pip install Django
>>> import django >>>django.get_version()
django-admin startproject mysite
将该项目mark as Sources Root方便代码提示和导入路径
mysite/:根目录,仅仅只是项目的容器【名称可以随意重命名】
manage.py:让你用各种方式管理Django项目的命令行工具
mysite/:一个纯的python包,它包含着你的项目
__init__.py:一个空文件,告诉Python该目录是一个Python包
settings.py:Django项目的配置文件
urls.py:Django项目的配置文件,就像你网站的“目录” wsgi.py
python3 manage.py runserver 0.0.0.0:8000
# 在主目录下 python manage.py startapp SDD
我创建得这个应用模块SDD,导致了项目启动报找不到SDD这个模块,然后我删掉这个模块使用:
python manage.py startapp sdd
就不出现这个问题了。估计是SDD名称不符合Django命名规范吧。
python manage.py createsuperuser
// setting文件中加入: USE_L10N = False DATE_FORMAT = 'Y-m-d' DATETIME_FORMAT = 'Y-m-d H:i:s' // 注意事项:如果USE_L10N设置为了True,那么语言环境规定的格式具有更高的 // 优先级并将被应用,即DATE_FORMAT不生效。
https://docs.djangoproject.com/zh-hans/2.1/intro/tutorial02/#database-setup
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'lcfzjc', 'USER': 'root', 'PASSWORD': 'root', 'HOST': '127.0.0.1', 'PORT': '3306', } }
如果按照好pymysql之后,依旧报是否安装来mysqlclient、mysql-db,这时候就需要我们使用pymysql伪装成其他两个包了,伪装的方式就如上图,在程序最开始执行的地方,执行:
pymysql.install_as_MySQLdb()
不一定是在init文件中,也可以在manage或settings中。
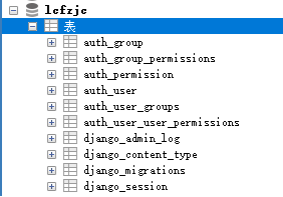
// 执行迁移,会创建django自带模块中的表
python manage.py migrate
执行这句话回初始化setting.py文件中INSTALLED_APPS中:
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ]
https://docs.djangoproject.com/zh-hans/2.1/intro/tutorial02/#creating-models
// 创建polls模块的迁移文件 python manage.py makemigrations polls // 执行迁移 python manage.py migrate
# 在命令行打印数据库对应的models模型文件 python manage.py inspectdb # 将输出的模型输入到项目的models文件里 python manage.py inspectdb > ./models00.py
class Interactive(models.Model): intention = models.TextField(blank=True, null=True)) class Meta: managed = False // 不然django管理我们的模型,执行迁移无效 db_table = 'zndz_manage_interactive'
class Garde(models.Model): className = models.CharField(max_length=32) class Student(models.Model): name = models.CharField(label='姓名', max_length=20, default='', help_text=_('帮助文档。'), ) age = models.IntegerField(label='年龄') garde = models.ForeignKey(Garde,null=True,blank=True,on_delete=models.CASCADE)
// python manage.py shell // 获取单个对象,使用get记得要是有try except Student.objects.get(ID=1) Student.objcets.all().first() Student.objcets.all().last() // 过滤 Student.objects.filter(age__gt = 30) // 获取年龄大于30的 Student.objcets.exclude(age_gt = 30) // 除了年龄大于30的,其余的都获取 // 排序 Student.objects.all().order_by('-ID') // id倒序 // 计数 与 判断 s = Student.objects.filter(age = 30) if s.count(): if s.exists(): // 切片 Student.objcets.all()[0:5] // 会被转换为SQL limit 0,5,注意这和python里的切片不太一样,这里的切片代表的 // 是limit,且不能为负数,python里的切片可以为负数 // 缓存集 filter、exclude、all都不会真正的去查询数据库,只有我们在迭代结果集,或 者获取单个对象属性的时候,它才会去查询数据库。 // 查询条件 __gt __lt __grt __lte __in __contains // like __startswith // like __endswith // // like __exact // 精确等于,即= // 以上四种前面如果加i(即ignore)表示忽略大小写,例如iexact // django 中的查询条件有时区问题,有两种解决方案 1.关闭django自定义的时区,直接将setings里的USE_TZ改成False即可 2.在数据库中创建时区表(麻烦,不推荐) // 聚合关系 Student.objects.aggregate(Max("age")) // 最大年龄的学生 .aggregate(Avg("age")) .aggregate(Max("age")) Count|Min|Sum // F对象:可以使用模型的A属性与B属性进行比较 // 可以实现一个模型的不同属性的算符运算操作 // 还可以支持算术运算 Grades.objects.filter(ggirlnum__gt=F('gboynum')) // 找到女生人输大于男生人数的班级 // Q对象:过滤器的方法中的关键字参数,条件为And模式,采用逻辑或引入Q对象 // 可以对条件进行封装,封装之后,可以支持逻辑运算: // 与 & // 或 | // 非 ~ studentList = Student.objects.filter(Q(pk__lt = 3)|Q(sage__gt=50)) pk_id小于3或年龄大于50岁 models.User.objects.filter(Q(username='老王') & Q(userpass='admin')) 条件与组合 models.User.objects.filter(~Q(username='老王')) 条件非表示取反 可以使用 &(and) |(or) ~(not) 结合括号进行分组,构造更复杂的Q对象 filter函数可以传递一个或多个Q对象作为位置参数,如果有多个Q对象,这些参数的逻辑为and
学习网址:https://my.oschina.net/liuyuantao/blog/751902
在模型查询API不够用的情况下,还可以使用原始的SQL语法。Django提供两种方法使用原始的SQL查询,一种是使用Manager.raw()方法,进行原始查询并返回模型实例;另一张是完全避开模型层,直接执行自定义SQL语句。【编写原始的SQL语句时,应该格外小心。 每次使用的时候,都要确保转义了参数中任何用户可以控制的字符,以防受到SQL注入攻击】
Manager.raw(raw_query, params=None, translations=None)
这个方法执行原始的SQL查询,并返回一个django.db.models.query.RawQuerySet 实例。这个RawQuerySet 实例可以像一般的查询集那样,通过迭代来提供对象实例。
objects为ORM的隐性属性,我们默认可以使用对象的objects去查询数据,当然我们也可以显示的声明别名:
