1、 URL格式错误,一般指URL格式不规范导致无法建立连接,通常会产生URLrequired错误。如果URL格式正确,则可能触发Timeout类错误。
2、 在Requests库中,post()、put()、patch()都体现数据推送操作。
3、 request()是基础性函数,只需一个函数即可完成全部功能。
4、 Request库共有7个主要方法:request()、get()、head()、post()、patch()、put()、delete()
5、 r.status_code,200表示连接成功,404表示失败。
6、 .encoding是从HTTP header中猜测获得响应内容编码方式。
7、 从服务器返回HTTP协议内容部分猜测获得编码方式的属性是.apparent_encodeing
8、 DNS查询失败造成的获取URL异常:requests.ConnectionError
9、 服务器因为安全原因对其它方法进行限制,get()方法最常用
10、 Requests是爬虫库,只用于获取页面,不对页面信息进行提取。
11、 From bs4 import BeautifulSoup 指从bs4库中引入一个元素(函数或类),这里BeautifulSoup是类。
12、 一个文档只对应一个标签树。
13、 <a class="title" href="https://python123.io/ws/demo.html">TEXT</a>
A是标签,href是属性。
14、 bs4解析器是能够解释HTML或XML的一个第三方库,re用来表达并匹配正则表达式的,不能够装载到bs4库中。
15、 bs4库遍历标签树的方法有:上行遍历,下行遍历,平行遍历。
16、 BeautifulSoup库不能够生成标签树,只能解析、遍历和维护。
17、 正则表达式可用于自动化脚本,但不是其优势。
18、 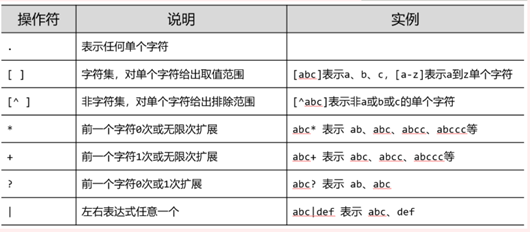
19、
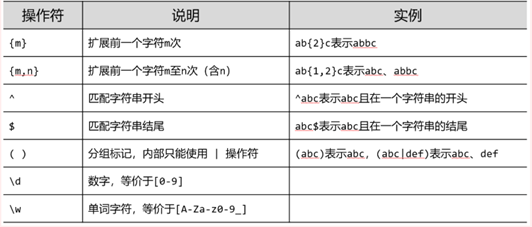
20、 网络爬虫与信息提取相关技术路线至少包含一个爬虫库和一个解析库,bs4和re都是解析库。
21、 Robots协议是否有允许是爬虫能够实施的首要条件。
22、 爬虫不会造成网络攻防对抗,被爬取的服务器可能会被爬虫攻击,但没有对抗。
23、 Sciapy具有5+2结构,其中五个模块分别是:Engine、Spiders、Scheduler、Downloader和Item Pipelines。
24、 Spider模块给出了Scrapy爬虫最初始的请求。
25、 Scrapy中使用REQUESTS表达URL,URL不是其直接承载的元素。
26、 Spider->Engine->Scheduler,Spider请求不直接到Downloader模块。
27、 在Scrapy框架中,Downloader爬取页面内容后,结果经Engine发送到Spider
28、 Spiders->Engine->(ITEMS) Item Pipelines
->(REQUESTS) Scheduler
根据不同类型的结果,有两个路径。