一、在软件测试过程中,“测试用例的数目”、“测试的覆盖度”、“测试的效率”三者之间存在一定的关系。简要分析它们之间的折中性。
测试:
--> 在规定的条件下对程序进行操作,以发现程序错误,衡量软件品质,并对其是否能满足设计要求进行评估的过程。
测试用例:
--> 为某个特殊目标而编制的一组测试输入、执行条件以及预期结果,以便测试某个程序路径或核实是否满足某个特定需求。
覆盖度:
1.代码覆盖度
--> 基于代码的测试覆盖评测测试过程中已经执行的代码的多少,与之相对的是要执行的剩余代码的多少。
2.输入空间覆盖度
--> 参照模块的规格说明,测试用例占总输入空间的比例。
效率:
--> 成果(测试结果)/资源(测试时间空间)
综上,我们的目的在于实现较高的测试效率,而测试用例的数目与资源成正比,与覆盖度正相关,但与测试成果不成正比例关系,所以应该在保证测试成果的情况下减少资源的占用。即在保证测试效果(对于白盒测试来说,代码覆盖度也可以进行考量,但不是测试的本质目的)的前提下减少测试用例,例如使用输入空间分区的策略。
二、阅读《敏捷软件开发宣言》,并阐述敏捷思想在传统过程模型中为何无法做到?这些思想对软件开发带来的优势是什么?
>>> 什么是敏捷思想?
-
个体和互动高于流程和工具:团队应该自我进行组织和沟通,例如结对编程,并有明确的动机驱动开发。一个协作沟通的开发团优于一个孤立运行的专家团队。
-
工作的软件高于详尽的文档:一款工作的软件能比一份厚重的文档更能向用户呈现开发结果。开发时最好对代码做明智的注释而不是靠详细的文档来解释程序(文档也会很快过时)。
-
客户合作高于合同谈判:由于软件开发初期开发人员(甚至客户)都很难知晓真正的需求,所以开发团队应该直接接触用户或代理,从中获取反馈,并在此基础上不断明确、改变需求和开发方向。
-
响应变化高于遵循计划:软件开发的重点应该是相应市场变化而不是死板遵循合同。
>>> 传统开发的特点
-
强调文档对于团队成员的指导作用,开发人员是在不知道项目细节的情况下进行开发的。
-
将开软件开发过程分为可行性分析和项目开发计划、需求分析、概要设计、详细设计、编码、测试、维护七个阶段,每个阶段的输出是下一个阶段的输入。
-
开发计划一开始就已经订好,没有大量同客户的沟通交流。
>>> 敏捷思想在传统过程模型中为何无法做到?
-
传统软件开发是一个由文档进行驱动的过程。而敏捷思想强调以需求作为驱动。
-
传统软件开发是按照计划在线性模式下开发,开发人员必须要完成这个阶段的任务,并编写文档,然后才能进入下一个阶段。而敏捷思想强调迭代开发,每次迭代交付一些成果,关注业务优先级,检查与调整。
-
传统软件开发的测试阶段往往都是在整个代码编写完后才进行测试,假如在测试中发现问题,有可能要对整个模块进行修改。而敏捷思想强调以测试作为开发前提。
-
传统软件开发中,开发者只在初期与客户和市场交流。而敏捷思想强调随时交流,持续反馈。
>>> 这些思想对软件开发带来的优势是什么?