# Create your models here. class Student(models.Model): name = models.CharField(max_length=32) mk = models.Manager()
>>> from demo.models import Student >>> Student.objects.all() Traceback (most recent call last): File "<console>", line 1, in <module> AttributeError: type object 'Student' has no attribute 'objects' >>> Student.mk.all() <QuerySet [<Student: Student object (1)>]>
class StudentManager(models.Manager): def get_queryset(self): """ 重写query_set :return: """ return super(StudentManager, self).get_queryset().filter(name__contains='mao') class Student(models.Model): name = models.CharField(max_length=32) objects = StudentManager() // 测试 >>> from demo.models import Student >>> Student.objects.all() <QuerySet [<Student: Student object (1)>]> >>> Student.objects.all().first().name 'maomao'
from django.forms.models import model_to_dict from django.core.serializers import serialize # 序列化单个实体为json对象 user = User() user.created_id = created_id user.name = request.POST['name'] user.save() return JsonResponse({'code': 200, 'msg': "success", 'data': model_to_dict(user)}) # 序列化多个实体为json对象 uid = request.POST['id'] users = User.objects.filter(created_id=uid, delated=0) return JsonResponse({'code': 200, 'msg': "success", 'data': serialize('json', users)}) # 以上针对数据库操作发实体都是对象,所以可以使用model_to_dict或serizlize # 但如果从数据库查询的不是一个实体对象则不能使用上面两种方式 users = User.objects.values('id', 'name', 'sex', 'age', 'phys', 'is_app_user').filter(Q(id=uid) & Q(deleted=1)) # 如上users返回的结果已经是一个字典类型,或Queryset里面封装的是字典类型 # 使用value或value_list查询的数据直接就是字典类型了
models.OneToOneField()
// 需要其中一张表的主键作为另一张表的外键即可,保留外键的表称为从表 class Person(models.Model): // 主表 name = models.CharField(max_length=16) class Card(models.Model): // 从表 number = models.CharField(max_length=32) person = models.OneToOneField(Person,blank=True,null=True) // 绑定卡与人的一对一关系,默认情况下,当人被删除的情况下,与人绑定的卡也被删除了, // 我们可以使用on_delete参数进行调整 on_delete models.CASCADE 默认值 models.PROTECT 保护模式 models.SET_NULL 置空模式 models.SET_DEFAULT 置默认值 models.SET() 删除的时候重新动态指向一个实体
当系统遭遇不可避免毁灭时,只能保留一张表,这个表就是你的主表
models.ForeginKey()
使用显性属性,属性是Manager子类ManyRelateManager。从.主属性.操作
也是Manager子类,操作和从操作主完全一样。使用隐性属性:主.从_set.操作
默认继承会将通用字段放到父表中,特定字段放在自己的表中,中间用外键连接。
class Animal(models.Model): name = models.CharField(max_length=20) class Cat(Animal): like = models.CharField(max_length=10) class Dog(Animal): like = models.CharField(max_length=10) 表结构: -- auto-generated definition create table demo_animal ( id integer not null primary key autoincrement, name varchar(20) not null ); -- auto-generated definition create table demo_cat ( animal_ptr_id integer not null primary key references demo_animal deferrable initially deferred, like varchar(10) not null ); -- auto-generated definition create table demo_dog ( animal_ptr_id integer not null primary key references demo_animal deferrable initially deferred, like varchar(10) not null ); // 可以看到在子类中都将父类Animal作为了他们的外键参考,且外键作为主键唯一, // 相当于一对一关联!这也就导致了新增一个子类,就新增一个父类!其实,我们只想 // 将公共的字段抽象提取出来,并不想在数据库中也将父表建立出来,这时我们应该在 // 父类的元信息上做说明
class Animal(models.Model): name = models.CharField(max_length=20) class Meta: abstract = True
<form action="{% url 'demo:register' %}" method="post" enctype="multipart/form-data"> {% csrf_token %} 用户名: <input type="text" name="username"> 头像: <input type="file" name="img"> <input type="submit"> </form> // 万金油写法 def register(request): if request.method == 'POST': # username = request.POST.get('username') img = request.FILES.get('img') BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) with open(os.path.join(BASE_DIR, 'static/upload/imgs/', img.name), 'wb') as f: for chunk in img.chunks(): f.write(chunk) f.flush() return HttpResponse('注册成功!') else: return redirect(to=reverse('demo:register'))
