目录:
- 什么是大数据
- Hadoop介绍-HDFS、MR、Hbase
- 大数据平台应用举例-腾讯
- 公司的大数据平台架构
“就像望远镜让我们能够感受宇宙,显微镜让我们能够观测微生物一样,大数据正在改变我们的生活以及理解世界的方式……”。
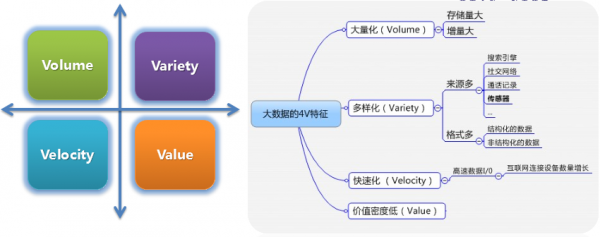
大数据的4V特征-来源
公司的“大数据”
随着公司业务的增长,大量和流程、规则相关的非结构化数据也爆发式增长。比如:
1、业务系统现在平均每天存储20万张图片,磁盘空间每天消耗100G;
2、平均每天产生签约视频文件6000个,每个平均250M,磁盘空间每天消耗1T;
……
三国里的“大数据”
“草船借箭”和大数据有什么关系呢?对天象的观察是基于一种对风、云、温度、湿度、光照和所处节气的综合分析这些数据来源于多元化的“非结构”类型,并且数据量较大,只不过这些数据输入到的不是电脑,而是人脑并最终通过计算分析得出结论。

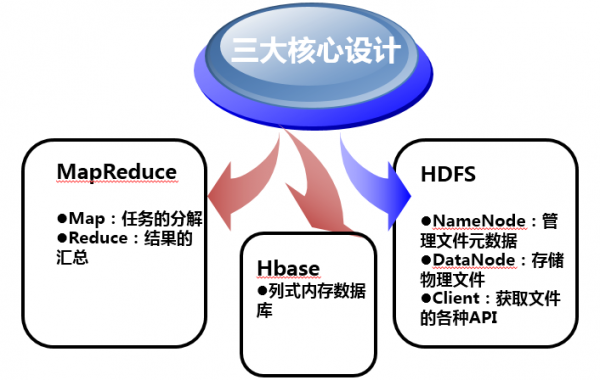
Google分布式计算的三驾马车
- Google File System用来解决数据存储的问题,采用N多台廉价的电脑,使用冗余(也就是一份文件保存多份在不同的电脑之上)的方式,来取得读写速度与数据安全并存的结果。
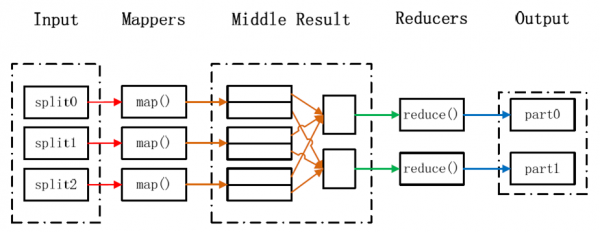
