一、最近公共祖先
(\(Lowest\) \(Common\) \(Ancestors\)),简称\(LCA\)。对于一棵有根树,一个节点到根结点路径上所有的节点都被称为这个节点的祖先节点,祖先节点中除节点自身外的节点也被称为真祖先节点。对于树上的两个不同节点\(u\)和\(v\),其祖先节点必然有一些是重合的,其中深度最大的节点被称为这两个节点的最近公共祖先。
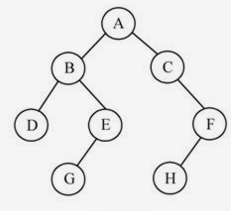
比如上图中的\(D\)点和\(G\)点的最近公共祖先节点就是\(B\)点。首先介绍求解\(LCA\)问题的两种基本方法:
二、向上标记法
我们自己是如何判断\(LCA\)的呢?两只眼睛同时从\(D\)点和\(G\)点往上追溯,很快就可以定位到\(B\)点。计算机向上回溯自然不是问题,但是并不能很快的判断出回溯过程中最先相交于哪一点,因此只能异步的执行节点的回溯。首先\(D\)向上追溯到\(B\)点、\(A\)点,做好访问标记;然后\(G\)点向上追溯到\(E\)点,再往上到\(B\)点发现已经做好标记了,于是\(B\)点就是\(LCA\)节点。这种求解\(LCA\)的办法被称为向上标记法,由其中一个节点向上走到根节点并做好标记,另一个节点再往上走的时候第一次遇见的已标记的节点就是最近公共祖先节点。向上标记法过程相当简单,书上说其复杂度是\(O(n)\),即正比于树上节点的规模。其实该算法的复杂度用\(O(h)\),也就是树高来衡量更加准确。
三、树上倍增法
向上标记法看似简单高效,求上图中\(D\)和\(G\)的\(LCA\)固然很快,但是如果要求多对节点的\(LCA\)呢?比如求\(D\)、\(E\)的,求\(G\)、\(H\)的,...,我们会发现\(G\)点向上走的时候标记了其祖先节点,然后\(E\)向上走又会标记一遍祖先节点,向上回溯的路径大都是相同的,这就存在很大的冗余了。人总是很贪婪
如果同步的向上回溯会怎样呢?预处理下每个节点向上回溯任意步后的位置,记录下来,然后用某种算法快速的求出两个节点的\(LCA\)。
最先遇见的困难就是节点\(u\)和节点\(v\)离他们的\(LCA\)节点的深度差不同,如果两个节点处于同一深度,比如\(G\)和\(H\)点,深度都是\(3\),我们完全可以二分答案了:先判断下\(G\)和\(H\)向上两步是不是到达了同一个节点,如果没到达,就向上四步。如果两个节点是处于同一深度的,我们在预处理节点向上走若干步的信息后,就可以在\(O(log_2h)\)的时间内求出\(LCA\)了。
当然既可以使用二分求解也可以使用倍增求解,两个节点同时向上走\(1\),\(2\),\(4\),...步判断是否到达了同一点。那么我们在后面为什么要选择倍增而不是二分呢?这又是个问题。到这里我们其实已经不知不觉的理解了树上倍增法的第一个重要的步骤:将两个节点调整到同一深度上。比如求\(u\)和\(v\)的\(LCA\),\(u\)的深度是\(10\),\(v\)的深度是\(6\),首先求出\(u\)向上回溯到深度为\(6\)的祖先节点\(u1\),如果\(u1\)就是\(v\)点,那么\(LCA\)就是\(v\),否则继续求\(u1\)和\(v\)的\(LCA\)。此时就是求处于同一深度的两个节点的\(LCA\)了,就十分方便了。所以树上倍增法无非就是先将深度大的节点调整到与深度小的节点同一深度(向上回溯),然后继续求\(LCA\)。
再回到开头说的预处理出所有节点向上回溯若干步的节点,这是十分没有必要的。我们只需要预处理出节点向上回溯\(2\)的倍数步的节点就可以满足我们所有的需要了。比如要回溯\(11\)步,完全可以先走\(8\)步,再走\(2\)步,再走\(1\)步,任何十进制整数肯定是可以转化为二进制表达的,\(11 = (1011)_2\),二进制拆分的思想足以让我们走到任意的地方。为什么是先走步数最大的再逐步缩小步数,而不是先\(1\)再\(2\)再\(8\)呢?因为二进制拆分实现过程中并不需要我们真的去拆分\(11\),我们可以先尝试迈出一个很大的步数,比如\(16\),发现比\(11\)大,于是迈出\(8\)步,再尝试迈出\(4\)步,发现又超过\(11\)了,于是迈出\(2\)步,最后迈出\(1\)步,这是个不断尝试便于实现的倍增过程。调整到同一深度的两个节点需要再次使用倍增的方法求\(LCA\),比如先判断下两个节点向上回溯\(8\)步的节点是不是同一个,是就说明\(LCA\)不会在更高的位置了,于是重新判断向上回溯\(4\)步的是不是同一个,如果不是,则说明\(LCA\)还在上面,再对这个迈出\(4\)步的两个节点继续向上回溯\(2\)步,直至两个节点的父节点就是\(LCA\)为止。
下面用算法实现这一过程。设\(f[i][k]\)表示节点\(i\)向上回溯\(2^k\)步的节点标号,边界情况\(f[i][0]\)表示\(i\)的父节点。\(f\)数组的求解就是使用倍增法常用的动态规划公式了,或者叫分而治之,要想求出\(i\)向上走\(2^k\)步的节点,只需要先求出\(i\)向上走\(2^{k-1}\)步的节点\(j\),然后再求\(j\)向上走\(2^{k-1}\)步的节点即可。用状态转移方程表示就是\(f[i][k] = f[f[i][k-1]][k-1]\),后者更直观点令\(j = f[i][k-1],f[i][k] = f[j][k-1]\),预处理\(f\)数组的过程可以在\(bfs\)遍历树的过程中顺便实现,同时还可以记录下所有节点的深度\(depth\)。