// 使用Django model模型提供的上传 class User(models.Model): name = models.CharField(max_length=16) img = models.ImageField(upload_to='imgs/%Y') // 这里面的upload_to属性是以settings文件中MEDIA_ROOT属性指定的值 // 为相对路径的,所有我们需要在settings文件中配置一下MEDIA_ROOT // 在upload_to中支持日期写法%Y年,%M月,日时分秒等 // 需要安装Pillow包,用于Django验证图片 // settings配置文件最后加入上传相对路径 MEDIA_ROOT = os.path.join(BASE_DIR, 'static/upload') def register(request): if request.method == 'POST': username = request.POST.get('username') img = request.FILES.get('img') user = User() user.name = username user.img = img user.save() return HttpResponse('注册成功!') else: return redirect(to=reverse('demo:register'))
//如果上传同名文件,Django还会帮我们在文件名后加入一些混淆码来区别,这给使用用户
// 头像等带来了很大方便
使用模板时首先在根目录下创建templates目录,将该templates Mark as templates,方便我们在代码中给提示。然后配置settings.py:
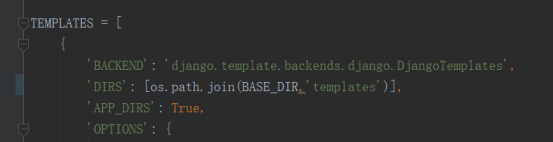
这里的DIRS指的是根目录下的templates,根目录下的templates一般放入一些基类html,如果没有应用模块,则:
def index(request): return render(request,'sdd.html')
为了更好的项目结构,我们一般在我们的应用模块内也建立一个自己的templates,在应用模块也添加一个sdd.html,依旧是上面的代码,Django并不会去找该应用模块内的templates下的html,要想让其寻找自己模块内的templates,首先要创建一个和应用文件夹名相同的文件,在把sdd.html丢进去,目录结构如下:
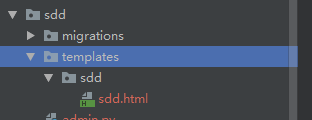
def index(request): return render(request,'sdd/sdd.html')
这样就ok了,Django会先去自己ide应用中查找sdd.html如果没找到会去项目的templates目录里寻找sdd/sdd.html文件。
{% extends 'base.html' %}
{% block content %}
2017-12-12
{% endblock %}
// include:加载模板进行渲染
// 格式:{% include 'xxx' %}
{% block content %}
{% include 'header.html' %}
{% endblock %}
{% include 'footer.html' %}
//可以覆盖父类中的内容,如果不想覆盖:
{% block content %}
{{ block.super }}
{% endblock %}
// 注意:能使用block+extedns解决的,就不要使用include
// for循环:如果列表为空指向empty之后的语句,否则执行语句1 {% for 变量 in 列表 %} 语句1 {% empty %} 语句2 {% endfor %} // forloop循环 {{forloop.counter}}表示当前是第几次循环,从1开始数 {{forloop.counter0}}表示当前是第几次循环,从0开始 {{forloop.revcounter}}表示当前是第几次循环,倒着开始数,到1停止 {{forloop.revconter0}}表示当前第几次循环,倒着数,到0停 {{forloop.first}}是否是第一个 布尔类型 {{forloop.last}}是否是最后一个 布尔类型 // ifequal 如果相等,ifnotequal如果不相等 {% ifequal value1 value2 %} 语句 {% endifequal %} // 使用static请求地址 <img src="{{ static('path/to/company-logo.png') }}" alt="Company Logo"> // 使用url编写链接,反向解析 <a href="{{ url('admin:index') }}">Administration</a> // 调用方法 {% if user.is_authenticated %}Hello, {{ user.username }}.{% endif %} // 模板过滤器 {{ my_date|date:"Y-m-d" }} // 表单防止跨站请求伪造保护,在settings中要将配置开启:'django.middleware.csrf.Csre.CsreViewMiddleware' {% csrf_token %} // 模板注释 {# <h1><h1> #} // 注释一行 // 注释多行 {# comment #} <h1><h1> {# endcomment #} // 更多语法参见 https://docs.djangoproject.com/en/2.2/topics/templates/
add 加法{{ value|add 1 }} 减法{{ value|add -1 }}
lower 转小写{{ name|lower }}
upper 转大写{{name|upper}}
join 字符连接{{name|join '@'}}
// HTML转义[谨慎使用]
{{ code|safe }}
// 还有一种可以转义
// HTML渲染
{% autoescape off %}
{{code}}
{% endautoescape %}
// 不渲染HTML
{% autoescape on %}
{{code}}
{% endautoescape %}
from django.http import HttpResponse from django.template import loader def index(request): temp = loader.get_template('index.html') context = temp.render() return HttpResponse(context)
其实我们使用模板也就是类似使用文件流对象读取index.html文件里的内容,然后直接拼接成字符串传递给HttpResponse对象,Django会将字符串中的标签渲染到页面。loader与我们直接使用文件流的方式不同的时,Django提供的loader不仅仅可以读取文件还能够帮助我们渲染模板标签。
在settings.py文件配置如下,然后在manage.py目录下新建static文件
STATIC_URL = '/static/' STATICFILES_DIRS = [ os.path.join(BASE_DIR, 'static'), ]
{% load static %}
<link href="{% static 'bootstrap-4.1.1/css/bootstrap.min.css' %}" rel="stylesheet">
{% load staticfiles %} <!--写static 和 staticfiles是一样的-->
<script src="{% static 'jquery-3.3.1.js' %}"></script>
<script src="{% static 'bootstrap-4.1.1/js/bootstrap.min.js' %}"></script>
DEBUG=False
则就不在能访问到静态资源路径,开发者服务器不在提供访问静态资源。解决办法就是使用高性能的服务器如Nginx等来处理。
在使用Nginx将项目部署在Linux上时,遇到一个问题,由于我的静态目录static有两块,一块时Django项目里的static,另一块是使用vue写的前端打包后的dist/static,我在项目的settings目录下直接在访问静态路径这块写了个数组,可以存放多个静态路径,但是到了把Nginx当作HTTP服务器去配置静态访问路径时,遇到了一个问题,就是怎么去在一个正则loaction内写两个静态路径,或者写具有相同正则的location去分开写两个静态路径:
# 匹配静态目录路由 location /static { alias /home/liuwei/PycharmProjects/DjangoProDemo/DjangoDemo/static; }
我尝试使用逗号或空格隔开这两个路径都会在访问时访问不到一些静态文件,而分开写两个static location感觉又很不合适,所以我只好选择合并项目的static目录:
- 根目录下执行 python manage.py collectstatic - 如果报错提示: django.core.exceptions.ImproperlyConfigured: You're using the staticfiles app without having set the STATIC_ROOT setting to a file system path. - 你需要在setting.py中设置一下STATIC_ROOT STATIC_ROOT = os.path.join(BASE_DIR, "static") STATIC_URL = '/static/' STATICFILES_DIRS = [ os.path.join(BASE_DIR, "static"), os.path.join(BASE_DIR, "structfront/dist/static"), ]
执行合并命令时,它只会关注STATIC_ROOT配置的目录地址,然后扫描整个项目的静态资源(包含依赖包中的),将静态资源写入到STATIC_ROOT配置的目录中。注意:执行完该命令后要将STATIC_ROOT注释掉。当你在使用Nginx作用HTTP服务器的时候我想在setting.py中所有有关静态资源的配置已经不在起作用了。
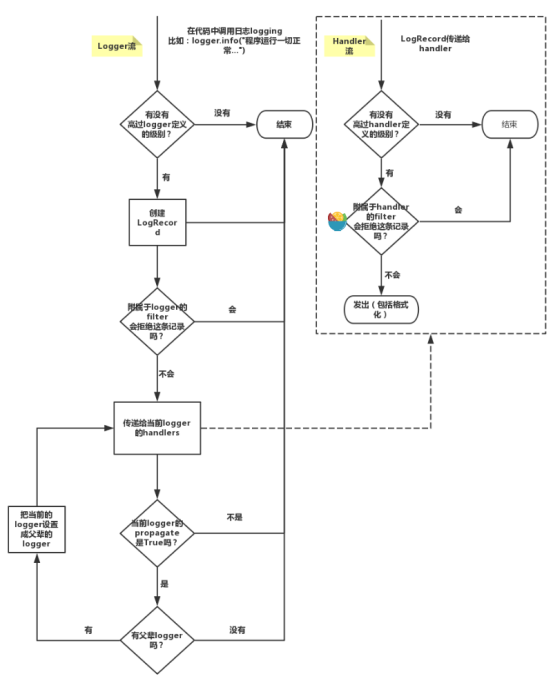
# 日志优先级 OFF > FATAL > ERROR > WARN > INFO > DEBUG > TRACE > ALL
# 在setting文件中添加: LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console': { 'class': 'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'level': 'DEBUG' if DEBUG else 'INFO', }, }, }
# 在setting文件中添加: # 输出到控制台 LOGGING = { 'disable_existing_loggers': False, 'version': 1, 'handlers': { 'console': { # logging handler that outputs log messages to terminal 'class': 'logging.StreamHandler', 'level': 'DEBUG', # message level to be written to console }, }, 'loggers': { '': { # 这会将根级别记录器设置为记录调试和更高级别 # 记录到控制台。 所有其他记录器都继承自 # 根级记录器。 'handlers': ['console'], 'level': 'DEBUG', 'propagate': False, # this tells logger to send logging message # to its parent (will send if set to True) }, 'django': { # django自己的,我们只是重写一下 'handlers': ['default', 'console'], 'level': 'DEBUG', 'propagate': False }, 'django.request': { # django自己的,我们只是重写一下 'handlers': ['request_handler'], 'level': 'DEBUG', 'propagate': False, }, 'django.db': { # # django also has database level logging 'handlers': ['console'], 'level': 'DEBUG', 'propagate': False, }, }, }
# 输出到日志文件 #导入模块 import logging import django.utils.log import logging.handlers LOGGING = { 'version': 1, # 保留字 'disable_existing_loggers': True, # 是否禁用已经存在的日志实例 'formatters': { # 定义日志格式 'standard': { 'format': '%(asctime)s [%(threadName)s:%(thread)d] [%(name)s:%(lineno)d] [%(module)s:%(funcName)s] [%(levelname)s]- %(message)s' }, #日志格式 'simple': { 'format': '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' }, 'collect': { 'format': '%(message)s' } }, 'filters': { 'require_debug_true': { # 定义日志的过滤器 '()': 'django.utils.log.RequireDebugTrue', }, }, 'handlers': { 'mail_admins': { 'level': 'ERROR', 'class': 'django.utils.log.AdminEmailHandler', # 将规定级别及以上的消息通过电子邮件发送 'include_html': True, }, 'default': { 'level':'DEBUG', 'class':'logging.handlers.RotatingFileHandler', # 若日志超过指定文件的大小,会再生成一个新的日志文件保存日志信息 'filename': '/sourceDns/log/all.log', #日志输出文件 'maxBytes': 1024*1024*5, #文件大小5M 最好不要超过1G 'backupCount': 3, #备份份数 xx.log --> xx.log.1 --> xx.log.2 --> xx.log.3 'formatter':'standard', #使用哪种formatters日志格式 'encoding': 'utf-8', # 文件记录的编码格式 }, 'error': { 'level': 'DEBUG', 'class': 'logging.handlers.TimedRotatingFileHandler', # 日志按照天数滚动 'filename': '/'.join((log_path, 'log.txt')), 'when': 'D', # 每天一切, 可选值有S/秒 M/分 H/小时 D/天 W0-W6/周(0=周一) midnight/如果没指定时间就默认在午夜 'interval': 1, 'backupCount': 5, 'formatter': 'simple', 'encoding': 'utf-8', }, 'console':{ 'level': 'DEBUG', 'filters': ['require_debug_true'], # 只有在Django debug为True时才在屏幕打印日志 'class': 'logging.StreamHandler', 'formatter': 'collect' } }, 'loggers': { 'django': { # django自己的,我们只是重写一下 'handlers': ['default', 'console'], 'level': 'DEBUG', 'propagate': False }, 'django.request': { # django自己的,我们只是重写一下 'handlers': ['request_handler'], 'level': 'DEBUG', 'propagate': False, }, 'scripts': { 'handlers': ['scprits_handler'], 'level': 'INFO', 'propagate': False }, 'sourceDns.webdns.views': { 'handlers': ['default', 'error'], 'level': 'DEBUG', 'propagate': True }, 'sourceDns.webdns.util':{ 'handlers': ['error'], 'level': 'ERROR', 'propagate': True } } }
# django系统会默认自动输出程序运行的错误日志到指定的log_name配置的文件路径下,但有时候我们捕获的异常就不会输出, # 这时需要我们手动的去输出一些日志,输出方法如下:获取要输出的日志名称创建logger对象,然后就可以调用内部方法输出。 # traceback 是用来获取异常的调用栈信息的对象 #日志手动输出: import logging import traceback # logger= logging.getLogger("log_name") logger = logging.getLogger("django.request") def test(): try: i = 8/0 except Exception: logger.error(traceback.format_exc()) # 仅在异常发生时输入简要的调用栈信息(format_exc输出简要的调用栈信息)
loggers的level与handlers中的level:需要先满足loggers的level要求,进而满足handlers的level要求的日志才会被打印。