- Map-Reduce说穿了就是函数式编程,把所有的操作都分成两类,map与reduce,map用来将数据分成多份,分开处理,reduce将处理后的结果进行归并,得到最终的结果。
- BigTable是在分布式系统上存储结构化数据的一个解决方案,解决了巨大的Table的管理、负载均衡的问题。
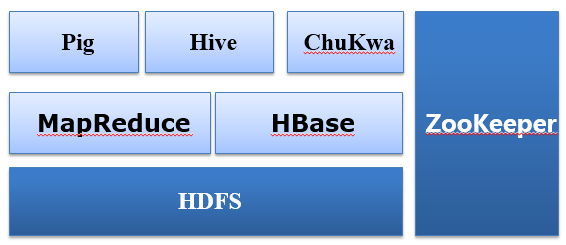
Hadoop体系架构
Hadoop核心设计
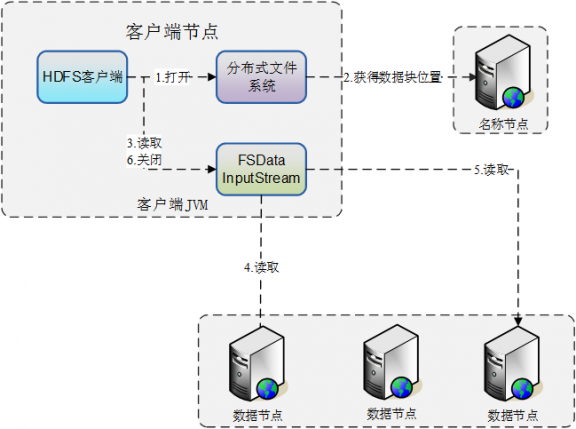
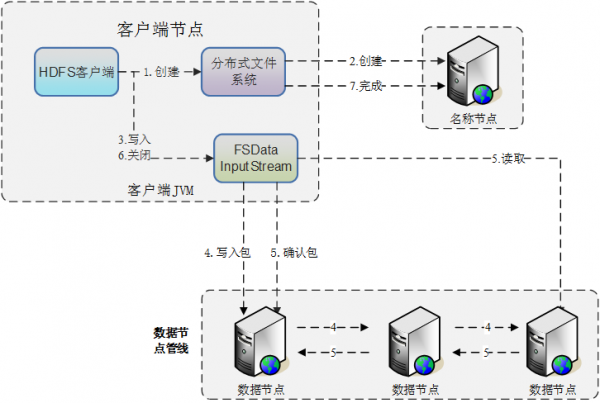
HDFS介绍-文件读流程
Hbase——分布式数据存储系统
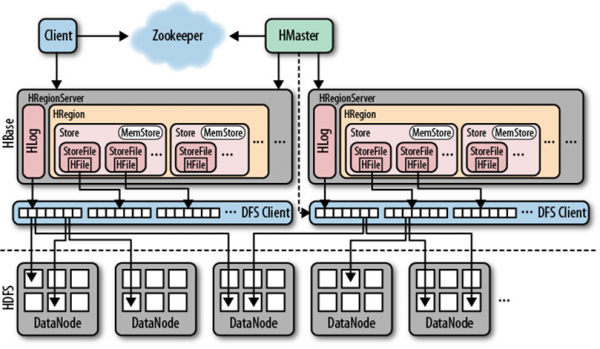
Client:使用HBase RPC机制与HMaster和HRegionServer进行通信
Zookeeper:协同服务管理,HMaster通过Zookeepe可以随时感知各个HRegionServer的健康状况
HMaster: 管理用户对表的增删改查操作
HRegionServer:HBase中最核心的模块,主要负责响应用户I/O请求,向HDFS文件系统中读写数据
HRegion:Hbase中分布式存储的最小单元,可以理解成一个Table
HStore:HBase存储的核心。由MemStore和StoreFile组成。
HLog:每次用户操作写入Memstore的同时,也会写一份数据到HLog文件
还有哪些NoSQL产品?

为什么要使用NoSQL?