- 以人为本,强调客户和开发团队间的有效沟通和紧密协作,使得客户需求得到满足(可以等有价值的信息出现或对技术优化后才去决定)。
- 适应性较强,接受开发过程中需求的频繁修改,能有效地应对市场需求的变更。
- 通过增量迭代,每次都优先交付那能产生价值效益“不完全”功能,及时抢占竞争激烈的市场。并最大化单位成本收益。
三、学校发布了手机网上预约系统的招标公告,你所带领的小组获得此项目的开发权。目前项目开发中存在以下实际情况:你所带领的小组不是很熟悉手机系统的编程,并且对B/S和C/S结构的区别仅仅停留在书本上,缺少实际的开发经验。项目时间非常紧迫,考虑到教师和学生都需要此项目提供的功能,因此校方希望能够尽早的看到此项目的早期版本。校方提出了很多扩展要求,但是没有被包含到需求陈述中,因此后期可能会针对系统做出大量的调整和更改。请从“瀑布模型”、“原型模型”、“增量模型”三种模型中选择最适合此项目开发的过程模型,并简述选择原因。
项目要求:
- 时间紧,尽早看到早期版本。
- 后期用户提出大量的调整和更改。
- 不熟悉开发,对deadline不清楚。
瀑布模型:
--> 线性,通过一系列确定过程完成项目,容易使用,但是开发后期的改动开销会很大,同时无法拿出早期版本。不符合。
增量模型:
--> 线性,将项目分成各个小项目,逐次按照优先程度完成,但并不能在完成小项目以后看到一个早期版本,同时小项目开始开发后其要求就被“冻结”,无法从客户获得新的反馈。不符合。
原型模型:
--> 迭代,先构造一个项目原型,在该原型的基础上,逐渐完成整个开发工作。即首先建造一个快速原型,实现客户与系统的交互,用户或客户对原型进行评价,进一步细化待开发软件的需求。通过逐步调整原型使其满足客户的要求,开发人员可以确定客户的真正需求是什么;第二步则在第一步的基础上开发客户满意的软件产品。符合要求1和要求2,同时可以帮助开发人员确定deadline能否实现。
Ps.
缺少开发经验,对开发平台不了解,项目时间紧迫,后续扩展要求多,依然带领小组获得了项目开发权
--> 典型的为了出题而出题,看着想打人。
四、在面向对象的设计原则SOLID中,“依赖转置原则(DIP)”与“开放封闭原则(OCP)”之间有什么内在的联系?
DIP译为“依赖倒置”(inversion)似乎更合适。
以下摘录改编自:设计模式六大原则
1.依赖倒置原则(Dependency inversion principle)
定义:高层模块不应该依赖低层模块,二者都应该依赖其抽象;抽象不应该依赖细节;细节应该依赖抽象。
问题由来:类A直接依赖类B,假如要将类A改为依赖类C,则必须通过修改类A的代码来达成。这种场景下,类A一般是高层模块,负责复杂的业务逻辑;类B和类C是低层模块,负责基本的原子操作;假如修改类A,会给程序带来不必要的风险。
解决方案:将类A修改为依赖接口I,类B和类C各自实现接口I,类A通过接口I间接与类B或者类C发生联系,则会大大降低修改类A的几率。
依赖倒置原则基于这样一个事实:相对于细节的多变性,抽象的东西要稳定的多。以抽象为基础搭建起来的架构比以细节为基础搭建起来的架构要稳定的多。在java中,抽象指的是接口或者抽象类,细节就是具体的实现类,使用接口或者抽象类的目的是制定好规范和契约,而不去涉及任何具体的操作,把展现细节的任务交给他们的实现类去完成。
2.开闭原则( Open/closed principle)
定义:一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。
问题由来:在软件的生命周期内,因为变化、升级和维护等原因需要对软件原有代码进行修改时,可能会给旧代码中引入错误,也可能会使我们不得不对整个功能进行重构,并且需要原有代码经过重新测试。
解决方案:当软件需要变化时,尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有的代码来实现变化。
开闭原则就是想表达这样一层意思:用抽象构建框架,用实现扩展细节。因为抽象灵活性好,适应性广,只要抽象的合理,可以基本保持软件架构的稳定。而软件中易变的细节,我们用从抽象派生的实现类来进行扩展,当软件需要发生变化时,我们只需要根据需求重新派生一个实现类来扩展就可以了。前提是我们的抽象要合理,要对需求的变更有前瞻性和预见性。
综上,实现依赖倒置原则的实现其实就体现了开闭原则,例如当我们想添加C类功能时,由于类A依赖的是一个抽象接口,我们只需要依照结构添加一个新的类C即可(对扩展开放),而不是改动类A的代码(对修改关闭)。