在settings中指定根级url配置文件,对应的属性ROOT_URLCONF=’项目名.urls‘
urlpatterns:一个url实例的列表,全都url需要注册在根配置urls中
from django.conf.urls import include urlpatterns = [ url(r'^xxx/',include('app.urls')) ]
from django.urls import include, path urlpatterns = [ path('index/', views.index, name='main-view'), // 位置参数:bio/XXX/ 与顺序有关【参数个数必须和视图函数中参数个数一致】 path('bio/<username>/', views.bio, name='bio'), // 关键字参数:bio/username=XXX/ 与顺序无关【参数个数必须和视图函数中参数个数一致】 // P表示parmes path(r'^bio/(?P<username>w+)/$', views.bio, name='bio'), path('articles/<slug:title>/', views.article, name='article-detail'), path('articles/<slug:title>/<int:section>/', views.section, name='article-section'), path('weblog/', include('blog.urls')), ... ] // 前端使用 <a href="bio/{{ user.username }}/">aa</a>
前端访问使用后端指定的namespace+name锁定一个路由地址,而不在是固定写死的url,好处就是,如果修改了配置的url的话,无需动态修改页面中的url地址
// 根项目的urls from django.contrib import admin from django.urls import path, include urlpatterns = [ path(r'demo/', include('demo.urls'), namespace='demo'), path('admin/', admin.site.urls), ] // app的urls from django.conf.urls import url from demo import views urlpatterns = [ url(r'index/', views.index, name='index') ] // 使用反向解析要加app_name属性 app_name = 'demo' // 前端访问: <a href="{% url 'demo:index' %}">到index页面</a>
// 如果带参 urlpatterns = [ url(r'index/(d+)', views.index, name='index'), url(r'index/(?P<id>d+)', views.index, name='index') ] app_name = 'demo' // 使用规则: // {% url 'namespace.name' 参数1 参数2 ... %} // {% url 'namespace.name' key1=value1 key2=value2 key3=value3 %} // 带参数的传递一个id为10的,相当于index/10 <a href="{% url 'demo:index' 10 %}">到index页面</a> // 带参数的传递一个id为10的,相当于index/?id=10 <a href="{% url 'demo:index' id=10 %}">到index页面</a>
// 后端使用反向解析(一般重定向时使用): from django.urls import reverse def redir(request): //用法: reverse('namespace:name') url = reverse('demo:models') return HttpResponseRedirect(url) // 带参数的反向解析 // 位置参数:reverse('namespace:name',args=(value1,value2,value3)) // 关键字参数:reverse('namespace:name',kwargs={key1:value1,key2:value2})
function base view【基于函数的视图函数,我常用的】
CBV【更适合前后端分离时使用】
# urls urlpatterns = [ url(r'^getbooks/', views.BookController.as_view(msg='hello'), name='getbooks') ] # views from django.http import HttpResponse from django.views import View class BookController(View): msg = None def get(self, request): """ 访问后页面返回hello """ return HttpResponse(self.msg)
从自己这个对象中获取请求方法名字小写对应的属性,如果没找到,会给1一个默认http_method_not_allowed
如果请求方法不在我们的列表中,直接就是http_method_not_allowed
# urls urlpatterns = [ # as_view中参数即为TemplateView父类的TemplateResponseMixin url(r'^getbooks/', views.BookTemplateView.as_view(template_name='hello.html'), name='getbooks') ] # views class BookTemplateView(TemplateView): """ 继承自TemplateView,访问即可渲染html """ pass
# urls urlpatterns = [ url(r'^getbooks/', views.BookDataListView.as_view(), name='getbooks') ] # views from django.views.generic import ListView from book.models import Book class BookDataListView(ListView): model = Book template_name = 'book.html' # models class Book(models.Model): name = models.CharField(max_length=12) # templates {% for book in object_list %} <p>{{ book.name }}</p> {% endfor %}
// 类字典结构 不会拿出所有,只会拿最后一个 // { 'hobby' :['k1','k2','k3'] } request.GET.get('hobby') // 只能拿到hobby的k3 request.GET.getlist('hobby') // 可以拿到一个hobby的所有 // 内置属性: method、path、POST、GET、META(各种客户端的元信息) encoding、FILES、COOKIES、session、is_ajax()
// 内置属性 content 返回内容 charset 编码格式 status_code 响应状态码 content-type MIME类型 // 方法 init 初始化方法 write(xxx) 直接写出文本 flush() 冲刷缓冲区 set_cookie(key,value,max_age=None,exprise=None) delete_cookie(key) 删除cookie
return HttpResponseRedirect('/models/nomodel/') // 也可以简写成 return redirect('/models/nomodel/')
from django.http import HttpResponse,HttpResponseRedirect from django.urls import reverse from django.shortcuts import redirect def get_method(request): url = reverse('demo:index') return HttpResponseRedirect(url) //return redirect(url)
