原文链接
挖坑待填
一. 权值线段树
权值线段树即一种线段树,以序列的数值为下标。节点里所统计的值为节点所对应的区间 \([l,r]\) 中,\([l,r]\) 这个值域中所有数的出现次数。
举个例子,有一个长度为 \(10\) 的序列 {\(1,5,2,3,4,1,3,4,4,4\)}。
那么统计每个数出现的次数。易知 \(1\) 出现了 \(2\) 次,\(2\) 出现了 \(1\) 次,\(3\) 出现了 \(2\) 次,\(4\)出现了 \(4\)次,\(5\) 出现了 \(1\) 次。
那么我们可以建出一棵这样的权值线段树:
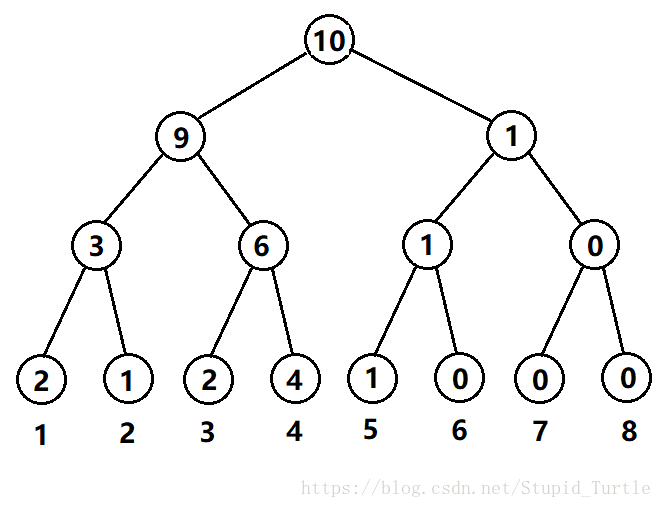
从网上搬的。节点中的数字代表节点对应区间中所有数的出现次数。
-
每个叶子节点的值: 代表 这个值的出现次数。
-
非叶子节点的值:代表了某一个值域内,所有值出现次数的和。
上面的权值线段树中,\(6,7,8\) 并没有出现,然而却被建出。如果序列的数 \(a_i\) 的取值范围是 \(w\),那么我们的树就需要 \(O(wlogw)\) 的空间。这对于大部分题都是无法忍受的。
所以考虑动态开点。一般的线段树,对于节点 \(p\),其 \(ls,rs\) 一般都是 \(p×2\),\(p×2+1\),而这里我们直接定义两个数组 \(ls[p]\),\(rs[p]\) 来表示节点 \(p\) 的左右儿子。
那么这样,我们会建出 \(O(n)\) 个叶子结点,而对于每一个叶子结点往上还有 \(O(logw)\) 的深度,所以总的空间复杂度降为 \(O(nlogw)\)。
小结:权值线段树采用动态开点以节省空间,防止序列的最大值太大导致超内存。
考虑如何用代码实现建树的过程:
inline void pushup(int p){
tr[p]=tr[ls[p]]+tr[rs[p]];
return;
}
inline void update(int &p,int l,int r,int now){
if(!p)p=++id;
if(l==r){
tr[p]++;
return;
}
int mid=(l+r)>>1;
if(now<=mid)update(ls[p],l,mid,now);
else update(rs[p],mid+1,r,now);
pushup(p);
return;
}
我们可以实现在 \(update\) 的过程用中 \(build\)。
我们将 \(p\) 传参,若 \(p\) 未出现过则直接用 \(++id\) 来新建节点。
\(l,r\) 表示当前节点所代表的的区间。\(now\) 表示当前 \(update\) 往权值线段树中加入的值,那么我们就在对于包含 \(now\) 的全部区间上的值都加一。
剩下的部分在例题中具体实现。
二、例题
- \(P1908\) 逆序对
相信大家都做过。
那么考虑使用权值线段树解法。
求逆序对,从左往右遍历数组,遍历到 \(i\) 时,检查一下已经遍历的值 \(a_1∼a{i−1}\) 中,有多少比它大的即可。
这可以用权值线段树来实现。