一个高并发网站的DB进化史

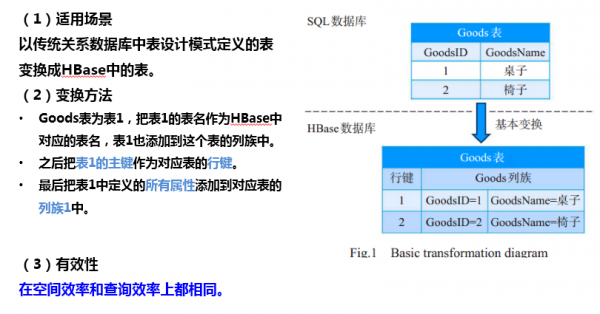
关系模型>聚合数据模型的转换-基本变换
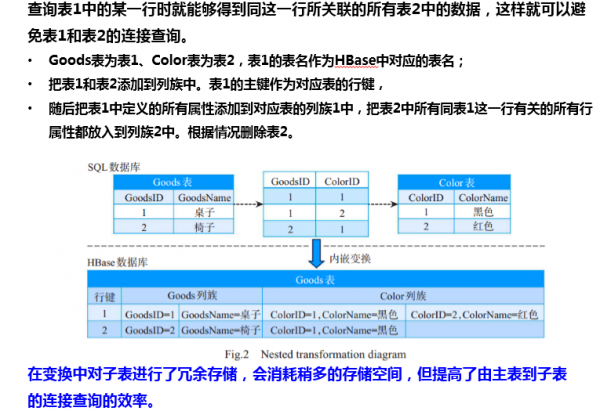
关系模型>聚合数据模型的转换-内嵌变换
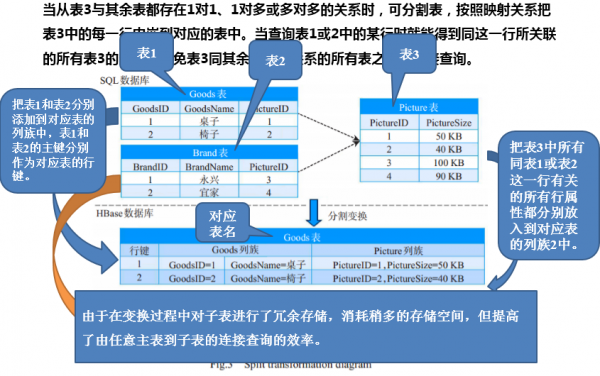
关系模型>聚合数据模型的转换-分割变换
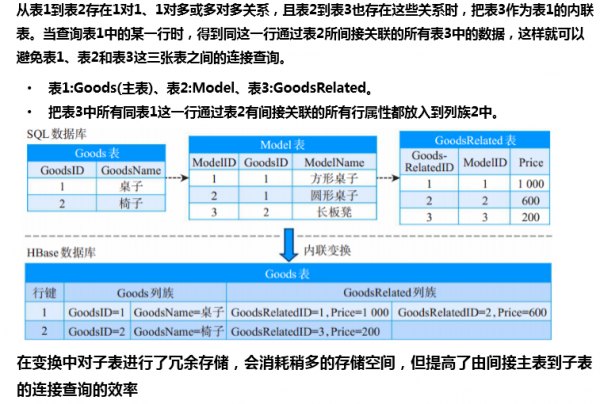
关系模型>聚合数据模型的转换-内联变换
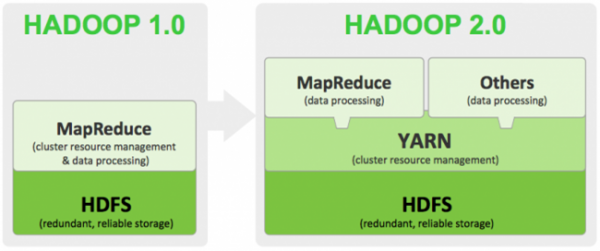
Hadoop2.0
MapReduce:
JobTracker:协调作业的运行。
TaskTracker:运行作业划分后的任务。