from django.http import JsonResponse def get_method(request): url = reverse('demo:index') return JsonResponse(dict) //也可以使用__init__(self,data)设置数据 Content-type是:application/json
// 加密 response.set_signed_cookie('name','maomao','slat')
// 登陆退出时使用,同时清空session和cookie request.session.flush() // 根据键获取会话的值 request.session.get(key,default) // 清楚所有会话信息,但是当前sessionid依然存在 .clear() // 删除会话 delete request['session_id'] // 获取session的key session.session_key // 设置session request.session['xxx'] = 'xx' // 数据存储到数据库中会进行编码十一点饿是Base64
// 服务端会话技术 // 自定义session // 如果Web页面开发中,使用起来和Session基本一致 // 如果使用在移动端或客户端开发中,通常以Json形式传输,需要移动端自己存储Token,需要获取 // Token关联数据的时候,主动传递Token // 步骤:1、在用户表中创建token字段,用于存储token // 2、用户登陆时,创建唯一Token值,存储在用户字段中 // 3、用户退出时,删除用户的Token值 // Cookie和Session,Token对比 // Cookie使用更简洁,服务器压力更小,数据不是很安全 // Session服务器要为啥Session,相对安全 // Token拥有Session的所有优点,自己维护略微麻烦,支持更多的终端
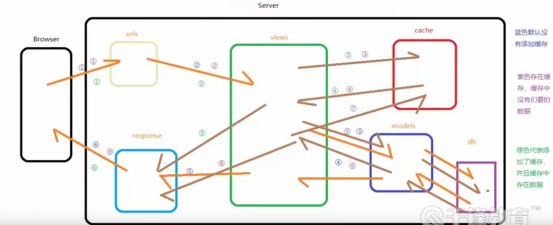
请求到视图后,视图内的orm直接查询数据库,然后将数据返回。
请求到视图后,先去缓存里找,找该请求(针对所有用户)或者请求的用户(针对当前用户)请求当前页面的数据,如果找到了,直接返回缓存里的数据。如果没找到在去查找数据库,查找完后进行两步操作:
基于内存的缓存,内存中的数据可能丢失,一旦服务器崩溃,数据就没了
对于一些交易类的抢购等,你要考虑使用基于内存的缓存带来的灾难,所以不去依赖基于内存的缓存作为您的唯一数据存储,Django内部支持多缓存框架的,对于交易类的你可以使用非内存缓存,对于普通数据类,你可以使用基于内存的缓存。
incr(key, value) key对应的值上添加 value
decr(key, value) key对应的值上减少value
// settings.py配置 CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.db.DatabaseCache', #'LOCATION': 'my_cache_table', 'LOCATION': 'django_cache', } } // 配置案例: // CACHES = { // 'default': { // 'BACKEND': 'django.core.cache.backends.db.DatabaseCache', // 'LOCATION': 'my_cache_table', // 'TIMEOUT': '60', // 'OPTIONS': { // 'MAX_ENTRIES': '300', // }, // 'KEY_PREFIX': 'suit', // 'VERSION': '1', // } // }
// 根据我们的配置去创建这么一张表,执行以下命令
python manage.py createcachetable
查看数据库表,发现多了一张django_cache表后,然后我们就可以直接使用缓存了。
from django.views.decorators.cache import cache_page @cache_page(60 * 3) // 缓存时间是3分钟 def cache_db(request): """ 缓存某个视图 :param request: :return: """ context = { 'data': ['news' + str(x) for x in range(10)] } sleep(5) return render(request, 'cache_page.html', context=context) def cache_db_by_hand(request): """ 手动缓存细粒度的数据 :param request: :return: """ cache_context = cache.get('cache_context') if cache_context: return render(request, 'cache_page.html', context=cache_context) context = { 'data': ['news' + str(x) for x in range(10)] } sleep(5) cache.set('cache_context', context, 60) return render(request, 'cache_page.html', context=context)
def cache_db_by_template(request): """ 前端模板缓存 :param request: :return: """ context = { 'data': ['news' + str(x) for x in range(10)] } # context['data'].append(10) sleep(5) return render(request, 'cache_page.html', context=context) // 前端模板缓存 {% load cache %} {% cache 60 ul %} {# ul只是一个名称,相当于cache中的键 #} <ul> {% for d in data %} <li>{{ d }}</li> {% endfor %} </ul> {% endcache %} // 访问页面你会发现页面没有展示10 // 然后立刻将代码10行的注释取消,reload项目, // 再次刷新页面访问还是没有10,然后去查看数据库超时时间,等超时后 // 再次刷新页面访问,此时出现了10这条数据。 // 注意页面缓存只是缓存片段,但是请求依旧是要到前端执行的,而且数据也被更新了! // 只是页面没更改过来而已: {% load cache %} {% cache 60 ul %} {# ul只是一个名称,相当于cache中的键 #} <ul> {% for d in data %} <li>{{ d }}</li> {% endfor %} </ul> {% endcache %} <hr> <ul> {% for d in data %} <li>{{ d }}</li> {% endfor %} </ul>
如上我们使用一段缓存一段不缓存,刷第一次展示结果是一样的,开启后台第十行注释,然后在刷:

此时缓存时间还没过,你会发现,模板缓存并不是真正的查询缓存,它并不能帮我们提示很高的效率,只是在渲染页面时快那么一丢丢。
参见:https://django-redis-chs.readthedocs.io/zh_CN/latest/#cache-backend
先安装好redis,Django使用redis 做缓存是第三方扩展了缓存接口实现的,有两个包可以选择,二者选其一吧
- 推荐使用,官网:https://django-redis-chs.readthedocs.io/zh_CN/latest/#django pip install django-redis - 官网:https://pypi.python.org/pypi/django-redis-cache/ // pip install django-redis-cache
CACHES = { "default": { "BACKEND": "django_redis.cache.RedisCache", "LOCATION": "redis://127.0.0.1:6379/1", "OPTIONS": { "CLIENT_CLASS": "django_redis.client.DefaultClient", } } }
# 启动redis liuwei@liuwei-virtual-machine / $ /usr/local/soft/redis-5.0.5/src/redis-server # 启动redis cli测试是否启动 liuwei@liuwei-virtual-machine ~ $ /usr/local/soft/redis-5.0.5/src/redis-cli 127.0.0.1:6379> ping PONG
// 测试redis缓存 @cache_page(60) def cache_db(request): context = { 'data': ['news' + str(x) for x in range(10)] } sleep(5) return render(request, 'cache_page.html', context=context)
