概要图
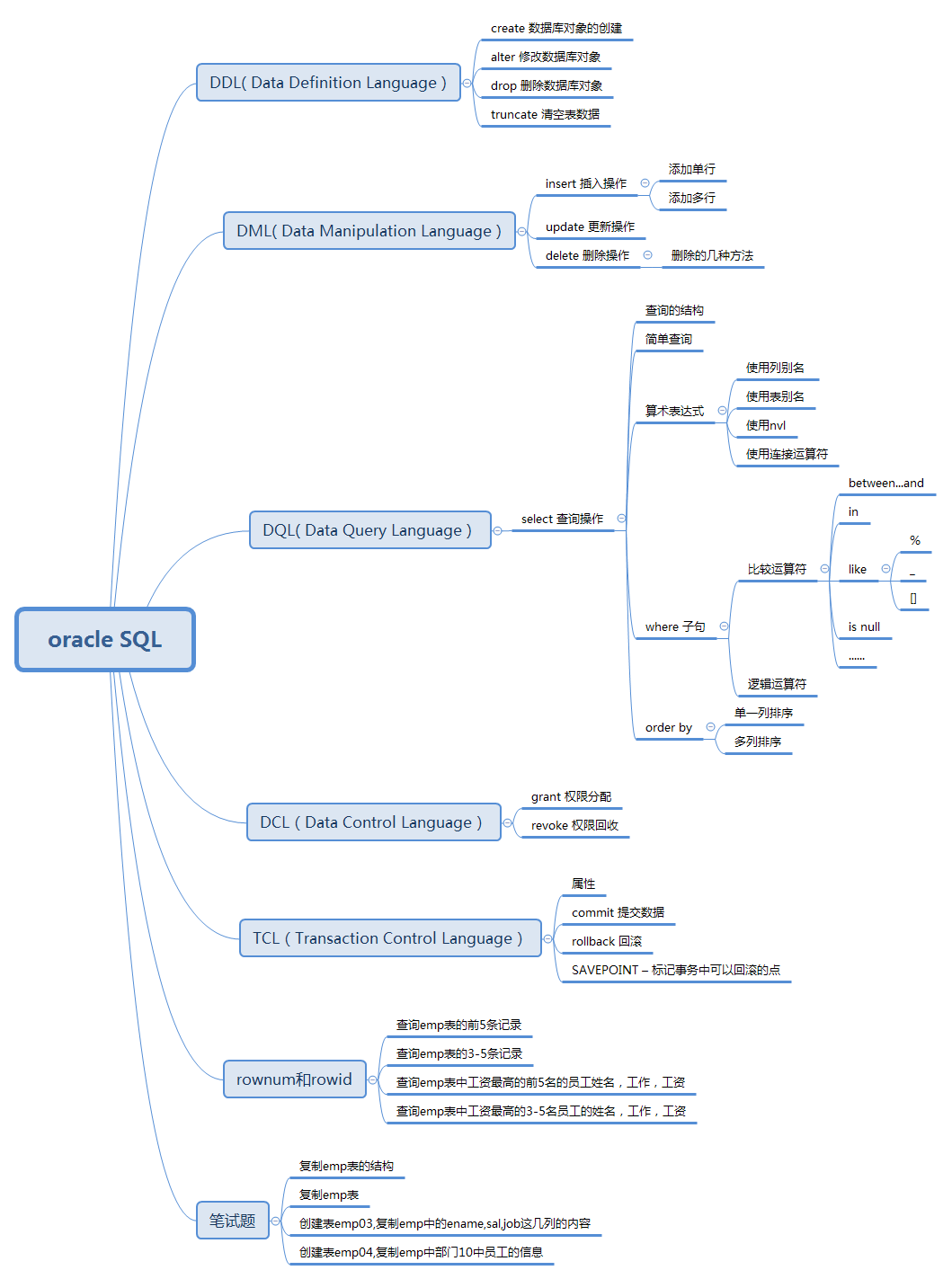
一 概述
SQL:Structured Query Language,结构化查询语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
结构化查询语言包含:数据定义语言DDL、数据操纵语言DML、数据查询语言DQL、数据控制语言和事务控制语言。
1.1 数据定义语言(DDL)
数据定义语言 DDL( Data Definition Language ) , 是 SQL 语言集中负责数据结构定义及数据库对象定义的语言 , 主要有 create、alter、drop 和 truncate 四种常用语句。对数据结构起作用。
create 数据库对象的创建 create user/create tablespace/create table/create sequence
alter 修改数据库对象
drop 删除数据库对象
truncate 清空表数据
注意:DDL不需要提交,系统自动提交 可与事务隙比较
1.2 数据操纵语言(DML)
数据操纵语言 DML( Data Manipulation Language ) , 用户通过它可以实现对数据表的基本操作 ,即对表中数据的增、删、改。DML 对数据起作用。
insert 插入操作
update 更新操作
delete 删除操作
1.3 数据查询语言(DQL)
数据查询语言 DQL( Data Query Language ) , 主要通过它实现对数据的查询操作。
select 查询操作
1.4 数据控制语言(DCL)
数据控制语言DCL(Data Control Language),用来控制存取许可、存取权限等。
grant 权限分配
revoke 权限回收
1.5 事务控制语言(TCL)@
事务控制语言TCL(Transaction Control Language)是用来对 DML操作进行确认的。
commit 提交数据
rollback 回滚
注意:事务主要是对DML操作的
二 数据操纵语言(DML)
2.1 添加数据(insert)
语法:
insert into 表名 (列名1,列名2…) values (值1,值2…); insert into 表名values (值1,值2,值3…]);
注意事项:
1、插入的数据应与字段的数据类型相同。
2、数据的大小应在列的规定范围内,例如:不能将一个长度为80的字符串加入到长度为40的列中。
3、在values中列出的数据位置必须与被加入的列的排列位置相对应。
4、字符和日期型数据应包含在单引号中。 例(date '1998-02-06'),(06-02-1998),(todate('1998-02-06',yyyy-mm-dd))
insert into emp01 values(1001,'shelly','MANAGER',7839,date'1989-12-08',3000,NULL,10); --使用默认日期格式 insert into emp01 values(1001,'shelly','MANAGER',7839,'08-12月-1989',3000,NULL,10); --使用to_date将字符串转换为日期 insert into emp01 values(1001,'shelly','MANAGER',7839,to_date('1989-12-08','yyyy-mm-dd'),3000,NULL,10);
5、插入空值,’’或insert into table values(null);
6、给表的所有列添加数据时,可以不带列名直接添加values值。
7、每次插入一行数据,不能只插入半行或者几列数据;插入的数据是否有效将按照整行的数据完整性的要求来检验。
示例:
向students添加数据
SQL>insert into students (id,name,sex,birthday,score) values(1,'张三','男','11-11月-01',70);
SQL>insert into students values(2,'李四','男','11-11月-02',88);
SQL>insert into students values(3,'王五','女','11-11月-03',78);
