前言
首先,祝大家国庆假期玩的嗨皮!可能有的人已经在回家的路上了,是不是都看不到我的真挚祝福了?
C语言对于一些东西的封装比较少,比如正则表达式,但速度快一直使它立于不败之地,今天就要介绍如何用C封装。
一、正则表达式
1、介绍
应该都听过正则吧?主要应用在字符串匹配,而且它是通用的,各种语言都支持。例如可以用它匹配IP地址、邮箱等。举个例子说明一下正则有啥用:
例如,我在的公司,页面用PHP,后台用C,当添加用户邮箱时,我们老大就要求:PHP和C都要对用户输入的用户邮箱进行校验,这时正则表达式就派上用场了。
2、grep命令
我会用grep进行简单的举例,所以要简单介绍一下。
grep是一种查找过滤工具,正则表达式在grep中用来查找符合模式的字符串。其实正则表达式还有一个重要的应用是验证用户输入是否合法,例如用户通过网页表单提交自己的email地址,就需要用程序验证一下是不是合法的email地址,这个工作可以在网页的Javascript中做,也可以在网站后台的程序中做,例如PHP、Perl、Python、Ruby、Java或C,所有这些语言都支持正则表达式,可以说,目前不支持正则表达式的编程语言实在很少见。
egrep相当于grep -E,表示采用Extended正则表达式语法。
注意grep找的是包含某一模式的行,而不是完全匹配某一模式的行。
3、基本语法
对于正则表达式的语法,我只列出比较常见的,基本就够用了,如果有兴趣的可以再去网上学习,去深入了解。
字符类

数量限定符

位置限定符
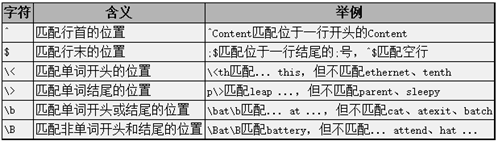
举例:查找IP的正则
用^[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}$查找
其它特殊字符

4、分类
大致分为两类:Basic正则和Extended正则
区别:
以上介绍的是grep正则表达式的Extended规范,Basic规范也有这些语法,只是字符?+{}|()应解释为普通字符,要表示上述特殊含义则需要加转义。如果用grep而不是egrep,并且不加-E参数,则应该遵照Basic规范来写正则表达式。
二、正则表达式相关函数
C语言处理正则表达式常用的函数有regcomp()、regexec()、regfree()和regerror()
C语言中使用正则表达式一般分为三步:
- 编译正则表达式 regcomp()
- 匹配正则表达式 regexec()
- 释放正则表达式 regfree()
下边将对三个函数的详细解释。
1、regcomp函数
功能:这个函数把指定的正则表达式pattern编译成一种特定的数据格式compiled,这样可以使匹配更有效。
原型:int regcomp(regex_t *preg, const char *regex, int cflags);
参数说明:
regex_t 是一个结构体数据类型,用来存放编译后的正则表达式,它的成员re_nsub 用来存储正则表达式中的子正则表达式的个数,子正则表达式就是用圆括号包起来的部分表达式。
参数regex: 是指向我们写好的正则表达式的指针。
参数cflags: 有如下4个值或者是它们或运算(|)后的值:
REG_EXTENDED 以功能更加强大的扩展正则表达式的方式进行匹配。
REG_ICASE 匹配字母时忽略大小写。
REG_NOSUB 不用存储匹配后的结果,只返回是否成功匹配。如果设置该标志位,那么在regexec(在下边介绍)将忽略nmatch和pmatch两个参数。
REG_NEWLINE 识别换行符,这样'$'就可以从行尾开始匹配,'^'就可以从行的开头开始匹配。
2、regexec函数
功能:函数regexec 会使用这个数据在目标文本串中进行模式匹配。
原型:int regexec(const regex_t *preg, const char *string, size_t nmatch,regmatch_t pmatch[], int eflags);
先来介绍下参数4中的regmatch_t结构体:
regmatch_t 是一个结构体数据类型,在regex.h中定义:
typedef struct {
regoff_t rm_so;
regoff_t rm_eo;
} regmatch_t;
成员rm_so 存放匹配文本串在目标串中的开始位置,rm_eo 存放结束位置。通常我们以数组的形式定义一组这样的结构。
参数说明:
preg 是已经用regcomp函数编译好的正则表达式。
string 是目标文本串。
nmatch 是regmatch_t结构体数组的长度。
matchptr regmatch_t类型的结构体数组,存放匹配文本串的位置信息。
eflags 有两个值:
REG_NOTBOL 让特殊字符^无作用
REG_NOTEOL 让特殊字符$无作用
3、regfree函数
功能:可以用这个函数清空regex_t结构体的内容
原型:void regfree(regex_t *preg);
4、regerror函数
功能:当执行regcomp 或者regexec 产生错误的时候,就可以调用这个函数而返回一个包含错误信息的字符串。
原型:size_t regerror(int errcode, const regex_t *preg, char *errbuf,size_t errbuf_size);
参数说明:
errcode 是由regcomp 和 regexec 函数返回的错误代号。
preg 是已经用regcomp函数编译好的正则表达式,这个值可以为NULL。
errbuf 指向用来存放错误信息的字符串的内存空间。
errbuf_size 指明buffer的长度,如果这个错误信息的长度大于这个值,则regerror 函数会自动截断超出的字符串,但他仍然会返回完整的字符串的长度。所以我们可以用如下的方法先得到错误字符串的长度。
三、程序示例
输入两个参数,第一个参数:正则表达式,第二个参数:字符串,校验是否匹配,程序如下:


#include <sys/types.h> #include <regex.h> #include <stdio.h> int main(int argc, char ** argv) { if (argc != 3) { printf("Usage: %s RegexString Text ", argv[0]); return 1; } const char * pregexstr = argv[1]; const char * ptext = argv[2]; regex_t oregex; int nerrcode = 0; char szerrmsg[1024] = {0}; size_t unerrmsglen = 0; if ((nerrcode = regcomp(&oregex, pregexstr, REG_EXTENDED|REG_NOSUB)) == 0) { if ((nerrcode = regexec(&oregex, ptext, 0, NULL, 0)) == 0) { printf("%s matches %s ", ptext, pregexstr); regfree(&oregex); return 0; } } unerrmsglen = regerror(nerrcode, &oregex, szerrmsg, sizeof(szerrmsg)); unerrmsglen = unerrmsglen < sizeof(szerrmsg) ? unerrmsglen : sizeof(szerrmsg) - 1; szerrmsg[unerrmsglen] = '�'; printf("ErrMsg: %s ", szerrmsg); regfree(&oregex); return 1; }
演示匹配邮箱:
执行:./a.out "^[a-zA-Z0-9]+@[a-zA-Z0-9]+.[a-zA-Z0-9]+" "ldw@itcast.com"
演示结果如下:

总结
希望喜欢的点关注,不迷路哦!会持续更新linux C/C++相关内容,谢谢支持!