- 选择1号库 select 1 - 查看所有的key keys * - 即可查看到所有缓存信息,缓存超时后,redis内的数据将被自动清除
127.0.0.1:6379[1]> select 1 127.0.0.1:6379[1]> keys * 1) ":1:views.decorators.cache.cache_header..cf4c4a88910e57cbd31a3b501aeeb91f.zh-hans" 2) ":1:views.decorators.cache.cache_page..GET.cf4c4a88910e57cbd31a3b501aeeb91f.d41d8cd98f00b204e9800998ecf8427e.zh-hans" # 超时后再查 127.0.0.1:6379[1]> keys * (empty list or set)
在middleware内创建自己的中间件拦截器(.py文件)
在创建的拦截器文件中定义一个拦截器类,该类继承自MiddlewareMixin,混合中间件
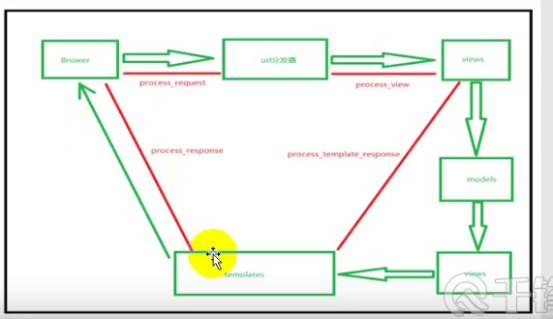
process_request:在浏览器的request请求到urls分发器之间的位置
process_view:在urls分发器和视图views之间
process_template_response:在views视图和templates之间
process_response:在templates和浏览器之间
如果其中某个中间件没有在切点处进行返回,则依次执行,否则的话之间返回,后面的中间件不在执行。
# 创建middleware文件夹,创建AOP的py文件,定义继承自MiddlewareMixin from django.http import HttpResponse from django.utils.deprecation import MiddlewareMixin class CountMiddleWare(MiddlewareMixin): def process_request(self, request): print(request) def process_view(self, request, methods, args, *kwargs): print('process_view:', request) print('process_view:', methods) print('process_view:', args) print('process_view:', *kwargs) def process_template_response(self, request, response): print("process_template_response:", request) return response def process_response(self, request, response): print('process_response:', request) print('process_response:', response) return response def process_exception(self, request, exception): # 只捕获views里抛出异常 print("process_exception:", request) print("process_exception:", exception) return HttpResponse("hello")
// 在settings中配置中间件 MIDDLEWARE = [ 'middleware.count.CountMiddleWare', 'django.middleware.security.SecurityMiddleware', ... ]
def index(request): return render(request, 'index.html') // 输出结果如下: process_request: <WSGIRequest: GET '/demo/index/'> process_view: <WSGIRequest: GET '/demo/index/'> process_view: <function index at 0x000001E7197FC488> process_view: () process_view: {} process_response: <WSGIRequest: GET '/demo/index/'> process_response: <HttpResponse status_code=200, "text/html; charset=utf-8">
你会发现,这个过程中并没有走我们的模板这一块,这是因为要想对视图进行增强(Advice),需要你views中返回的response对象具有一个render函数:
def index(request): resp = HttpResponse() context = {} def render(): return django.shortcuts.render(request, 'index.html', context=context) # 或者 # def render(): # template = get_template('index.html') # content = template.render(context, request) # return HttpResponse(content) resp.render = render return resp // 再次访问index,返回结果如下 process_request: <WSGIRequest: GET '/demo/index/'> process_view: <WSGIRequest: GET '/demo/index/'> process_view: <function index at 0x0000019534F6C488> process_view: () process_view: {} process_template_response: <WSGIRequest: GET '/demo/index/'> process_response: <WSGIRequest: GET '/demo/index/'> process_response: <HttpResponse status_code=200, "text/html; charset=utf-8">
def index(request): temp = 10 / 0 return render(request, 'index.html') // 访问:输出结果如下 process_request: <WSGIRequest: GET '/demo/index/'> process_view: <WSGIRequest: GET '/demo/index/'> process_view: <function index at 0x000001659D37C488> process_view: () process_view: {} process_exception: <WSGIRequest: GET '/demo/index/'> process_exception: division by zero process_response: <WSGIRequest: GET '/demo/index/'> process_response: <HttpResponse status_code=200, "text/html; charset=utf-8"> // 页面显示内容: division by zero
这里我们的process_view里并没有参数,参数需要从前端路由传递时才会打印出结果。
从每次访问的当前时间往前推算一分钟内是否访问超过了十次,如果超过就拒绝访问。
def process_request(self, request): ip = request.META.get("REMOTE_ADDR") date_list = cache.get(ip, []) # 先将超过当前时间的时间移除 now = time.time() while date_list and now - date_list[-1] > 60: date_list.pop(-1) if len(date_list) > 10: return HttpResponse("请求过于频繁,请稍后再试") date_list.insert(0, now) cache.set(ip, date_list, 60) return HttpResponse("这是news")
细想:一分钟访问10次也就相当于每6秒访问一次,那不就可以永久性的访问的?
