引言
做接口测试的时候,我通常需要对返回的数据转换成json格式的字符串,这样通常使用到json库,而json模块四个方法:dump、dumps、load、loads。其中dump和load是操作文件,dumps和loads是操作python对象的。
知识点
前面说过python对象包括三个基本要素:唯一身份识别(id),类型(type)和值(value)。
而python3类型有6个标准的数据类型:
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
Python3 的六个标准数据类型中:
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
序列化:json.dumps()将python对象转化成json字符串
import json
a = {'a':1,'b':2}
to_json = json.dumps(a,indent=True)
print(to_json)
print(type(to_json))
运行结果:
{
"a": 1,
"b": 2
}
<class 'str'>
Process finished with exit code 0
反序列化:json.loads()将json字符串转化python对象
import json
a = {'a':1,'b':2}
to_json = json.dumps(a,indent=True)
print(to_json)
print(type(to_json))
to_str = json.loads(to_json)
print(to_str)
print(type(to_str))
运行结果:
{
"a": 1,
"b": 2
}
<class 'str'>
{'a': 1, 'b': 2}
<class 'dict'>
Process finished with exit code 0
Json序列化与反序列化(其他类型)
'''json的序列化与反序列化
json格式的字符串类型
json序列化:把python的数据类型转换为json的字符串
json反序列化:把json的字符串转换为python的数据类型
'''
'''字典的序列化与反序列化'''
# 字典的序列化
import json
dict1 = {'name': 'AI', 'age': 18, 'address': 'beijing'} # 注意:字典类型中,键值都是单引号,而json格式,是双引号
new = json.dumps(dict1)
print(new, type(new))
# 运行结果如下:
# {"name": "AI", "age": 18, "address": "beijing"} <class 'str'>
# 字典的反序列化
newdict = json.loads(new)
print(newdict, type(newdict))
# 运行结果如下:
# {'name': 'AI', 'age': 18, 'address': 'beijing'} <class 'dict'>
'''列表的序列化与反序列化'''
# 列表的序列化
list1 = ["aa", "bb", "cc"]
list_str = json.dumps(list1)
print(list_str, type(list_str))
# 运行结果如下:
# ["aa", "bb", "cc"] <class 'str'>
# 列表的反序列化
newlist = json.loads(list_str)
print(newlist, type(newlist))
# 运行结果如下:
# ['aa', 'bb', 'cc'] <class 'list'>
'''元组的序列化与反序列化'''
# 元组的序列化
tuple1 = ("aaa", "bbb", "ccc")
tuple_str = json.dumps(tuple1)
print(tuple_str, type(tuple_str))
# 运行结果如下:
# ["aaa", "bbb", "ccc"] <class 'str'>
# 元组的反序列化
newtuple = json.loads(tuple_str)
print(newtuple, type(newtuple))
