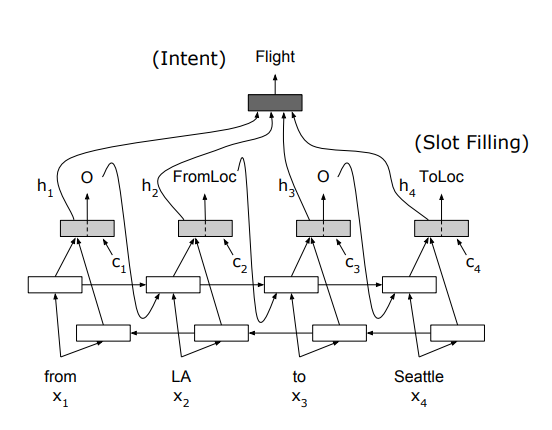
一.智能对话中的意图识别和槽填充联合建模,类似于知识图谱中的关系提取和实体识别。一种方法是利用两种模型分别建模;另一种是将两种模型整合到一起做联合建模型。意图识别基本上是文本分类,而槽填充基本上是序列标注。本方法是基于文章《Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling》中提到的另一种方法Attention-Based RNN Model做联合建模。模型结构如下图:
此模型利用birnn-attention实现:
1.意图识别是利用encoder中的最后一个time step中的双向隐层,再加上平均池化或者利用attention加权平均,最后接一个fc层进行分类
2.槽填充是序列标注,双向隐状态加attention权重,再经过一个单元grucell,最后接一个fc层分类。这里注意一点是,槽的每一步的预测输出会输入到grucell中的前向传输时间步中。
3.总的loss = 意图识别loss + 槽填充loss
二.模型程序(完整程序见https://github.com/jiangnanboy/intent_detection_and_slot_filling/tree/master/model2)
1.构建train及val 数据,采用torchtext。其中SOURCE是源句,TARGET是标注,LABEL是意图类别
'''
build train and val dataset
'''
tokenize = lambda s:s.split()
SOURCE = data.Field(sequential=True, tokenize=tokenize,
lower=True, use_vocab=True,
init_token='<sos>', eos_token='<eos>',
pad_token='<pad>', unk_token='<unk>',
batch_first=True, fix_length=50,
include_lengths=True) #include_lengths=True为方便之后使用torch的pack_padded_sequence
TARGET = data.Field(sequential=True, tokenize=tokenize,
lower=True, use_vocab=True,
init_token='<sos>', eos_token='<eos>',
pad_token='<pad>', unk_token='<unk>',
batch_first=True, fix_length=50,
include_lengths=True) #include_lengths=True为方便之后使用torch的pack_padded_sequence
LABEL = data.Field(
sequential=False,
use_vocab=True)
train, val = data.TabularDataset.splits(
path=atis_data,
skip_header=True,
train='atis.train.csv',
validation='atis.test.csv',
format='csv',
fields=[('index', None), ('intent', LABEL), ('source', SOURCE), ('target', TARGET)])
SOURCE.build_vocab(train, val)
TARGET.build_vocab(train, val)
LABEL.build_vocab(train, val)
train_iter, val_iter = data.Iterator.splits(
(train, val),
batch_sizes=(32, len(val)), # 训练集设置为64,验证集整个集合用于测试
shuffle=True,
sort_within_batch=True, #为true则一个batch内的数据会按sort_key规则降序排序
sort_key=lambda x: len(x.source)) #这里按src的长度降序排序,主要是为后面pack,pad操作)
2.构建模型
# build model
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 构建attention权重计算方式
class Attention(nn.Module):
def __init__(self, hidden_dim):
super(Attention, self).__init__()
self.attn = nn.Linear((hidden_dim * 2), hidden_dim)
self.v = nn.Linear(hidden_dim, 1, bias=False)
def concat_score(self, hidden, encoder_output):
seq_len = encoder_output.shape[1]
hidden = hidden.unsqueeze(1).repeat(1, seq_len, 1) # [batch_size, seq_len, hidden_size]
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_output),dim=2))) # [batch_size, seq_len, hidden_dim]
attention = self.v(energy).squeeze(2) #[batch_size, seq_len]
return attention #[batch_size, seq_len]
def forward(self, hidden, encoder_output):
# hidden = [batch_size, hidden_size]
# #encoder_output=[batch_size, seq_len, hidden_size]
attn_energies = self.concat_score(hidden, encoder_output)
return F.softmax(attn_energies, dim=1).unsqueeze(1) #softmax归一化,[batch_size, 1, seq_len]
#构建模型
class BirnnAttention(nn.Module):
def __init__(self, source_input_dim, source_emb_dim, hidden_dim, n_layers, dropout, pad_index, slot_output_size, intent_output_size, slot_embed_dim, predict_flag):
super(BirnnAttention, self).__init__()
self.pad_index = pad_index
self.hidden_dim = hidden_dim//2 # 双向lstm
self.n_layers = n_layers
