前言
数组和链表是两种数据结构,数组非常简单易用但是它有两个非常大的缺点,一个是数组一旦创建无法扩展,另一个则是数组的查找和删除的速度很慢.
链表改善了一些数组的缺点,但是同样的链表自身也存在一些自己的缺点.
本篇博客将为大家介绍一下这数组和链表特点及各自的优缺点.
阅读前的准备工作
大O表示法,一种粗略的评价计算机算法效率的方法.后面的内容会用到表示效率的方法.
1. 数组
我们按数组中的数组是否排序对数组进行划分,将数组分为无序数组和有序数组.无序数组中的数组是无序的,而有序数组中的数据则是升序或者降序排序的.
1.1 无序数组
因为无序数组中的数据是无序的,往数组中添加数据时不用进行比较和移动数据,所以往无序数组里面添加数据很快.无论是添加第一个数据还是第一万个数据所需的时间是相同的,效率为O(1).
至于查找和删除速度就没有那么快了,以数组中有一万个数据项为例,最少需要比较1次,最多则需要比较一万次,平均下来需要比较5000次,即N/2次比较,N代表数据量,大O表示法中常数可以忽略,所以效率为O(N).
结论:
- 插入很快,因为总是将数据插入到数组的空余位置.
- 查找和删除很慢,假设数组的长度为N,那么平均的查找/删除的比较次数为N/2,并且还需要移动数据.
1.2 有序数组
无序数组中存放的数据是无序的,有序数组里面存放的数据则是有序的(有可能是升序有可能是降序).
因为有序数组中的数据是按升序/降序排列的,所以插入的时候需要进行排序并且移动数据项,所有有序数组的插入速度比无序数组慢. 效率为O(N).
删除速度和无序数组一样慢 效率为O(N).
有序数组的查找速度要比无序数组快,这是因为使用了一个叫做二分查找的算法.
二分查找: 二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列.
有一个关于二分查找的形象类比 -> 猜数游戏
假设要在0-100之间猜一个数,那么你第一个要猜的数字就是100的一半50的时候,你的朋友会告诉你这个数字比要猜的数字是大还是小,如果比数字大,你接下来要猜的数字就是50的一半25,你的朋友说比这个数字要大,那么你下面要猜的数字就是25-50中间的那个数37,以此类推...

使用二分查找可极大的提高查找的效率,假设一个有序数组有十亿个数据,那么查找到所需的数字,最多只需比较30次.

有序数组使用二分查找的效率为O(logN).有序数组也可以通过二分查找来新增和删除数据以提高效率,但是依然需要在新增/删除后移动数据项,所以效率依然会有影响.
总结:
- 有序数组的查找速度比无序数组高,效率为O(logN)
- 有序数组的删除和新增速度很慢,效率为O(N)
1.3 数组总结
数组虽然简单易用,但是数组有两个致命的缺点:
- 数组存储的数量有限,创建的过大浪费资源,创建的过小溢出
- 数组的效率比其他数据结构低
- 无序数组插入效率为O(1)时间,但是查找花费O(N)时间
- 有序数组查找花费O(logN)时间,插入花费O(N)时间
- 删除需要移动平均半数的数据项,所以删除都是O(N)的时间
2. 链表
数组一经创建大小就固定住了,无法修改,链表在这方面做出了改善,只要内存够用就可以无限制的扩大.
链表是继数组之后应用最广泛的数据结构.
2.1 链表的特点
链表为什么叫链表呢? 因为它保存数据的方式就像一条锁链