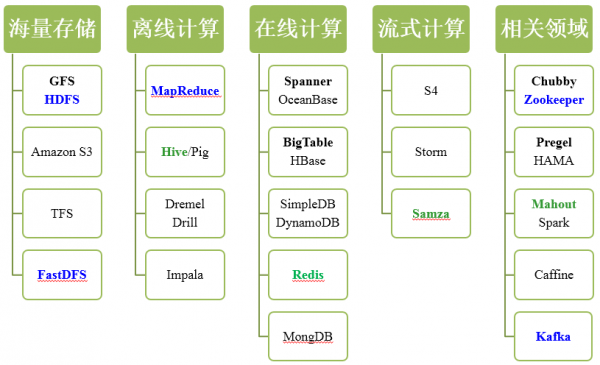
大数据的技术领域
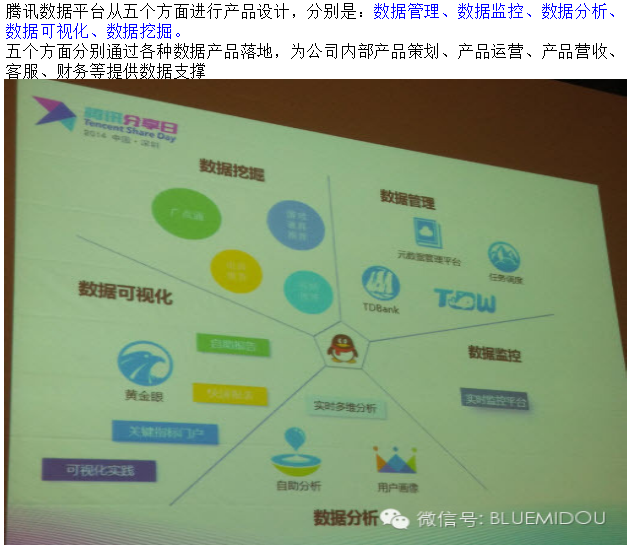
腾讯大数据现状(资料来自2014.4.11 腾讯分享日大会)


腾讯大数据平台产品架构
腾讯大数据平台与业务平台的关系

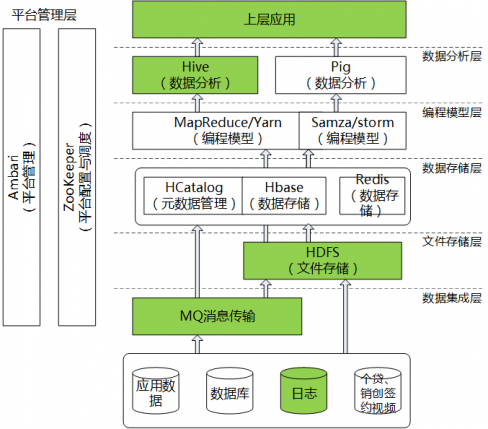
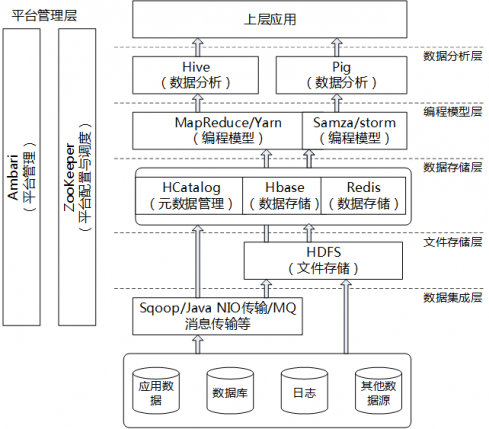
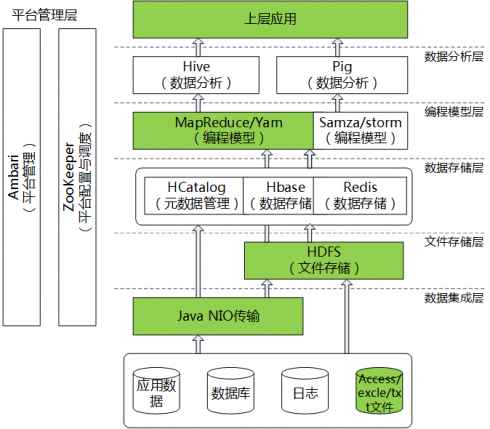
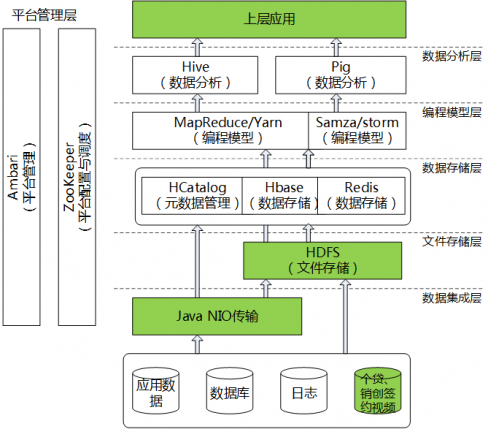
公司数据处理平台的基础架构

公司大数据平台架构图
应用一数据分析
应用二视频存储
应用三离线日志分析