self.slot_output_size = slot_output_size
# 是否预测模式
self.predict_flag = predict_flag
self.source_embedding = nn.Embedding(source_input_dim, source_emb_dim, padding_idx=pad_index)
# 双向gru,隐层维度是hidden_dim
self.source_gru = nn.GRU(source_emb_dim, self.hidden_dim, n_layers, dropout=dropout, bidirectional=True, batch_first=True) #使用双向
# 单个cell的隐层维度与gru隐层维度一样,为hidden_dim
self.gru_cell = nn.GRUCell(slot_embed_dim + (2 * hidden_dim), hidden_dim)
self.attention = Attention(hidden_dim)
# 意图intent预测
self.intent_output = nn.Linear(hidden_dim * 2, intent_output_size)
# 槽slot预测
self.slot_output = nn.Linear(hidden_dim, slot_output_size)
self.slot_embedding = nn.Embedding(slot_output_size, slot_embed_dim)
def forward(self, source_input, source_len):
'''
source_input:[batch_size, seq_len]
source_len:[batch_size]
'''
if self.predict_flag:
assert len(source_input) == 1, '预测时一次输入一句话'
seq_len = source_len[0]
# 1.Encoder阶段,将输入的source进行编码
# source_embedded:[batch_size, seq_len, source_emb_dim]
source_embedded = self.source_embedding(source_input)
packed = torch.nn.utils.rnn.pack_padded_sequence(source_embedded, source_len, batch_first=True, enforce_sorted=True) #这里enfore_sotred=True要求数据根据词数排序
source_output, hidden = self.source_gru(packed)
# source_output=[batch_size, seq_len, 2 * self.hidden_size],这里的2*self.hidden_size = hidden_dim
# hidden=[n_layers * 2, batch_size, self.hidden_size]
source_output, _ = torch.nn.utils.rnn.pad_packed_sequence(source_output, batch_first=True, padding_value=self.pad_index, total_length=len(source_input[0])) #这个会返回output以及压缩后的legnths
'''
source_hidden[-2,:,:]是gru最后一步的forward
source_hidden[-1,:,:]是gru最后一步的backward
'''
# source_hidden=[batch_size, 2*self.hidden_size]
source_hidden = torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1)
#保存注意力向量
attention_context = torch.zeros(1, seq_len, self.hidden_dim * 2)
output_tokens = []
aligns = source_output.transpose(0,1) #对齐向量
input = torch.tensor(2).unsqueeze(0) # 预测阶段解码器输入第一个token-> <sos>
for s in range(seq_len):
aligned = aligns[s].unsqueeze(1)# [batch_size, 1, hidden_size*2]
# embedded=[1, 1, slot_embed_dim]
slot_embedded = self.slot_embedding(input)
slot_embedded = slot_embedded.unsqueeze(0)
# 利用利用上一步的hidden与encoder_output,计算attention权重
# attention_weights=[batch_size, 1, seq_len]
attention_weights = self.attention(source_hidden, source_output)
'''
以下是计算上下文:利用attention权重与encoder_output计算attention上下文向量
注意力权重分布用于产生编码器隐藏状态的加权和,加权平均的过程。得到的向量称为上下文向量
'''
context = attention_weights.bmm(source_output)
attention_context[:,s,:] = context
combined_grucell_input = torch.cat([aligned, slot_embedded, context], dim =2)
source_hidden = self.gru_cell(combined_grucell_input.squeeze(1), source_hidden)
slot_prediction = self.slot_output(source_hidden)
input = slot_prediction.argmax(1)
output_token = input.squeeze().detach().item()
output_tokens.append(output_token)
#意图识别
#拼接注意力向量和encoder的输出
combined_attention_sourceoutput = torch.cat([attention_context, source_output], dim=2)
intent_outputs = self.intent_output(torch.mean(combined_attention_sourceoutput, dim = 1))
intent_outputs = intent_outputs.squeeze()
intent_outputs = intent_outputs.argmax()