--(1)insert --创建一张emp01表,复制emp表的结构。 create table emp01 as select * from emp where 1=2; --往emp01中插入记录 --给全部字段插入值 insert into emp01 values (1001,'shelly','MANAGER',7839,date'1989-12-08',3000,NULL,10); --给其中几个字段插入值,没有显示的字段默认null insert into emp01(empno,ename,sal,job,deptno)values (1002,'ellen',4000,'salseman',20); --问题:从emp表中复制20部门员工信息,放入到emp01表中 insert into emp01 select * from emp where deptno=20; --问题:往emp01表中插入一条ellen的记录,其余内容跟emp01表一致,empno在原来的基础上加1000 insert into emp01(empno,ename,job,sal,deptno) select empno+1000,ename,job,5000,deptno from emp01 where ename='ellen'; insert into emp01(empno,ename,job,sal,deptno) select 3001,'LILY','ANALYST',3000,30 from dual; --等价于: insert into emp01(empno,ename,job,sal,deptno)values (3001,'LILY','ANALYST',3000,30);
插入多行数据
语法:
INSERT INTO <表名>(列名) SELECT <列名> FROM <源表名> 或 INSERT INTO <表名>(列名) SELECT <列名> from dual UNION SELECT <列名> from dual UNION ……
示例:
create table grade1 (gradeid number, gradename varchar2(20));
insert into grade (gradeid, gradename)
select 6, '六年级' from dual union
select 7, '七年级' from dual union
select 8, '八年级' from dual;
--问题:一条insert语句插入多条记录 insert into emp01(empno,ename,sal,job) select 9999,'LILEI',3500,'MANAGER' from dual union select 9998,'Lucy',4500,'MANAGER' from dual union select 9997,'hanmeimei',5500,'MANAGER' from dual --union:Oracle的集合运算并运算,求并集,使用的时候会去重 --union all:求并集运算,不去重 select 9999,'LILEI',3500,'MANAGER' from dual union select 9999,'LILEI',3500,'MANAGER' from dual union select 9999,'LILEI',3500,'MANAGER' from dual select 9999,'LILEI',3500,'MANAGER' from dual union all select 9999,'LILEI',3500,'MANAGER' from dual union all select 9999,'LILEI',3500,'MANAGER' from dual
注意:
- union 的集合运算的并运算
- union all 求并集运算
union 会去重复,union all 不去重复
2.2 修改数据(update)
语法:
update tableName
set 字段1=值1,字段2=值2,…字段n=值n
where 条件;
注意事项:
1、update语法可以用新值更新原有表行中的各列;
2、set子句指示要修改哪些列;
3、where子句指定应更新哪些行。如没有where子句,则更新所有的行。(特别小心)
示例:
对students中的数据进行修改
ü 将张三的性别改成女
SQL>update students set sex='女' where name='张三';
u 把张三的年级改为2
SQL>update students set gradeid=2 where name='张三';
u 把所有人的成绩都提高10%
SQL>update students set score = score *1.1;
练习:
u 将所有学生分数修改为50分
SQL>update students set score=50;
u 将姓名为'张三'的学生分数修改为30
SQL>update students set score=30 where name='张三';
u 将'李四'的分数在原有基础上增加10分
SQL>update students set score = score +10 where name='李四';
u 将没分的同学的分数改成10分
SQL>update students set score =10 where score is null;
特别注意:当修改空记录时应用is null而不能使用=null或=''