void bfs(int root) {
//跟结点的深度为1
depth[root] = 1;
queue<int> q;
q.push(root);
while (q.size()) {
int u = q.front();
q.pop();
for (int i = h[u]; ~i; i = ne[i]) {
int j = e[i];
if (!depth[j]) {
depth[j] = depth[u] + 1; //记录每个节点的深度
q.push(j);
f[j][0] = u; // f[j][0]表示j的父节点
//因为bfs的特性,所以在计算f[j][k]时,前序依赖数据
// f[j][k - 1],f[f[j][k - 1]][k - 1]肯定已经被填充过
for (int k = 1; k <= 20; k++)
f[j][k] = f[f[j][k - 1]][k - 1];
}
}
}
}
初始情况下将所有节点的深度设置为无穷大,所以一旦从\(u\)可以走到\(j\),并且\(j\)的深度比\(u\)的深度\(+1\)还要大时,就说明\(u\)是\(j\)的父节点,同时可以更新\(j\)的深度了。我们知道\(bfs\)遍历树的过程是层序遍历,遍历到\(j\)时\(j\)的祖先节点的信息都已经被预处理过了,所以此时\(f[j][k] = f[f[j][k - 1]][k - 1]\)中的\(f[j][k-1]\)一定已经求出来了。
再来看下倍增的代码:
//最近公共祖先
int lca(int a, int b) {
// a保持深度更大,更下面
if (depth[a] < depth[b]) swap(a, b);
// 2^20 ~ 2^0 走到同一深度
// https://www.bilibili.com/read/cv13619734
// 上面的链接完美解释了为什么下面的代码是对的
for (int k = 20; k >= 0; k--)
if (depth[f[a][k]] >= depth[b]) a = f[a][k];
//如果a,b是同一个点了,则LCA找到
if (a == b) return a;
//否则继续倍增查找
for (int k = 20; k >= 0; k--)
if (f[a][k] != f[b][k])
a = f[a][k], b = f[b][k];
//返回结果
return f[a][0];
}
如果\(a\)深度大于\(b\),就交换\(a\)、\(b\)节点 ,从而保持\(a\)节点一直在下面。然后就是按照上面所说的倍增的操作二进制拆分调整\(b\)到与\(a\)同一深度,如果两点重合,\(LCA\)就是\(a\)点。否则,继续对\(a\)、\(b\)向上倍增求\(LCA\),最后的结果为什么是\(a\)的父节点呢?这是因为倍增的终点就是\(a\)和\(b\)调整到\(LCA\)节点的下一层。举个例子,比如\(a\)和\(b\)离\(LCA\)有\(6\)步,首先\(a\)和\(b\)都向上走\(4\)步,然后想向上走\(2\)步发现此时两点重合了,于是只走一步,此时倍增终止,\(a\)和\(b\)离\(LCA\)恰好是一步之遥。
完整代码
#include <bits/stdc++.h>
using namespace std;
const int N = 40010, M = 80010;
//邻接表
int e[M], h[N], idx, ne[M];
void add(int a, int b) {
e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
int n;
int dep[N]; //每个节点的深度
int f[N][22]; //设f[i][k]表示节点i向上回溯2^k步的节点标号
//预处理
// 1、每个点的深度
// 2、记录节点i向上回溯2^k步的节点标号
void bfs(int t) {
dep[t] = 1; //根结点深度为1
queue<int> q; //声明队列,准备从根开始对整棵树进行宽搜
q.push(t); //根节点入队列
while (q.size()) {
int u = q.front();
q.pop();
for (int i = h[u]; ~i; i = ne[i]) {
int j = e[i];
if (!dep[j]) { //如果深度为0,表示没有访问过,防止走回头路
dep[j] = dep[u] + 1; //记录每个节点的深度
q.push(j); //下一次该j发挥作用了
f[j][0] = u; // f[j][0]表示j跳2^0=1到达的是它的父节点
/*举个栗子:
j 向上跳 2^0=1,2^1=2,2^2=4,2^3=8,2^4=16,2^5=32,...步,
分别记录这样跳到达的节点是什么编号,这样其实是按二进制思想记录的
信息。??
