackTrace(); } } if (writer != null) { try { writer.close(); } catch (IOException e) { e.printStackTrace(); } } }
8: 7中用的FileWriter有什么问题?如何改?
不能指定编码格式,用的本机默认的格式。可以用可以指定编码格式的 OutputStreamWriter / InputStreamReader来代替。
OutputStreamWriter / InputStreamReader 是由字节流转字符流的一个桥梁,可以指定编码格式。
注意: 下面的OutputStreamWriter就可以写文件了,之所以用BufferedWriter包装一下,是想用缓存的功能。
OutputStreamWriter write = null; try { write = new OutputStreamWriter(new FileOutputStream("D:\test\parent\myfile.txt"), "UTF-8"); } catch (UnsupportedEncodingException e1) { e1.printStackTrace(); } catch (FileNotFoundException e1) { e1.printStackTrace(); } BufferedWriter writer = new BufferedWriter(write); try { writer.write("中国"); writer.close(); } catch (IOException e1) { // TODO Auto-generated catch block e1.printStackTrace(); }
9: java String类型编码格式转换?
String newStr = new String(oldStr.getBytes(), "UTF-8");
java中的String类是按照unicode进行编码的,当使用String(byte[] bytes, String encoding)构造字符串时,encoding所指的是bytes中的数据是按照那种方式编码的,而不是最后产生的String是什么编码方式,换句话说,是让系统把bytes中的数据由encoding编码方式转换成unicode编码。如果不指明,bytes的编码方式将由jdk根据操作系统决定。
String oldStr = "中国ABC"; String newStr = new String(oldStr.getBytes(), "UTF-16"); // newStr是乱码 byte[] old = oldStr.getBytes(); byte[] newst = newStr.getBytes(); // 两者的2进制不一样
10: 关于编码问题,注意?
没有明确指定需要使用的字符编码方案时,Java程序通过“java.nio.charset.Charset.defaultCharset().name()”语句来获取默认的字符编码方案,该语句返回的值跟运行Java程序的操作系统的设置有关,在有些操作系统上,该语句返回值可能是UTF-8;在有些操作系统上,该语句返回值可能是GBK;在有些操作系统上,该语句返回值可能是除了UTF-8和GBK以外的其他字符编码方案。这样子,程序的可移植性大大降低。
编码只发生在JVM和底层操作系统(以及网络传输)之间进行数据传输时,如果程序中没有IO操作,那么所有的String和Char都以unicode编码。当从磁盘读取文件或者往磁盘写入文件时使用的编码要一致,也就是编码和解码使用的字符集要一样才不会出现乱码。
11: unicode VS UTF-8
Unicode :又称万国码,顾名思义,unicode中收录了世界各国语言,用以解决传统编码的局限性。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求. Unicode 用2字节表示一个字符
UTF-8:(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码, 英文字母用1字节,汉字用3字节表示。
这里需要澄清的几个问题:
A:Java使用的是Unicode编码。所有的字符在JVM中(内存中)只有一个存在形式就是Unicode。所以一个char占用2字节。
12: java中面向字符的IO类是?
Reader和writer,最常用的是FileReader和FileWriter类不支持自定义编码类型,只能使用系统默认编码。这样做,可能是为了编码一致,减少出差的概率。
13: 如果想自定义编码,怎么做?
