爬图片的demo,又是老朋友百度贴吧,只是加入了lxml清洗html,获得二级页面href,从二级页面爬img。之前的demo已经练习过lxml特别是etree用法,就不再赘述了。
代码如下:
# 情侣头像爬虫 import urllib.parse import urllib.request from lxml import etree class HeadPortraitSpider(object): def __init__(self): self.tiebaName = "情侣头像" self.beginPage = 1 self.endPage = 2 self.url = "http://tieba.baidu.com/f?" self.ua_header = {"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1 Trident/5.0;"} self.index = 1 # 构造url def tiebaSpider(self): print("开始爬取") for page in range(self.beginPage, self.endPage + 1): print("获取拼接网址") pn = (page - 1) * 50 wo = {'pn': pn, 'kw': self.tiebaName} word = urllib.parse.urlencode(wo) myurl = self.url + word self.loadPage(myurl) # 爬取页面内容 def loadPage(self, url): print("获取内容页") req = urllib.request.Request(url, headers=self.ua_header) data = urllib.request.urlopen(req).read() html = etree.HTML(data) links = html.xpath('//div[@class="threadlist_lz clearfix"]/div/a/@href') for link in links: link = "http://tieba.baidu.com" + link self.loadImages(link) # 爬取帖子详情页,获得图片的链接 def loadImages(self, link): print("获取图片链接") req = urllib.request.Request(link, headers=self.ua_header) data = urllib.request.urlopen(req).read() html = etree.HTML(data) links = html.xpath('//img[@class="BDE_Image"]/@src') for link in links: self.writeImages(link) # 通过图片所在链接,爬取图片并保存图片到本地: def writeImages(self, images_Link): print("正在存储图片:", self.index, "....") image = urllib.request.urlopen(images_Link).read() # 保存图片到本地 file = open("H:\情侣头像\" + str(self.index) + ".jpg", "wb+") file.write(image) file.close() self.index += 1 if __name__ == '__main__': mySpider = HeadPortraitSpider() mySpider.tiebaSpider()
可以再复习巩固一下urllib创建Request对象,加载urlopen,拼接url的部分知识。
我们通过lxml.etree.HTML()方法,xpath通过访问标签属性获得href地址列表,类型是lxml.etree._ElementUnicodeResult 的list
当然这个属性值列表可以强制转换为str类型,但在某些网站的源码中,css编码加密了标签内属性,所以我们想要获取具体属性值的时候,要调试一下,能否正常解码
当然我是想把小标题取出来单做文件夹,每个帖子的图分单一个文件夹,但是试了几次,都发现文件写入的时候是乱码的,无法正常显示中文。
当然,查阅css文件,可以找出具体加密规律
但是我们要的信息主体是图片img,所以这个东西现在就先放一下,不纠结。
运行状况:
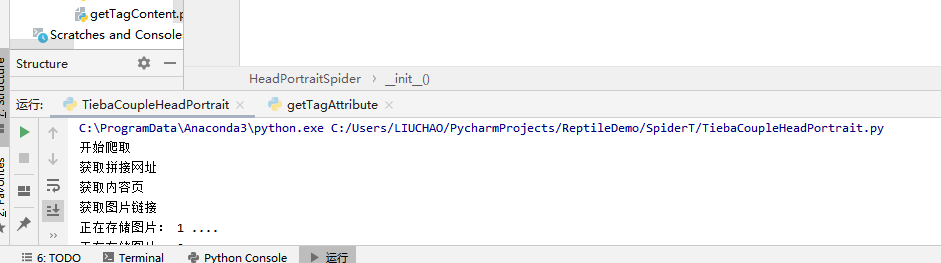

检查一下磁盘写入:
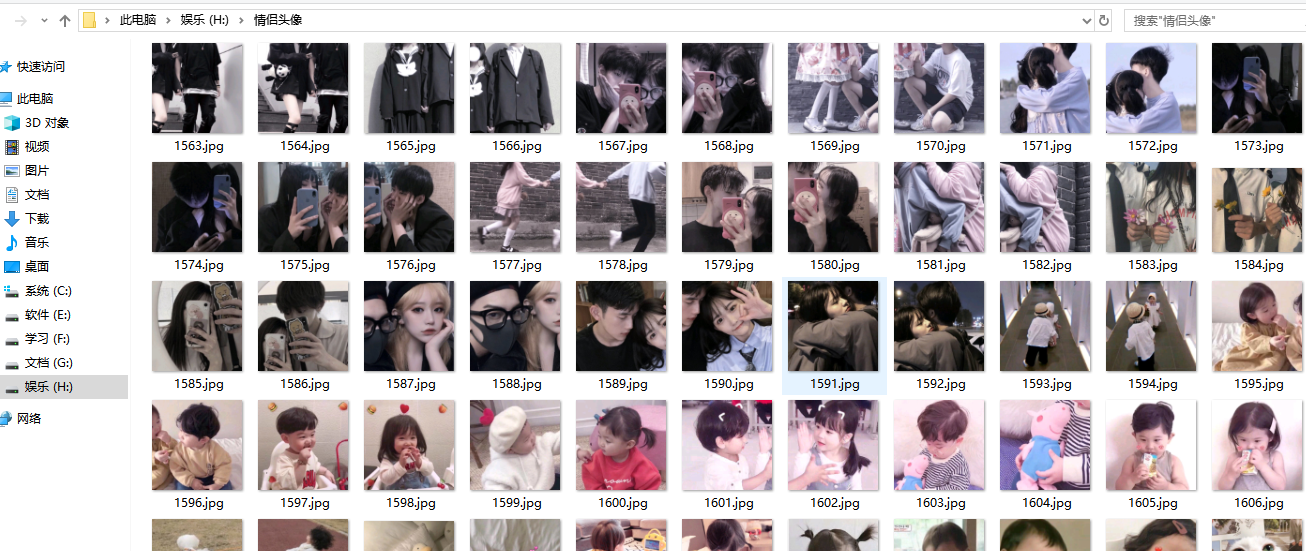
对比贴吧帖子内的情侣头像图,没有错误
打开一个看看:
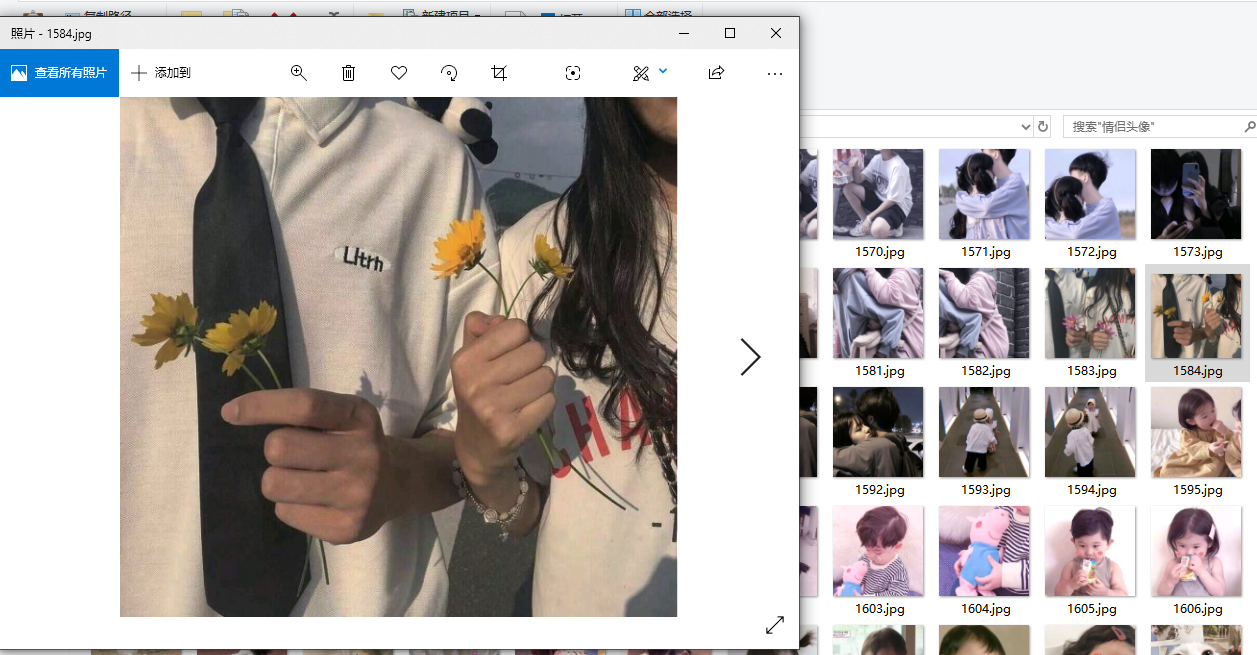
ok 好像发现了什么不得了的东西,想起来原谅宝的信息来源 (大草) 。。。。。