Ps:
设计模式前五个原则,恰恰是告诉我们用抽象构建框架,用实现扩展细节的注意事项而已:单一职责原则告诉我们实现类要职责单一;里氏替换原则告诉我们不要破坏继承体系;依赖倒置原则告诉我们要面向接口编程;接口隔离原则告诉我们在设计接口的时候要精简单一;迪米特法则告诉我们要降低耦合。而开闭原则是总纲(实现效果),它告诉我们要对扩展开放,对修改关闭。
五、有三个开发者参与一个项目,A负责开发初始代码,B负责修复bug和优化代码,C负责测试并报告bug。项目的Git服务器为S,三人的本地Git仓库已经配置好远程服务器(名字均为origin)。项目的Git版本状态如图所示,三人的本地Git仓库的状态也是如此,其中包含主分支master,当前工作分支是master。
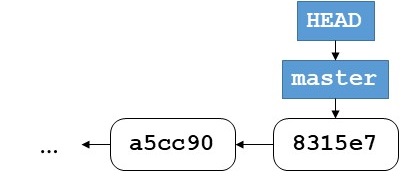
此时他们三人开展了以下工作:
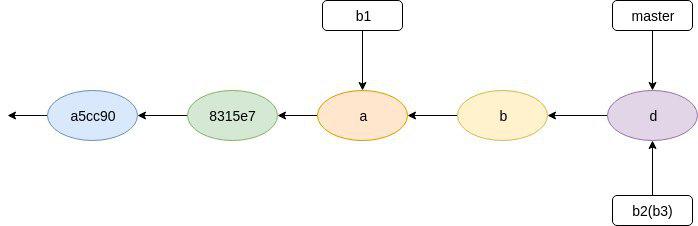
a) A开发了某项新功能,他创建了分支b1并在该分支上提交新代码,推送至服务器S;
b) C获取了A的提交,并在其上开辟了新分支b2,在b2上撰写测试程序并提交和推送至服务器S;
c) C在执行测试程序过程中发现了A的代码存在问题,C将bug信息报告给B;
d) B获取了C推送的包含测试程序的版本,在其基础上开辟了一个新分支b3用于bug修复,当B确认修改后的代码可通过所有测试用例之后,向Git做了一次提交,将b3合并到b2上并推送至服务器S;
e) C获取B的修复代码并重新执行其中包含的测试程序,确认bug已被修复,故将其合并到主分支master上,推送至服务器S,对外发布。
题目:
(1) 在图上补全上述活动结束后服务器S上的版本状态图(需注明各分支的名字与位置);
(2) 写出B为完成步骤d所需的全部Git指令,指令需包含完整的参数。
一般来说bug修复后分支会被删掉,但这里并没有明确是否删除b3,所以用两问中均以括号表示可能。另外这里使用Fast forward模式 合并分支。
-
-
步骤如下:
git pull
git checkout b2
git checkout -b b3
.....修复bug
git add ./
git commit -m "fixed the xxx bug"
git checkout b2
git merge b3
(git branch -d b3)
git push
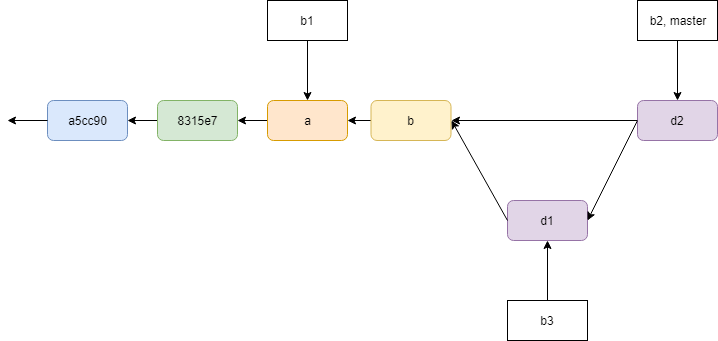
这里要注意的是,“将b3合并到b2”意味着 git checkout b2; git merge b3 而非 git checkout b3; git merge b2 ,这是由于b3的分支commit比b2更新,git不会允许你“回退”的,而是会提示“commit版本已是最新”。
如果想保留bug分支信息,可以采用非快速合并(git merge --no-ff):
六、比较static factory method、 factory method DP 和 abstract factory DP三者间的异同 abstract factory 和 builder bridge 和 strategy flyweight 和 pool
factory method DP 和 abstract factory DP:
factory method 和 abstract factory 形式的不同在于factory method是一个“method”,而abstract factory是一个对象接口。对于factory method来说,由于他是一个方法,所以可被子类型覆盖(例如实现接口或继承抽象类),从而将对象的实例化“延迟”交给子类完成,或者说使用者不需要关心子类的实现,而是关注对象的功能,通过调用工厂方法得到相应的对象。对于abstract factory对象来说,它不是“生产一个实例”,而是“生产一类组件的工厂”,亦即该对象中可以提供多个工厂接口,可以在不指定具体类的情况下提供关联或者独立组件。
它们之间的相同点在于不在将实例化的任务交给具体类本身的构造方法(new)完成,而是交给另外的工厂接口实现。