f[j][k] = f[f[j][k - 1]][k - 1] 采用了递推的思路,利用
j^k = j^(k-1) * j^(k-1) 进行快速找到目标节点号。
因为bfs特性,在计算f[j][k]时,前序依赖数据已经被填充过,可以快速利用
生成f数组时,是正向生成的,即1~15,等使用时是倒序使用的,从15~1
*/
for (int k = 1; k <= 20; k++)
f[j][k] = f[f[j][k - 1]][k - 1];
}
}
}
}
//最近公共祖先
int lca(int a, int b) {
// a保持深度更大
if (dep[a] < dep[b]) swap(a, b);
/* 最开始如果直接跳2^15,很可能直接跳冒了,dep[f[a][k]]=0了,
那么也就不能>=dep[b]。直到跳不冒,才能>=dep[b],即a在b的下方。
通过a=f[a][k]进行替代,继续尝试更小的k,使得最终达到dep[a]=dep[b]
的目标,真是太完美的逻辑了,这TM是人想出来的吗?
*/
for (int k = 15; k >= 0; k--)
if (dep[f[a][k]] >= dep[b]) a = f[a][k];
// a==b,LCA就是b,或者说就是a,现在它俩是一样的
if (a == b) return a;
/*现在好了,两个在同一深度
从大到小来,其实可以理解为二进制数字从高位到低位的处理
举个栗子:k=15,那么a,b跳2^15次步可能早就冒了,f数组默认值是0,
所以会自动跳过太大无用的数字k,直到f[a][k]!=f[b][k]
比如 a,b在同一层,向上13级是lca,那么现在的逻辑就是:
跳2^4=16(k=4)步:冒了,f[a][k]=f[b][k]=0,不满足f[a][k] != f[b][k],k继续减小
跳2^3=8 (k=3)步:因为13>8,即13里有1个8,所以a跳8步到达的祖先,与b跳8步到达的祖先,还不是一个人
直接令a=跳8步后到达的祖先,b=跳8步后到达的祖先,从这里再出发。
13-8=5 距离变小了,因为5了
跳2^2=4后,还是不等,5-4=1了。注意,这里是1啦!!
2^1=2,这时f[a][k] == f[b][k] 不进行任何操作!
2^0=1,这时f[a][k] == f[b][k] 不进行任何操作!
最终,a,b停留在它们俩lca的下方一级的位置上!!
*/
for (int k = 20; k >= 0; k--)
if (f[a][k] != f[b][k])
a = f[a][k], b = f[b][k];
//返回a的父亲=LCA
return f[a][0];
}
int main() {
cin >> n;
int a, b, m, root;
memset(h, -1, sizeof h);
for (int i = 0; i < n; i++) {
cin >> a >> b;
if (b == -1)
root = a; //找到根节点
else
add(a, b), add(b, a); //树是双向图
}
//预处理
bfs(root);
cin >> m;
while (m--) {
cin >> a >> b;
//调用LCA算法,计算a,b最近公共祖先
int p = lca(a, b);
if (p == a)
puts("1");
else if (p == b)
puts("2");
else
puts("0");
}
return 0;
}
四、相关资源
最近公共祖先与树上差分
https://www.bilibili.com/video/av458810255/
模板题
Luogu P3379 LCA倍增法 (√)
好题练手
Luogu P3884 [JLOI2009] 二叉树问题 (TODO)
Luogu P4281 [AHOI2008] 紧急集合/聚会 (TODO)
Luogu P1963 [NOIP提高组2013] 火车运输 (TODO)
Luogu P4271 [USACO18FEB] New Barns P (TODO)