存储引擎在MySQL的逻辑架构中位于第三层,负责MySQL中的数据的存储和提取。MySQL存储引擎有很多,不同的存储引擎保存数据和索引的方式是不同的。每一种存储引擎都有它的优势和劣势,本文只讨论最常见的InnoDB和MyISAM两种存储引擎进行讨论。本文中关于数据存储形式和索引的可以查看图解MySQL索引
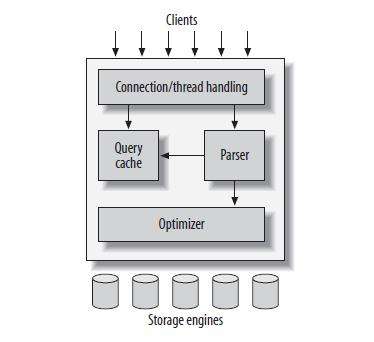
MySQL逻辑架构图:
InnoDB存储引擎
InnoDB是默认的事务型存储引擎,也是最重要,使用最广泛的存储引擎。在没有特殊情况下,一般优先使用InnoDB存储引擎。
1️⃣、数据存储形式
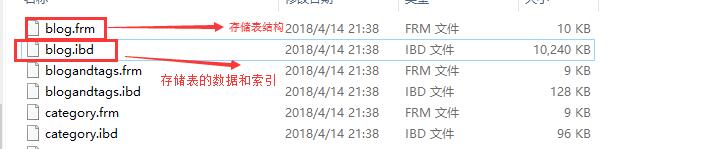
使用InnoDB时,会将数据表分为.frm 和 idb两个文件进行存储。
2️⃣、锁的粒度
InnoDB采用MVCC(多版本并发控制)来支持高并发,InnoDB实现了四个隔离级别,默认级别是REPETABLE READ,并通过间隙锁策略防止幻读的出现。它的锁粒度是行锁。【通过MVCC实现,MVCC在稍后会进行介绍】
3️⃣、事务
InnoDB是典型的事务型存储引擎,并且通过一些机制和工具,支持真正的热备份。
4️⃣、数据的存储特点
InnoDB表是基于聚簇索引(另一篇博客有介绍)建立的,聚簇索引对主键的查询有很高的性能,不过他的二级索引(非主键索引)必须包含主键列,索引其他的索引会很大。
MyISAM存储引擎
1️⃣、数据存储形式
MyISAM采用的是索引与数据分离的形式,将数据保存在三个文件中.frm.MYD,.MYIs。

2️⃣、锁的粒度
MyISAM不支持行锁,所以读取时对表加上共享锁,在写入是对表加上排他锁。由于是对整张表加锁,相比InnoDB,在并发写入时效率很低。
3️⃣、事务
MyISAM不支持事务。
4️⃣、数据的存储特点
MyISAM是基于非聚簇索引进行存储的。
5️⃣、其他
MyISAM提供了大量的特性,包括全文索引,压缩,空间函数,延迟更新索引键等。
进行压缩后的表是不能进行修改的,但是压缩表可以极大减少磁盘占用空间,因此也可以减少磁盘IO,从而提供查询性能。
全文索引,是一种基于分词创建的索引,可以支持复杂的查询。
延迟更新索引键,不会将更新的索引数据立即写入到磁盘,而是会写到内存中的缓冲区中,只有在清除缓冲区时候才会将对应的索引写入磁盘,这种方式大大提升了写入性能。
三、对比与选择