return output_tokens, intent_outputs
else:
# 1.Encoder阶段,将输入的source进行编码
# source_embedded:[batch_size, seq_len, source_emb_dim]
source_embedded = self.source_embedding(source_input)
packed = torch.nn.utils.rnn.pack_padded_sequence(source_embedded, source_len, batch_first=True, enforce_sorted=True) #这里enfore_sotred=True要求数据根据词数排序
source_output, hidden = self.source_gru(packed)
# source_output=[batch_size, seq_len, 2 * self.hidden_size],这里的2*self.hidden_size = hidden_dim
# hidden=[n_layers * 2, batch_size, self.hidden_size]
source_output, _ = torch.nn.utils.rnn.pad_packed_sequence(source_output, batch_first=True, padding_value=self.pad_index, total_length=len(source_input[0])) #这个会返回output以及压缩后的legnths
'''
source_hidden[-2,:,:]是gru最后一步的forward
source_hidden[-1,:,:]是gru最后一步的backward
'''
# source_hidden=[batch_size, 2*self.hidden_size]
source_hidden = torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1)
# 2.Decoder阶段,预测slot与intent
batch_size = source_input.shape[0]
seq_len = source_input.shape[1]
# 保存slot的预测概率
slot_outputs = torch.zeros(batch_size, seq_len, self.slot_output_size).to(device)
#保存注意力向量
attention_context = torch.zeros(batch_size, seq_len, self.hidden_dim * 2).to(device)
# 每个batch数据的第一个字符<sos>对应的是index是2
input = torch.tensor(2).repeat(batch_size).to(device)
aligns = source_output.transpose(0,1) # 利用encoder output最后一层的每一个时间步
# 槽识别
for t in range(1, seq_len):
'''
解码器输入的初始hidden为encoder的最后一步的hidden
接收输出即predictions和新的hidden状态
'''
aligned = aligns[t].unsqueeze(1)# [batch_size, 1, hidden_size] # hidden_size包含前向和后向隐状态向量
input = input.unsqueeze(1)
# input=[batch_size, 1]
# hidden=[batch_size, hidden_size] 初始化为encoder的最后一层 [batch_size, hidden_size]
# encoder_output=[batch_size, seq_len, hidden_dim*2]
# aligned=[batch_size, 1, hidden_dim*2]
# embedded=[batch_sze, 1, slot_embed_dim]
slot_embedded = self.slot_embedding(input)
# 利用利用上一步的hidden与encoder_output,计算attention权重
# attention_weights=[batch_size, 1, seq_len]
attention_weights = self.attention(source_hidden, source_output)
'''
以下是计算上下文:利用attention权重与encoder_output计算attention上下文向量
注意力权重分布用于产生编码器隐藏状态的加权和,加权平均的过程。得到的向量称为上下文向量
'''
context = attention_weights.bmm(source_output) # [batch_size, 1, seq_len] * [batch_size, seq_len, hidden_dim]=[batch_size, 1, hidden_dim]
attention_context[:,t,:] = context.squeeze(1)
#combined_grucell_input=[batch_size, 1, (hidden_size + slot_embed_dim + hidden_dim)]
combined_grucell_input = torch.cat([aligned, slot_embedded, context], dim =2)
# [batch_size, hidden_dim]
source_hidden = self.gru_cell(combined_grucell_input.squeeze(1), source_hidden)
# 预测slot, [batch_size, slot_output_size]
slot_prediction = self.slot_output(source_hidden)
slot_outputs[:, t, :] = slot_prediction
# 获取预测的最大概率的token
input = slot_prediction.argmax(1)
#意图识别,不同于原论文。这里拼接了slot所有时间步attention_context与句子编码后的输出,通过均值后作为意图识别的输入
#拼接注意力向量和encoder的输出,[batch_size, seq_len, hidden_dim * 2]
combined_attention_sourceoutput = torch.cat([attention_context, source_output], dim=2)
intent_outputs = self.intent_output(torch.mean(combined_attention_sourceoutput, dim = 1))
return slot_outputs, intent_outputs
3.loss,这里迭代的次数为10

4.predict预测