# 运行结果如下:
# ['aaa', 'bbb', 'ccc'] <class 'list'> # 此处需要注意:元组的反序列化结果类型是列表,而非元组
'''文件的序列化与反序列化: 此过程也可理解为,文件序列化是把内容写进json文件中,读取的时候进行反序列化'''
import json
accounts={10: {'name': 'AI', 'age': 18, 'address': 'beijing'}} # 原始数据
def json_file():
with open('info.json', 'w') as f1:
f1.write(json.dumps(accounts)) # 写入时对文件进行序列化
with open('info.json', 'r') as f2:
type_json = json.load(f2) # 读取时对文件进行反序列化
print("反序列化后的内容:", type_json, "类型:", type(type_json))
type_json['sex'] = 'boy' # 对文件内容进行更改
json.dump(type_json, open('info.json', 'w')) # 修改后的内容写入到json格式的文件中
if __name__ == '__main__':
json_file()
# 查看json文件内容显示如下:
# {"10": {"name": "AI", "age": 18, "address": "beijing"}, "sex": "boy"}
运行结果
{"name": "AI", "age": 18, "address": "beijing"} <class 'str'>
{'name': 'AI', 'age': 18, 'address': 'beijing'} <class 'dict'>
["aa", "bb", "cc"] <class 'str'>
['aa', 'bb', 'cc'] <class 'list'>
["aaa", "bbb", "ccc"] <class 'str'>
['aaa', 'bbb', 'ccc'] <class 'list'>
反序列化后的内容: {'10': {'name': 'AI', 'age': 18, 'address': 'beijing'}} 类型: <class 'dict'>
Process finished with exit code 0
json.dumps格式化输出
如果是json格式的数据,打印出来就是一行,显然不雅观,如果想美化一下,可以这样:
data={
"msgBody":{
"data":
{
"imgType": "",
"imgURL": "image url",
"imgLike": 0.5
}
},
"msgHead":{
"Token": "",
"Code": "",
"rmsg": "hello",
}
}
data = json.dumps(data, sort_keys=True, indent=4, separators=(', ',': '))
print(data)
输出结果:
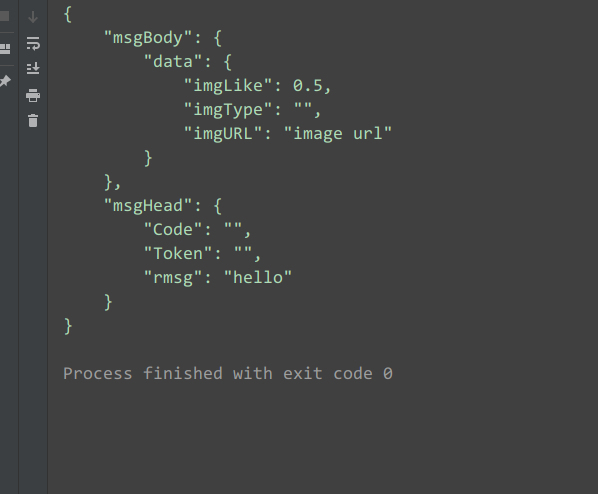
参数解析:
1、sort_keys是告诉编码器按照字典key排序(a到z)输出。
2、indent参数根据数据格式缩进显示,读起来更加清晰, indent的值,代表缩进空格式:
3、separators参数的作用是去掉‘,’ ‘:’后面的空格,在传输数据的过程中,越精简越好,冗余的东西全部去掉。
4、输出真正的中文需要指定ensure_ascii=False,如果无任何配置,或者说使用默认配置,输出的会是‘凉凉’的ASCII字符吗,而不是真正的中文。这是因为json.dumps 序列化时对中文默认使用的ascii编码。
如图:
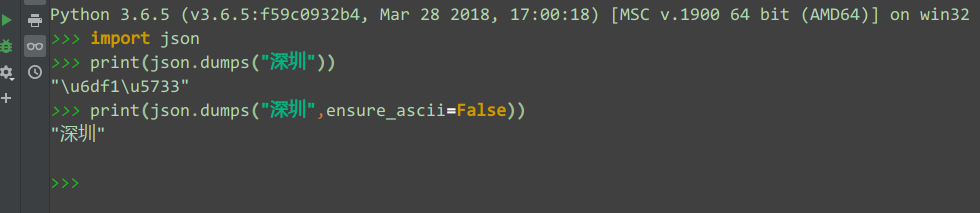
5、skipkeys参数,在encoding过程中,dict对象的key只可以是string对象,如果是其他类型,那么在编码过程中就会抛出ValueError的异常。skipkeys可以跳过那些非string对象当作key的处理。
总结
json序列化与反序列化的知识基本上就是这些,在以后做接口测试中会经常用到,其实在文章(接口实战篇)里我已经用到这些。打好基础,以后会更得心应手。
另外,对测试开发,自动化测试,全栈测试相关技术感兴趣的朋友,可以加入到群里学习和探索交流,进群方式,扫下方二维码。