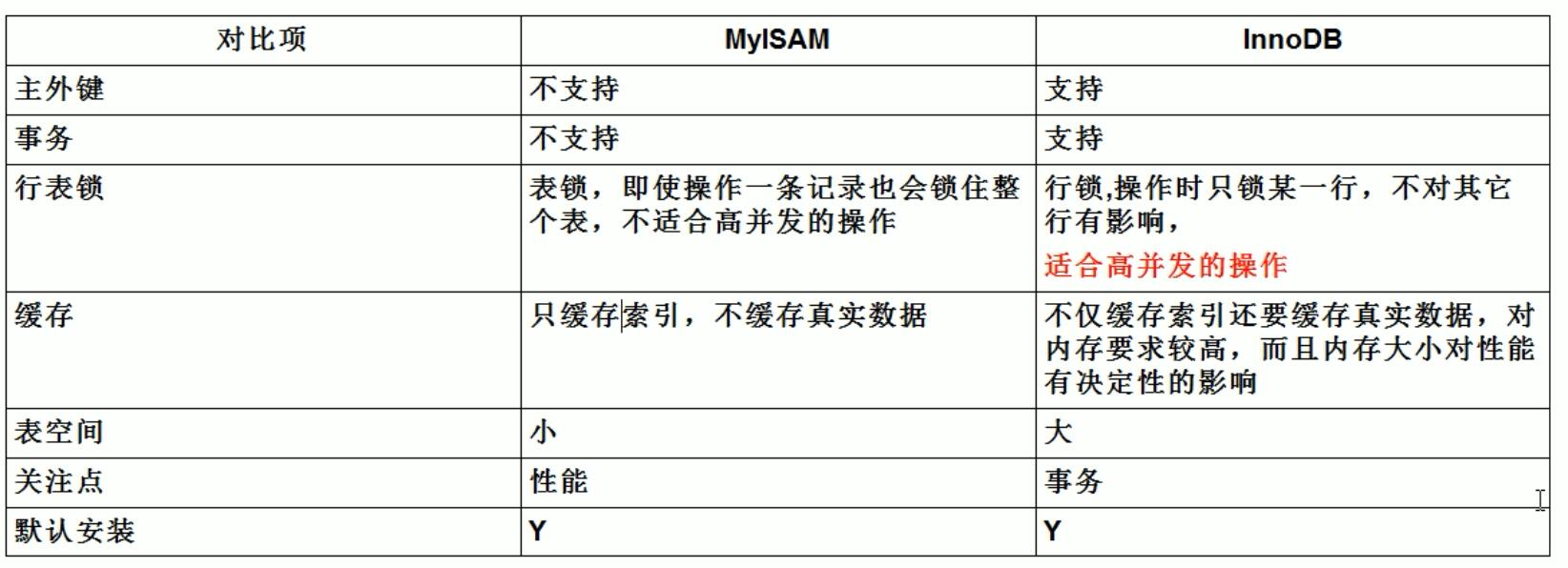
两种存储引擎各有各的有点,MyISAM专注性能,InnoDB专注事务。两者最大的区别就是InnoDB支持事务,和行锁。
如何在两种存储引擎中进行选择?
① 是否有事务操作?有,InnoDB。
②是否存储并发修改?有,InnoDB。
③是否追求快速查询,且数据修改较少?是,MyISAM。
④是否使用全文索引?如果不引用第三方框架,可以选择MyISAM,但是可以选用第三方框架和InnDB效率会更高。
四、浅谈MVCC
MySQL大多数事务型存储引擎实现的都不是简单的行锁。基于提升并发性能的考虑,他们一般都同时实现了多版本并发控制(MVCC)。
可以认为MVCC是行级锁的一个变种,它能在大多数情况下避免加锁操作,因此开销更低。无论怎样实现,它们大豆实现了非阻塞的读操作,写操作也只锁定制定的行。
MVCC是通过保存数据在某一个时间点的快照来实现的,也就是说无论事务执行多久,每个事务看到的数据都是一致的。InnoDB的MVCC,是通过在每行记录后面保存两个隐藏的列来实现,这两个列一个保存了行的创建时间,一个保存了行的过期时间(或删除时间),当然,并非存储的是时间,而是系统版本号。每开启一个事务,版本号都会递增,事务开始时刻的系统版本号会作为事务的版本号。
| id | name | 创建时间(行版本号) | 删除时间(删除版本号) |
|---|---|---|---|
| 1 | Mary | 1 | null |
| 2 | Jann | 1 | null |
以InnoDB存储引擎的的REPEATABLE READ隔离级别来说:
SELECT
①只查询创建时间版本号小于当前事务版本号的数据行(保证事务读取的行要么在事务开始之前就存在,要么是事务本身插入的行)
②行的删除版本号要么未定义,要么大于当前事务版本号,这样可以确保事务读取到的行,在开始事务之前未被删除
只有复合上诉两个条件的记录才会作为结果返回
INSERT
为插入的数据保存当前系统版本号作为行版本号
DELETE
保存当前系统版本号作为删除行版本号
UPDATE
插入一行数据,并将当前系统版本号赋予行版本号;同事保存当前系统版本号到原来的行作为删除版本号。
注:MVCC只在REPEATABLE和READ COMMITTED两个隔离级别下才能正常工作。
我的个人博客:李强的个人博客(基于SSM,Nginx+Redis的后台架构)