SAST : Single-Shot Arbitrarily-Shaped Text Detector
1. 基本信息
文章来源:ACM Multimedia 2019 SAST链接
上传时间:2019.8.15
作者单位:百度、西安电子科大
检测框架:分割与边界点回归,属于EAST的演进版本 EAST链接
2. 提出问题
自然场景的文本检测存在如下挑战: 尺寸、高宽比、方向、语言、外形的多变性,检测背景的复杂性。为了检测任意外形的文本,目前一些研究团队提出使用基于全卷积网络的语义分割模型来执行文本检测。由于缺乏全局的上下文信息,该方法会出现新的问题:
1)相邻紧密的文本实例很难通过语义分割的方法进行分离;
2)长文本实例容易被碎片化,尤其是当字符相隔较远或背景较复杂时;
为此上述问题,研究者采取了输出大分辨率的预测图来实现文本实例的精确定位,但这又会产生运算资源消耗大、冗长的后处理等新的问题。此外,proposal-based的分割方法可能消耗大量运算时间,当有效的文本提议框增多或者较稠密时;
3. 文章思想与实现流程
3.1 文章思想

作者提出,当下的文本检测研究仍在对长弯曲文本的识别不佳、运算资源消耗大、后处理冗长等问题,为解决这些不足之处,作者设计了基于分割方法的任意形状文本检测器SAST,其属于EAST的演进版本,网络输出的中间结果分别有表示像素点是否为文本的score map和表示像素点到各个指定的边界的xy距离的geometry map.
SAST的后处理可大致地分为两个步骤,第一步骤为将高低层级的信息融合得到准确的、表示不同文本实例的文本中心线,高层级目标知识指的是TCL文本中心线分数图利用TVO文本顶点偏置信息所得的文本实例矩形框的中心点(注意: 该操作得到的目标框可能是不完整的、没有完全地将文本实例包围住的),低层级的像素信息指的是像素点到其所属文本实例矩形框中心点的距离,当高低层级的信息进行融合时,即判断这两个中心点是否重合或者两者间的距离是否小于某值,并据此来判断矩形框外的像素点是否属于矩形框所对应的文本实例,解决了长文本检测的断裂与框选不全的缺点。
SAST后处理的第步骤比较常规,其利用步骤1所得的文本中心区域拟合出文本中心线,然后在中心线上等距离采样,并依据TBO边界偏置图计算每个采样点所对应的上线边界定位点,最后将这些定位点按照从左到右,从上到下的顺时针方向来重构出文本实例边界框。
3.2 实现流程
(1)网络预测结果输出:
SAST采用基于ResNet-50的FPN特征金字塔网络,并通过1×1或3×3的FCN全卷积层输出如下与原图尺寸相同的预测中间结果:
1) TCL map: 单通道,Text center line, 输入图像某像素点属于文本中心线像素点的概率;
2) TCO map: 双通道,text center offset, 文本中心点偏置,输入图像某像素点距其所属的文本实例矩形框中心的xy方向距离;
3) TVO map: 八通道,text vertex offset,文本四顶点偏置,输入图像某像素点距其所属的文本实例矩形框四顶点的xy方向距离;
4) TBO map: 四通道,text border offset, 文本边界偏置,输入图像某像素点距其所属的文本实例上下边界框的xy方向距离;
(2)后处理之文本实例分割:
输入图像经模型预测输出的text center line map是一幅score map,但由于原图中文本实例的字符间距较大或文本实例跨度过长,输出的TCL中相同文本实例的中心线可能会断开,文本中心线断裂情况如下图所示:


为此,SAST引入了高层级的目标知识与低层级的像素信息结合的方法,将具有相同特征的、破碎分离的像素点归类为同一文本实例。具体实现流程如下:
1) TCL进行阈值过滤,将置信率低于某值的假阳性像素点剔除,得到合适的TCL map;
2) 将经过处理的TCL map中每个像素点,根据TVO文本实例顶点偏置图,得到对应的文本矩形框四顶点坐标,并进行非最大值抑制NMS,得到所需的文本实例矩形框及其中心点,如下左图所示,该矩形框将作为高层级目标知识;
3) 根据TCO map,计算TCL中属于文本的像素点的所属文本实例的几何中心点,该中心点将作为低层级像素信息,如下中图所示,当步骤3计算所得的几何中心点与步骤2所得矩形框中心点重合或相近时,该像素点将被归类给步骤2中矩形框对应的文本实例,因此,步骤1中断裂的文本区域或步骤2中未被选中的像素点,将通过此步骤重新聚集归类,将所有高于阈值的像素点划分为不同的文本实例,如下右图所示,其中,相同颜色的像素点代表其属于同一文本实例;

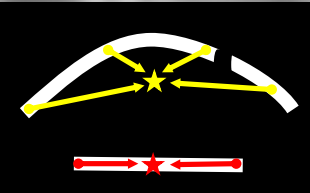

(3) 后处理之文本边框重构:
经过文本实例分割步骤后,将得到被TVO、TCO修正后的、准确的TCL文本中心线,如下图(a)所示。文本边框的重构流程如下:
1) 对文本中心线采样,采样点的间距相同,则得到的采样点数目与文本线的长度有关,故称之为自适应采样,如图(b)所示,红点即为采样点;
2) 根据文本边界偏置图TBO所提供的信息,计算文本中心线的采样点上的上下边界定位点,由此可知步骤1的采样是为了减少步骤2中计算边界点所需的运算资源,提高处理速度;
3) 将步骤2所得的边界定位点按照从左上角开始的顺时针方向依次进行连接,得到最终的文本边界框;

4. Label Generation and Loss Function
4.1 坐标生成

(1)文本中心线 Text center line:
如上图a所示,文本中心区域是文本行上下边界收缩20%后得到的区域,而左右边界仍保持不变;
(2)文本边界偏置 Text border offset:
文本边界偏置的生成如上图b所示,首先计算斜率k1(v1,v2)与斜率k1(v4,v3)的平均值,对于一个给定的点P0,可容易地计算出斜率为(k1+k2)/2、过点P0的直线,由此该直线与线段(v1,v4)和线段(v2,v3)的交点P1与P2很容易得出,故P0的上下边界点Pupper和Plower的坐标可由线段比例关系得到;
(3)文本顶点偏置 Text vertex offset:
文本最小矩形框按根据一定规则由文本标注信息计算得到,计算文本中心区域中某像素点到文本矩形框四顶点的直线距离,并将距离作为该位置像素点的值存作TVO map,则一共将会得到八张TVO map.
(4)文本中心点偏置 Text center offset:
计算文本中心区域内某像素点到文本最小矩形框中心点的距离,则可得到TCO map.
4.2 损失函数
(1)TCL map: 使用Minimizing the Dice loss作为分割loss, 用于描述两个轮廓的相似程度;
(2)TVO/TCO/TBO: 使用Smooth L1 Loss 作为 几何图 geometry map的回归loss;