--问题:更新emp01表中员工工资,如果工资小于1500,那么给员工涨1000; update emp01 set sal=sal+1000 where sal<1500; --(4)select: --(1)查询表中所有的记录,*在这里代表emp01表中的所有字段 select * from emp01; select empno,ename,job,mgr,hiredate,sal,comm,deptno from emp01; --(2)查询emp01表中员工的姓名,工资,奖金,部门编号 select ename,sal,comm,deptno from emp01; --(3)查询emp01表中部门30中员工的姓名,工资,奖金,部门编号 select ename,sal,comm,deptno from emp01 where deptno=30;
2.3 删除数据(delete)
基本语法:
delete from 表名 [where条件表达式];
例子
--(2)delete: --删除表中所有记录 delete from emp01; --删除表中符合条件的记录 --问题:删除emp01表中部门编号为10的员工的信息 delete from emp01 where deptno=10;
注意事项:
1、如果不使用where子句,将删除表中所有的数据。(特别注意)
2、delete语句不能删除某一列的值(可使用update)
3、使用delete语句仅删除记录,不删除表本身。如要删除表,使用drop table语句。
4、同insert和update一样,从一个表中删除记录将引起其它表的参照完整性问题(主外键关联关系),在修改数据库数据时,头脑中应始终不要忘记这个潜在的问题。
删除的几种方法比较:
delete from student where xh='A001';
删除一条记录
delete from 表名;
删除所有记录,表结构还在,写日志,可以恢复的,速度慢
truncate table 表名;
删除表中的所有记录,表结构还在,不写日志,无法找回删除的记录,速度快。
drop table 表名;
删除表的结构和数据
三 事务控制语言(TCL)
3.1 基本概念
事务是对数据库操作的逻辑单位,在一个事务中可以包含一条或多条DML (数据操纵语言)、DDL (数据定义语言)和DCL (数据控制语言)语句,这些语句组成一个逻辑整体。
事务具有四个属性,这四个属性的英文单词首字母合在一起就是ACID 。这四个属性是:
原子性( Atomicity ):事务要么全部执行,要么全部不执行,不允许部分执行。
一致性( Consistency ):事务把数据库从一个一致状态带入另一个一致状态。
独立性( Isolation ):一个事务的执行不受其他事务的影响。
持续性( Durability ):一旦事务提交,就永久有效,不受关机等情况的影响。
一个事务中可以包含多条DML语句,或者包含一条DDL语句,或者包含一条DCL语句。
用于事务控制的语句有:
COMMIT - 提交并结束事务处理
ROLLBACK - 撤销事务中已完成的工作
SAVEPOINT – 标记事务中可以回滚的点
3.2 事务控制
对事务的操作有两个:
提交( COMMIT )- 提交并结束事务处理
回滚( ROLLBACK )-撤销事务中已完成的工作
事务开始于第一条SQL语句,在下列之一情况下结束:
(1)遇到COMMIT或ROLLBACK 命令。
(2)遇到一条DDL或者DCL命令。
(3)系统发生错误、退出或者崩溃。
3.2.1 commit操作
示例:银行转账,小明给小红转账500元。
update custom set balance=balance-500 where name=’小明’;
update custom set balance=balance+500 where name=’小红’;
commit;
3.2.2 rollback操作
回滚事务有两种方式:完全回滚,即回滚到事务的开始;部分回滚事务,即可以将事务有选择地回滚到中间的某个点。部分回滚是通过设置保存点( SAVEPOINT )来实现的。
--部分回滚
…
savepoint 保存点名称;//设置保存点
…
rollback to [savepoint] 保存点名称;//回滚到保存点
特别注意:设置保存点及回滚操作是配合delete语句使用,用来找回使用delete删除的数据。而通过truncate删除的表数据是无法通过此方法找回的。
建议:
在使用delete删除表数据前使用savepoint设置保存点,防止数据误删除。
例子:
SQL> UPDATE students SET score = score + 5 WHERE score <= 30;
SQL> SAVEPOINT mark1;
SQL> DELETE FROM students WHERE id= ‘100001’;
SQL> SAVEPOINT mark2;
SQL> ROLLBACK TO mark1;
SQL> COMMIT;