“static factory method”技术由Joshua Bloch在《Effective Java》中提出。其不是一个设计模式 —— “Note that a static factory method is not the same as the Factory Method pattern from Design Patterns. The static factory method described in thisitem has no direct equivalent in Design Patterns”。它的定义为“A class can providea public static factory method, which is simply a static method that returns an instance of the class.”从这个角度看,静态工厂方法也是将类的实现放到了别的地方实现,只不过是静态的,既无法在子类型里面覆盖。另外,这里也强调了这种静态方法返回的是静态方法所在的实例化对象。例如Boolean类中的静态工厂方法:
public static Boolean valueOf(boolean b) {
return b ? Boolean.TRUE : Boolean.FALSE;
}
所以,课程PPT上给出的静态工厂方法示例其实是使用了工厂方法模式的“变体静态工厂方法”:
public class TraceFactory1 {
public static Trace getTrace() {
return new SystemTrace();
}
}
说这里使用了工厂方法模式是因为它将Trace独立到TraceFactory及其子类实现,说是“变体静态工厂方法”是因为这里的静态工厂方法不是返回的当前类(TraceFactory1)的对象,而是返回了一个Trace对象。
abstract factory DP 和 builder DP:
abstract factory注重于“在不指定具体类的情况下提供一个可以产生一系列相关或独立组件的接口”,而builder注重于“将复杂对象的构造和其表示分离开来,并以此通过相同的构造过程获得不同表示的对象”。既前者通过工厂产生的是组件,后者是通过一个builder逐步构建,最终获得一个对应的可用对象。
两者的相同点在于都没有直接生成具体类型(new)。
bridge DP 和 strategy DP:
两者的不同在于bridge DP是一个结构设计模式,而strategy DP是一个行为设计模式。其中bridge关注于“将抽象与实现解耦,以便两者可以独立变化”,而strategy关注于“对于一个操作,可以在运行时决定使用的算法或行为”。
由于两者不是同一类设计模式,无法比较相同点,不过在使用strategy DP的时候,由于要运行时决定算法,其实现必须是与表示解耦的(而非直接使用具体的算法),这就使用到了bridge DP。
flyweight DP 和 pool DP(来自课件PPT):
原理不同:object pool的原理是复用,pool中object被取出后,只能由一个client使用;flyweight的原理是共享,一个object可被多个client同时使用。对象性质不同:object pool中的对象是同质的,对于client来说,可以用pool中的任何一个object。如:需要connection时可以从connection pool中任意的拿一个出来使用;Flyweight的每一个实例的内部属性相同,但是外部属性不同,是异质的。flyweight使用时,是去Flyweight-Factory中找一个特定的对象出来(如果没有的话,就创建一个)。应用场合不同:object pool对应的场景是对象被频繁创建、使用,然后销毁。每个对象的生命期都很短。同一时刻内,系统中存在的对象数也比较小。Flyweight对应的情况是在同一时刻内,系统中存在大量对象。
相同点在于两者都是让多个索引(重复)利用同一个对象或同一个对象集合,提高内存的使用效率,减少GC。
七、结合自己之前所参与的某个软件项目,阐述用户提出哪些NFR,它们之间有何折中,以及你是如何应对的。
软件项目(比赛的作品):“基于Apache Ignite的分布式医疗数据学习框架”
主要用户:医院
NFR:portability, performance, ease of use, security, maintainability, economy
折中及应对策略:
1.(performance && economy) vs. portability