使用InputStreamBreader和OutputStramWRiter
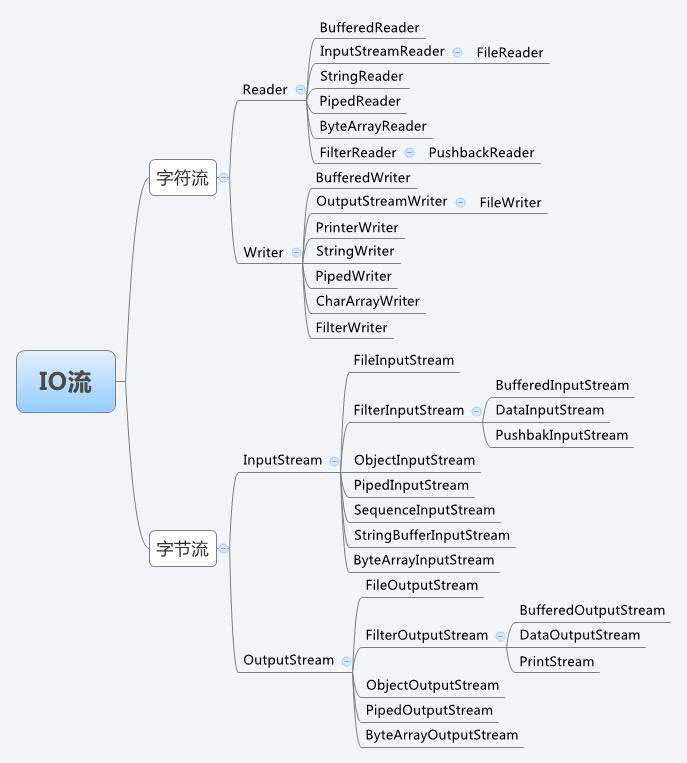
14: java中IO类图?
所有字节相关的都是以Stream结尾; 所有字符相关的都是以writer、reader结尾。
InputStream 和 OutputStream是两个abstact类,对于字节为导向的stream都扩展这两个鸡肋
注意 FileReader的父类是InputStreamReader, FileWriter的父类是OutputStreamWriter。
15: 打开文件时指定字符编码?
InputStreamReader read = new InputStreamReader (new FileInputStream(f),"UTF-8");
注意:FileReader继承了InputStreamReader ,但是不能指定编码
16:两种流之间的转换?
InputStreamReader和OutputStreamReader:把一个以字节为导向的stream转换成一个以字符为导向的stream; 指定编码,把字节流转为字符流。
为了提高效率,用BufferedReader 封装 InputStreamReader
17:JAVA IO的一般使用原则总结:
首先给IO进行分类:
(一)、按数据来源(去向)分类:
1、是文件: FileInputStream, FileOutputStream, FileReader, FileWriter
2、是byte[]:ByteArrayInputStream, ByteArrayOutputStream
3、是Char[]: CharArrayReader, CharArrayWriter
4、是String: StringBufferInputStream(不推荐), StringReader, StringWriter
5、网络数据流:InputStream, OutputStream, Reader, Writer
(二)、按是否格式化输出分:
1、要格式化输出:PrintStream, PrintWriter
(三)、按是否要缓冲分:
1、要缓冲:BufferedInputStream, BufferedOutputStream, BufferedReader, BufferedWriter
(四)、按数据格式分:
1、二进制格式(只要不能确定是纯文本的): InputStream, OutputStream及其所有带Stream结束的子类
2、纯文本格式(含纯英文与汉字或其他编码方式);Reader, Writer及其所有带Reader, Writer的子类
(五)、按输入输出分:
1、输入:Reader, InputStream类型的子类
2、输出:Writer, OutputStream类型的子类
(六)、特殊需要:
1、从Stream到Reader,Writer的转换类:InputStreamReader, OutputStreamWriter
2、对象输入输出:ObjectInputStream, ObjectOutputStream
3、进程间通信:PipeInputStream, PipeOutputStream, PipeReader, PipeWriter
4、合并输入:SequenceInputStream
5、更特殊的需要:PushbackInputStream, PushbackReader, LineNumberInputStream, LineNumberReader
Java IO的一般使用原则:
决定使用哪个类以及它的构造进程的一般准则如下(不考虑特殊需要): 首先,考虑最原始的数据格式是什么: 原则四 第二,是输入还是输出:原则五 第三,是否需要转换流:原则六第1点 第四,数据来源(去向)是什么:原则一 第五,是否要缓冲:原则三 (特别注明:一定要注意的是readLine()是否有定义,有什么比read, write更特殊的输入或输出方法) 第六,是否要格式化输出:原则二