--创建保存点: savepoint mark1 update emp01 set sal=sal+500 where comm is null; rollback to mark1;--回滚到mark1保存点 commit; --提交
PS:(1)在一个事务中可以保存多个保存点。
(2)一旦回退后,该保存点就消失了,不能再次回退。
(3)设置保存点是有资源开销的。
(4)一旦提交了事务,则不能回退到任何保存点。
3.2.3 事务隔离级别(了解)
数据库的并发操作会带来以下问题:
(1)脏读:当一个事务读取另外一个事务尚未提交的修改时,产生脏读。(在oracle中,没有脏读)
(2)不可重复读:同一查询在同一个事务中,多次执行,由于其他提交事务所做的修改或删除,每次返回不同的结果集。
(3)幻读:同一查询在同一事务中多次执行,由于其他提交事务所做的插入操作,每次返回不同的结果集,这个现象称为幻读。
oracle有三种事务隔离级别:
(1)read commited:默认的事务隔离级别,保证不会出现脏读,但可能出现不可重复读和幻读
(2)serializable:可以保证不出现脏读、不可重复读、幻读
(3)read-only:可以保证不出现脏读、不可重复读、幻读,只能进行读操作,不能进行修改、删除、插入操作。
设置当前事务的隔离级别
set transaction isolation level read committed;(默认)
set transaction isolation level serializable;
set transaction read only;
设置整个会话的隔离级别
alter session set isolation level read committed;
alter session set isolation level serializable;
四 数据查询语言(DQL)
主要用于按照指定条件查询现有表中的数据信息。
语法:
--简单
select 列名 from 表名 [where 条件];
--复杂
select 列 from 表名 where 条件 group by (列) having 条件 order by 列
scott用户存在的几张表(emp,dept,salgrade)为大家演示之后的select语句,select语句在软件编程中非常的有用。
1)EMP员工表
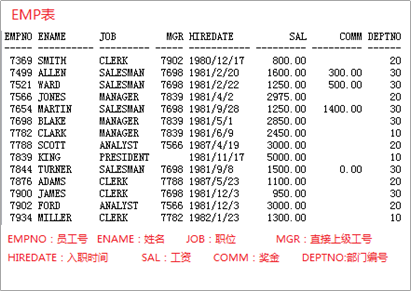
2)DEPT部门表

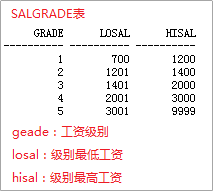
3)SALGRADE工资级别表
4.1 简单查询
u 查询所有列
select * from tableName;
查询所有员工信息
select * from emp;
u 查询指定列
select col1,col2,… from tableName;
查询所有员工的员工号,姓名和工资
select empno,ename,sal from emp;
u 去重查询(使用关键字distinct)
查询所有员工所在的部门号。
select distinct deptno from emp;
4.2 使用算术表达式
算术运算符用于执行数值计算,可以在SQL语句中使用算术表达式,算术表达式由数值数据类型的列名、数值常量和连接它们的算术操作符组成。
算术操作符包括加(+)、减(-)、乘(*)、除(/)。
查询员工的年薪
select empno,ename,sal*12 from emp;
4.2.1使用列的别名
select ename "姓名",sal*13+nvl(comm,0)*13 "年收入" from emp;
select ename 姓名,sal*13+nvl(comm,0)*13 年收入 from emp;
select ename as "姓名",sal*13+nvl(comm,0)*13 as "年收入" from emp;
PS:1 oracle在使用别名时,可以用双引号、不使用、使用as来表明别名。但不能使用单引号。
2 有一种情况双引号不能省略:别名中有空格
select 'Dear '||ename "姓 名" from emp;
4.2.2 使用表别名
表别名
--查询10部门的员工的姓名工资和工作
select ename,sal,job from emp where deptno=10;
--给emp表一个别名 语法: 表名 表别名
select e.ename,e.sal,e.job from emp e where e.deptno=10;
--规则:一旦给了表别名之后,所有字段的使用都要:表别名.字段名
--注意:表别名没有as
4.2.3 使用nvl函数来处理null
nvl是oracle提供的函数,是用于处理null值使用的。
语法:nvl(值1,值2)
解释:nvl值1为null时则取值2,值1不为null时则取值1原值。
select empno,ename,(sal+nvl(comm,0))*13 from emp;
4.2.4 使用连接运算符