@csrf_exempt def abc(request): // 表示豁免,就是说这个方法abc不进行csrf验证
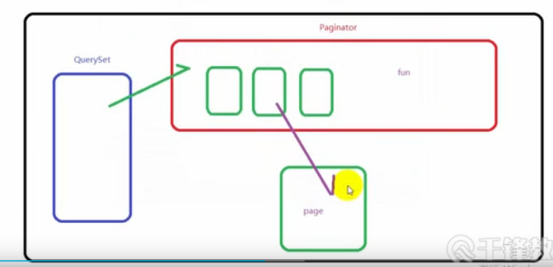
django提供了分页的工具,存在于diango.core中
- 创建分页对象 Paginator(数据集,每一页数据数) - 属性 count 对象总数 num_pages 页面总数 page_range 页码列表,从1开始 - 方法 page(整数) 获得一个page对象
django内置了邮件发送,除了发送普通文本外,还可以发送HTML元素。发送邮件需要指定发送方的邮箱地址(如果使用SMTP还需指定端口等)、接收方的邮箱地址(可以是多个)。
- 具体使用 - 在settings中配置邮件服务器地址,以及端口,以网易邮箱为例 EMAIL_HOST = 'smtp.163.com' EMAIL_PORT = 25 # 非ssl - 在settings中配置验证邮箱服务器的账号和授权码 EMAIL_HOST_USER = '18621651706@163.com' EMAIL_HOST_PASSWORD = 'liuwei123' # 这个授权码需要自己到网易上开通,在设置-POP3/SMTP/IMAP中-客户端授权密码,开启即可。授权密码仅具有有限权限的操作:发邮件 - 发送邮件 from django.core.mail import send_mail def send_email(request): """ 默认会读取settings中配置文件中设置的以上信息,发送邮件。 """ send_mail( subject='Hello', message='', # 发送普通文本 html_message='<h1>I love you!</h1>',# 发送HTML from_email='18621651706@163.com', recipient_list=['18621651706@163.com'], fail_silently=False, ) return HttpResponse('<h1>发送成功!</h1>')
邮件发送并不是你直接发送给接收方的,而是由你发送给服务器,然后服务器转发给接收方的,所以也就是上面为什么需要配置邮件服务器的地址和端口。
方案:在用户表中存储一个激活的字段,注册后默认为未激活,然后将用户的uuid【转为字符串之后的-uuid.hex】作为参数,拼接在激活的url之后。邮件的内容即为:点击该url地址,查询该用户将该用户激活。注意uuid.hex转为字符串后(移除了-),是没办法直接作为查询条件查询数据库的,而且激活也要有个时间限制,所以我们使用缓存,将uuid.hex作为键,uuid作为值,缓存时间为一天,当用户去点击激活时,就去缓存中查找uuid.hex对应的键,找到了就激活,没找到就提示激活邮件过期,重新发邮件激活。
当你在后台做完一件事之后,总要给用户一些提示,这种不跳转页面的提示我们可以直接在操作最后返回HttpResponse对象封装提示信息即可。但是如果在redirect之后呢?查阅官方的redirect方法发现它是可以传递一些参数的,也就是说这种情况下也不一定非要搭建一个消息框架。如果是为了将业务逻辑区分开呢?视图中返回的仅仅是和业务逻辑相关的数据,消息仅仅作为一种状态的话,单独的将消息封装起来是有必要的。那什么时候真实迫切的需要消息框架呢?如果服务器想主动给客户端推送信息怎么办?消息队列又是干啥的?
//在django项目中直接使用命令:
python manage.py shell
会启动一个shell的交互环境,这个交互环境不仅仅只是python环境还有我们当前项目的django环境,你可以直接在shell命令行闸中使用:
from xx import xx // 或调用当前django环境里的一些模块 Student.objects.all() // 可以很方便我们调试一些数据
DEBUG = False STATIC_URL = '/static/' # STATIC_ROOT = os.path.join(BASE_DIR, "static") STATICFILES_DIRS = [ os.path.join(BASE_DIR, "static"), os.path.join(BASE_DIR, "structfront/dist/static"), ] LANGUAGE_CODE = 'zh-hans' # 设置时区为中国的,不然存储在库中的日期会和当前日期有偏差 TIME_ZONE = 'Asia/Shanghai' USE_I18N = True # 关闭django默认时区,更改日期格式 USE_L10N = False DATE_FORMAT = 'Y-m-d' DATETIME_FORMAT = 'Y-m-d H:i:s' USE_TZ = False # 配置文件上传最大支持 DATA_UPLOAD_MAX_NUMBER_FIELDS = 10240
当debug=False时,Django将不再为您处理静态文件访问,启动项目会访问不到静态文件,你应该使用生产服务器(Nginx或Apache)去处理,如果你仍想使用本地服务器使用以下命令启动:
python manage.py runserver --insecure
- API https://django-debug-toolbar.readthedocs.io/en/latest/installation.html - 安装 pip install django-debug-toolbar - 使用的前置条件 INSTALLED_APPS = [ # ... 'django.contrib.staticfiles', # ... 'debug_toolbar', ] STATIC_URL = '/static/' - 配置根目录下二点urls from django.conf import settings from django.conf.urls import include, url # For django versions before 2.0 from django.urls import include, path # For django versions from 2.0 and up if settings.DEBUG: import debug_toolbar urlpatterns = [ path('__debug__/', include(debug_toolbar.urls)), # For django versions before 2.0: # url(r'^__debug__/', include(debug_toolbar.urls)), ] + urlpatterns - 启用middleware,推荐置前 MIDDLEWARE = [ # ... 'debug_toolbar.middleware.DebugToolbarMiddleware', # ... ] - settings中配置ip INTERNAL_IPS = [ # ... '127.0.0.1', # ... ]
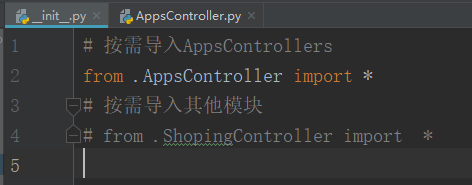
当一个项目很大时,我们把所有的内容都写着一个views或model中,这显然是不合理的,如果内容不太多也没必要单独用包拆分。python中也有包的概念,我们可以使用包的形式,将views中的内容拆分。然后使用插拔的方式,将urls中所需引入的views接口,引入在views包下的__init__.py文件中。
将views文件转为一个包文件:views右击-> Refactor -> Convert to python package
此时views文件原有的内容会全部移到__init__.py中,我们只需创建一些列controller来单独封装某个业务逻辑即可。
然后清空__init__.py,只在其中按需引入一些controller模块即可。