一.利用textrcnn进行文本分类,用于在问答中的意图识别。
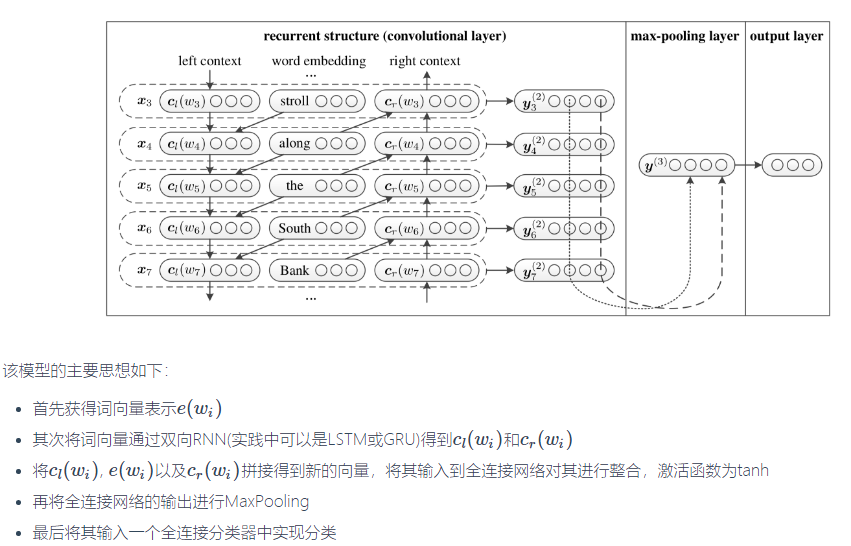
二.结构图
import os import torch from torchtext import data,datasets from torchtext.data import Iterator, BucketIterator from torchtext.vocab import Vectors from torch import nn,optim import torch.nn.functional as F import pandas as pd import pickle DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu') intent_classification_path = os.path.abspath(os.path.join(os.getcwd(), '../..')) # 训练数据路径 train_data = os.path.join(intent_classification_path,'classification_data/classification_data.csv') # 读取数据 train_data = pd.read_csv(train_data) # 按字分 tokenize =lambda x: x.split(' ') TEXT = data.Field( sequential=True, tokenize=tokenize, lower=True, use_vocab=True, pad_token='<pad>', unk_token='<unk>', batch_first=True, fix_length=20) LABEL = data.Field( sequential=False, use_vocab=False) # 获取训练或测试数据集 def get_dataset(csv_data, text_field, label_field, test=False): fields = [('id', None), ('text', text_field), ('label', label_field)] examples = [] if test: #测试集,不加载label for text in csv_data['text']: examples.append(data.Example.fromlist([None, text, None], fields)) else: # 训练集 for text, label in zip(csv_data['text'], csv_data['label']): examples.append(data.Example.fromlist([None, text, label], fields)) return examples, fields train_examples,train_fields = get_dataset(train_data, TEXT, LABEL) train = data.Dataset(train_examples, train_fields) # 预训练数据 pretrained_embedding = os.path.join(os.getcwd(), 'sgns.sogou.char') vectors = Vectors(name=pretrained_embedding) # 构建词典 TEXT.build_vocab(train, min_freq=1, vectors = vectors) words_path = os.path.join(os.getcwd(), 'words.pkl') with open(words_path, 'wb') as f_words: pickle.dump(TEXT.vocab, f_words) BATCH_SIZE = 163 # 构建迭代器 train_iter = BucketIterator( dataset=train, batch_size=BATCH_SIZE, shuffle=True, sort_within_batch=False) class TextRCNN(nn.Module): def __init__(self, vocab_size, embedding_dim, hidden_size, num_layers, output_size, dropout=0.5): super(TextRCNN, self).__init__() self.embedding = nn.Embedding(vocab_size, embedding_dim) # 这里batch_first=True,只影响输入和输出。hidden与cell还是batch在第2维 self.lstm = nn.LSTM(embedding_dim, hidden_size, num_layers, bidirectional=True, batch_first=True, dropout=dropout) self.dropout = nn.Dropout(dropout) self.fc = nn.Linear(hidden_size*2+embedding_dim, output_size) def forward(self, x): # x :(batch, seq_len) = (163, 20) # [batch,seq_len,embedding_dim] -> (163, 20, 300) x = self.embedding(x) #out=[batch_size, seq_len, hidden_size*2] #h=[num_layers*2, batch_size, hidden_size] #c=[num_layers*2, batch_size, hidden_size] out,(h, c)= self.lstm(x) # 拼接embedding与bilstm out = torch.cat((x, out), 2) # [batch_size, seq_len, embedding_dim + hidden_size*2] # 激活 # out = F.tanh(out) out = F.relu(out) # 维度转换 => [batch_size, embedding_dim + hidden_size*2, seq_len] #out = torch.transpose(out, 1, 2),一维池化针对最后一维,所以转换维度 out = out.permute(0, 2, 1) out = F.max_pool1d(out, out.size(2)) out = out.squeeze(-1) # [batch_size,embedding_dim + hidden_size * 2] out = self.dropout(out) out = self.fc(out) # [batch_size, output_size] return out
from torch.utils.tensorboard import SummaryWriter writer = SummaryWriter(os.getcwd()+'/log', comment='textrnn') # 训练 # 构建model model = TextRCNN(len(TEXT.vocab), TEXT.vocab.vectors.shape[1], 128, 2, 16).to(DEVICE) # 利用预训练模型初始化embedding,requires_grad=True,可以fine-tune model.embedding.weight.data.copy_(TEXT.vocab.vectors) # 训练模式 model.train() # 优化和损失 # optimizer = torch.optim.Adam(model.parameters(),lr=0.1, weight_decay=0.1) optimizer = torch.optim.SGD(model.parameters(),lr=0.1, momentum=0.95, nesterov=True) criterion = nn.CrossEntropyLoss() with writer: for iter in range(300): for i, batch in enumerate(train_iter): train_text = batch.text train_label = batch.label train_text = train_text.to(DEVICE) train_label = train_label.to(DEVICE) out = model(train_text) loss = criterion(out, train_label) optimizer.zero_grad() loss.backward() optimizer.step() if (iter+1) % 10 == 0: print ('iter [{}/{}], Loss: {:.4f}'.format(iter+1, 300, loss.item())) #writer.add_graph(model, input_to_model=train_text,verbose=False) writer.add_scalar('loss',loss.item(),global_step=iter+1) writer.flush() writer.close() model_path = os.path.join(os.getcwd(), "model.h5") torch.save(model.state_dict(), model_path)