连接运算符(||),用于将多个字符串或数据值合并成一个字符串
select ename||'年收入'||(sal*13+nvl(comm,0)*13) "雇员的年收入" from emp;
select ename,'部门编号是'||deptno 部门编号 from emp;
--连接运算符:|| --问题:查询emp01中员工姓名,在员工姓名前面加上dear select 'Dear '||ename from emp01; --问题:查询每个员工的工资,显示为:ellen的工资是:800 select ename||'的工资是:'||sal from emp01;
4.3 使用where子句
如果希望只查询一部分行,那么可以通过WHERE子句指定条件。WHERE子句的作用是通过指定条件,使SELECT语句仅仅查询符合条件的行。
在更多情况下,都需要根据指定的条件对数据进行查询。
WHERE子句指定的条件是一个关系表达式,如果关系表达式的结果为真,则条件成立,否则条件不成立。
关系表达式用于比较两个表达式的大小,或者进行模糊匹配,或者将一个表达式的值与一个集合中的元素进行匹配。
比较运算符
比较运算符用于比较两个表达式的值,操作符包括 =、!=、<、>、<=、>=、BETWEEN…AND、IN、LIKE 和 IS NULL等
(1)查询工资高于3000的员工信息。
select * from emp where sal>3000;
(2)查询部门号是10的员工信息。
select * from emp where deptno=10;
(3)查询工资在2000至3000之间的员工
select * from emp where sal between 2000 and 3000;
说明:between是指定区间内取值,如:between 2000 and 2500,取2000至2500内的值,同时包含2000和2500
--问题:查询工资大于3000的员工的信息 select * from emp01 where sal>3000; --问题:查询工资小于2000的员工的信息 select * from emp01 where sal<2000; --问题:查询部门编号不为20的员工的信息 select * from emp where deptno<>20; select * from emp where deptno!=20; --is null用来做空值的比较 --问题:查询奖金为空的员工的信息 select * from emp where comm is null; --问题:查询奖金不为空的员工的信息 select * from emp where comm is not null; --注意:0和null不是一回事 --between...and...:包含边界 --问题:查询工资在2000-5000之间的员工的信息 select * from emp where sal between 2000 and 5000; --等价于: select * from emp where sal>=2000 and sal<=5000; --in:后面加的是一个集合 --问题:查询部门10或部门20中的员工的信息 select * from emp where deptno in(10,20); select * from emp where deptno=10 or deptno=20;
like模糊查询
在模糊查询中需要使用通配符。
|
通配符 |
说明 |
示例 |
|
_ |
一个字符 |
ename like ‘WAR_’ |
|
%
[] |
任意长度的字符串 表示匹配[]任意一个字符 |
ename like ‘S%’
ename like [ab] |
查询员工姓名以S开头的员工信息
select * from emp where ename like 'S%';
查询员工姓名第三个字符为大写O的所有员工的姓名和工资
select ename,sal from emp where ename like '__O%';
--问题:查询姓名中带有LLEN的员工信息 select * from emp where ename like '%LLEN%'; --问题:查询姓名以A开头,以N结束的员工的信息; select * from emp where ename like 'A%N'; --查询员工姓名长度为5的员工的信息 select * from emp where ename like '_ _ _ _ _';
在where条件中使用in
in运算符用来与一个集合中的元素进行比较。
查询部门10,20的员工姓名及工资。
select ename,sal from emp where deptno in (10,20);
在where条件中使用is null
在Oracle中使用IS NULL和IS NOT NULL来判断是否为空了。
查询没有上级的员工信息
select * from emp where mgr is null;
逻辑运算符