链表保存数据的方式很像上面的这一条锁链,每一块锁链就是一个链节点,链节点保存着自己的数据同时通过自己的next()方法指向下一个链节点. 链表通过链节点不断地调用next()方法就可以遍历链表中的所有数据.
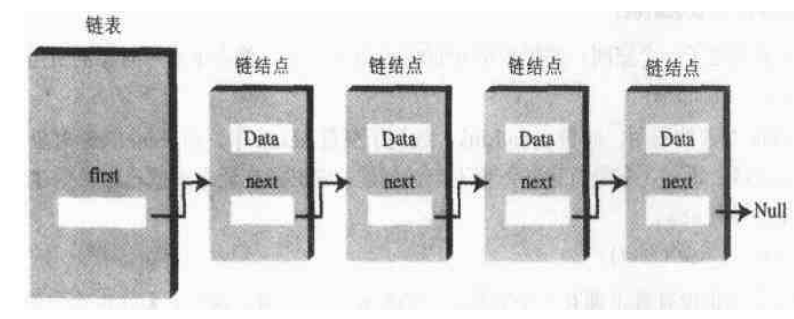
在链表中,每个数据项都被包含在"链节点"(link)中,一个链结点是某个类的对象,这个类可以叫做Link.因为一个链表中有许多类似的链结点,所以有必要用一个不同于链表的类来表达链结点.
每个Link对象中都包含一个对下一个链结点引用的字段(通常叫做next).
链表本身的对象中有一个字段指向对第一个链结点的引用.
数据与链表查找数据的区别: 在数组中查找数据就像在一个大仓库里面一样,一号房间没有,我们去二号房间,二号房间没有我们去三号房间,以此类推.. 按照地址找完所有房间就可以了.
而在链表中查找数据就像单线汇报的地下工作者,你是孤狼你想要汇报点情报给你的顶级上司毒蜂,但是你必须先报告给你的接头人猪刚鬣,猪刚鬣在报告给它的单线接头人土行孙,最后由土行孙报告给毒蜂.只能一个找一个,这样最终完成任务.
2.2 Java代码
链节点类:
/**
* @author liuboren
* @Title: 链节点
* @Description:
* @date 2019/11/20 19:30
*/
public class Link {
// 保存的数据
public int data;
// 指向的下一个链节点
public Link nextLink;
public Link(int data) {
this.data = data;
}
public int getData() {
return data;
}
public void setData(int data) {
this.data = data;
}
public Link getNextLink() {
return nextLink;
}
public void setNextLink(Link nextLink) {
this.nextLink = nextLink;
}
}
链表类
/**
* @author liuboren
* @Title: 链表类
* @Description:
* @date 2019/11/20 19:31
*/
public class LinkList {
private Link first;
public LinkList() {
first = null;
}
// 新增链节点方法
public void insertFirst(int data) {
Link link = new Link(data);
link.setNextLink(first);
first = link;
}
}
在新增节点的时候,新增的link的next方法指向原来的first节点,并将链表类的first指向新增的节点.
2.4 其他链表
刚刚介绍的链表是单向链表,只能从后往前遍历,其他的链表还有双端链表、双向链表、有序链表.
再简单介绍一下双端链表吧.
双端链表就是在单向链表的基础上,新增一个成员变量指向链表的最后一个对象.
双端链表代码:
/**
* @author liuboren
* @Title: 链表类
* @Description:
* @date 2019/11/20 19:31
*/
public class LinkList {
private Link first;
private Link last;
public LinkList() {
first = null;
}
public boolean isEmpty() {
return first == null;
}
// 新增链节点方法
public void insertFirst(int data) {
Link newLink = new Link(data);
newLink.setNextLink(first);
if (isEmpty()) {
last = newLink;
}
first = newLink;
}
}
双向链表则是可以从first和last两个方向进行遍历,有序链表的数据都是按照关键字的顺序排列的,本文不再展开了.
2.5 链表的效率
链表的效率:
- 在表头插入和删除速度都很快,花费O(1)的时间.
- 平均起来,查找&删除&插入在指定链节点后面都需要搜索一半的链节点需要O(N)次比较,虽然数组也需要O(N)次比较,但是链表让然要快一些,因为不需要移动数据(只需要改变他们的引用)
3. 总结
链表解决了数组大小不能扩展的问题,但是链表自身依然存在一些问题(在链表的链节点后面查找&删除&插入的效率不高),那么有没有一种数据结构即拥有二者的优点又改善了二者的缺点呢,答案是肯定的,下篇博客将为您介绍这种优秀的数据结构,敬请期待.