>> 一开始用户打算在数据收集端/感应器就建立学习框架(ARM架构),然后构建一个协调分配的中心,该中心负责数据的存储和分配(x86架构)。但是在开发的过程中发现Apache Ignite在计算节点增加时其性能会显著下降(很多资源用来处理任务协调),而数据收集端的数量在未来应该会变得比较多,同时分别在两个框架部署也会增大工作量。经过考虑,我们认为性能和经济(开发时间)更加重要,数据收集端只应完成数据收集的任务(不部署计算节点),而数据的整理和计算交给计算能力更强的中心负责。
-> performance && economy 100%
2.maintainability vs. economy
>> 由于用户大多为医护人员,而对于数据的维护工作也常常不能由开发人员进行,所以一个方便抽象的管理平台是必要的,但是这也会增加我们的工作量。经过考虑,我们认为如果维护工作不做好,该软件的计算结果都有可能受到影响,即软件的正确性难以保证,所以维护性必须认真对待。最后我们的方案是使用JavaFX开发出一套图形界面管理平台,用户只需要观察平台上的情况和报告,通过经验使用已经建立好的处理方法就能维护数据了。而JavaFX和Apache Ignite的解耦和也做的很好,可以分别同步开发。
-> 70% maintainability vs. 30% economy
3.security vs. ease of use
>> 患者的病历中既有宝贵的医疗资料,也有关乎患者隐私的数据,所以对于软件访问的控制也是很重要的。为了达到合理的安全性,我们采取了权限分配、日志记录、数据隔离、传输加密等措施。但是这些措施也对易用性产生了影响。通过考虑,我们认为隐私数据的保护和追责性是本软件的一个重要底线,所以易用性应该很大程度上让位于位于安全性。而对于易用性的补充,我们采取了秘钥分发的措施,一定程度上增加了易用性。
-> 90% security vs. 10% ease of use
八、结合子类型和多态的知识,了解java中的协变和逆变:
1.数组的协变性
2.泛型中的协变和逆变
3.如何理解:函数f可以安全替换函数g,要求函数f接受更一般的参数类型,返回更特化的结果类型(输入类型是逆变,输出类型协变)
逆变与协变:如果A、B表示类型,f(⋅)表示类型转换,≤表示继承关系(比如,A≤B表示A是由B派生出来的子类):
f(⋅)是逆变(contravariant)的,当A≤B时有f(B)≤f(A)成立;
f(⋅)是协变(covariant)的,当A≤B时有f(A)≤f(B)成立;
f(⋅)是不变(invariant)的,当A≤B时上述两个式子均不成立,即f(A)与f(B)相互之间没有继承关系。
1.数组的协变性
在Java中数组是具有协变性的,如果B是A的子类型,则B[]是A[]的子类型(f(⋅)映射为数组),即子类型的数组可以赋予父类型的数组进行使用,但数组的类型实际为子类型。例如:
Fruit[] fruits = new Apple[10]; // subclass of fruits
fruits[0] = new Apple();
fruits[1] = new RedFujiApple(); // subclass of Apple
这里fruits所引用的数组其实是Apple[]类型。
从协变数组读取元素是完全安全的,无论是编译期还是运行时,都不会发生任何问题:
Fruit fruit = fruits[0]; // return an Apple, which is the subclass of Fruit
但是将Fruit类型以及其子类型的元素写入到协变数组fruits中是有可能在运行时出现问题的,因为Apple类型无接受Fruit类型和其它非Apple的子类型(编译器无法检查):
fruits[0] = new Fruit(); // java.lang.ArrayStoreException
fruits[0] = new Orange(); //subclass of Fruit, java.lang.ArrayStoreException
这是Java数组的“缺陷”,在利用数组的协变性时,应该尽量把协变数组当作只读数组使用。
2.泛型中的协变和逆变
Java中泛型是不变的,但可以通过通配符"?"实现协变和逆变:
<? extends>实现了泛型的协变:
List<? extends Number> list = new ArrayList<Integer>();