逻辑运算符用于组合多个比较运算的结果以生成一个或真或假的结果。逻辑操作符包括与(AND)、或(OR)和非(NOT)。
查询工资在2000至3000之间的员工信息
select * from emp where sal>=2000 and sal<=3000;
查询工资低于3000或是岗位为manager的雇员,同时还要满足他们的姓名首写字母为大写的J
select * from emp where (sal<3000 or job='MANAGER') and (ename like 'J%');
运算符的优先级
--算术运算符>连接运算符>比较运算符>not>and>or
4.4 使用order by排序查询
Oracle中使用order by子句,对查询结果按照某一列进行排序查询,排序结果有升序(asc)和降序(desc)之分。默认排序结果是升序,即从小到大排序。
单一列排序
按照工资的从低到高的顺序显示员工信息
select * from emp order by sal asc;
PS:asc写或不写都是升序排序即从小到大排序,desc则是降序排序从大到小排序。
多列排序
按照部门号升序而雇员的入职时间降序排列
select * from emp order by deptno,hiredate desc;
使用列的别名排序
select ename,sal*12 年薪 from emp order by 年薪 asc;
五 rownum和rowid
rownum常用,rowid不常用。
rownum相当于是给查询结果的每一行编一个序号,并没有存储在emp表中
rownum主要是用来写分页过程select rownum,e.* from emp e;
select rownum, e.* from emp e where deptno=30; --问题1:查询emp表的前5条记录 select * from emp where rownum<=5; --问题2:查询emp表的3-5条记录 select * from (select rownum ro,e.* from emp e) where ro>=3 and ro<=5; --问题3:查询emp表中工资最高的前5名的员工姓名,工作,工资 select * from (select ename,job,sal from emp order by sal desc)x where rownum<=5; --问题4:查询emp表中工资最高的3-5名员工的姓名,工作,工资 --分析:(1)select ename,job,sal from emp order by sal desc ---x --(2)取x得3-5行:select * from(select rownum ro,x.* from x) where ro>=3 and ro<=5; --(3)替换的到结果:
先排序在后取
select * from (select rownum ro,x.* from (select ename,job,sal from emp order by sal desc)x) where ro>=3 and ro<=5; --总结:(1)可以用rownum<2,rownum<=2,rownum=1 --不能用rownum>2或者是rownum>=2,rownum=2; --rowid:表示的是记录的物理地址,唯一的且固定的。 select rowid,e.* from emp e;
笔试题
(1) 复制emp表的结构
create table emp01 as select * from emp where 1=2;
(2) 复制emp表
Create table emp02 as select * from emp;
(3) 扩展:创建表emp03,复制emp中的ename,sal,job这几列的内容
Create table emp03(name,sal,job) as select ename,sal,job from emp;
(4) 扩展:创建表emp04,复制emp中部门10中员工的信息
Create table emp04 as select * from emp where deptno=10;
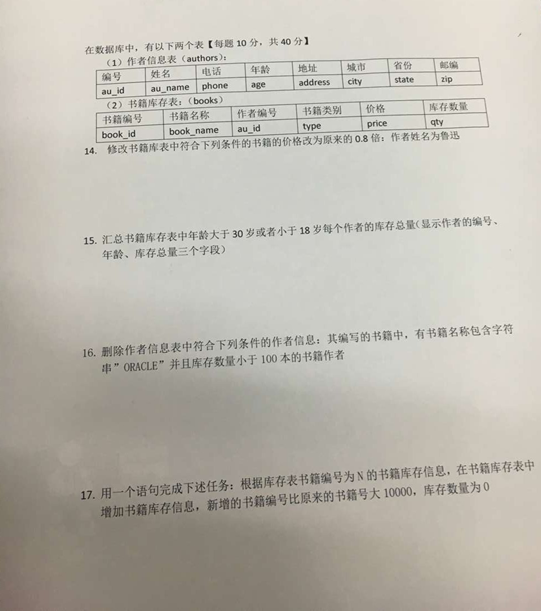
笔试题14:
Update books set price=price*0.8 where au_id=(select au_id from authors where au_name=’鲁迅’);
笔试题16:
delete from authors where au_id in(select au_id from books where book_name like ‘%ORACLE%’ and qty<100);
笔试题17:
Insert into books select book_id+10000,book_name,au_id,type,price,0 from books where book_id=N;