1.1.HDFS.
它是一个分布式文件管理系统,用来存储文件,通过目录树来定位文件;由多个服务器联合起来实现功能,集群中的服务器有各自的角色。
适用场景:适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据的分析,并不适合用来做网盘应用。
1.1.1NameNode:就是master,它是一个主管。管理者。
(1)管理HDFS的名称空间; (2)配置副本策略;
(3)管理数据块映射信息 (4)处理客户端读写请求
1.1.2DateNode:就是Slave。NameNode下达命令,DateNode执行实际的操作。
(1)存储实际的数据块 (2)执行数据块的读写操作
1.1.3Client:就是客户端。
(1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传;
(2)与NameNode交互,获取文件的位置信息
(3)与DataNode交互,读取或者写入数据;
(4)Client提供一些命令来管理HDFS,比如NameNode格式化;
(5)Client可以通过一些命令来访问HDFS,比如对HDFS增删改查操作;
1.1.4SecondaryNameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
(1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode;
(2)在紧急情况下,可辅助恢复NameNode。
 把本地e盘上的banhua.txt文件上传到HDFS根目录
把本地e盘上的banhua.txt文件上传到HDFS根目录
从HDFS上下载banhua.txt文件到本地e盘上HDFS写数据流程,如图3-8所示。
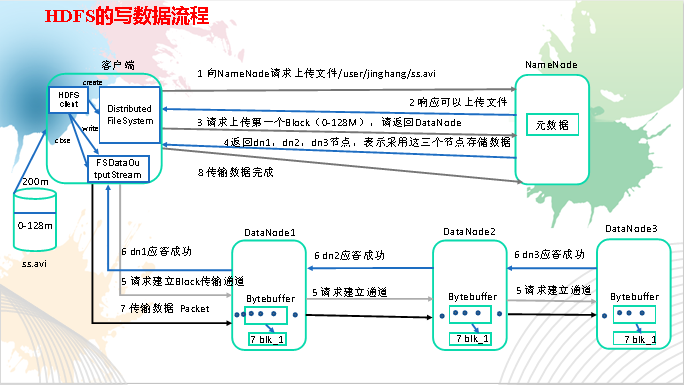
1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
2)NameNode返回是否可以上传。
3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
网络拓扑-节点距离计算
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。
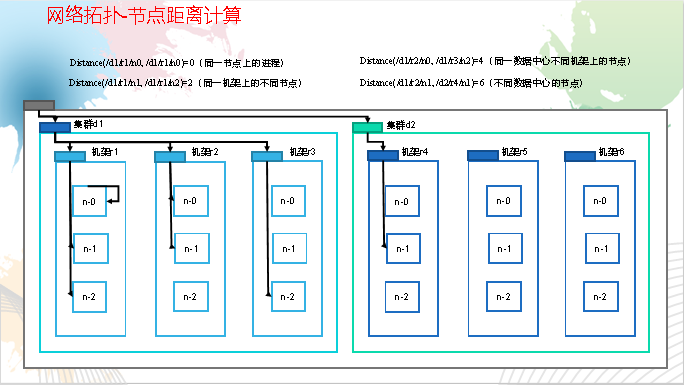
Hadoop2.7.2副本节点选择

HDFS读数据流程

1)客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
NameNode和SecondaryNameNode(面试开发重点)
5.1 NN和2NN工作机制
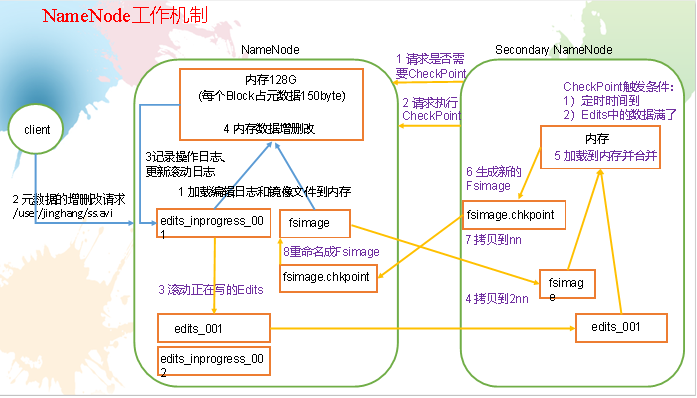
1. 第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对元数据进行增删改。
2. 第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。

CheckPoint时间设置
(1)通常情况下,SecondaryNameNode每隔一小时执行一次。
[hdfs-default.xml]
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
(2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property >
集群安全模式


- 基本语法
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
DataNode工作机制

1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
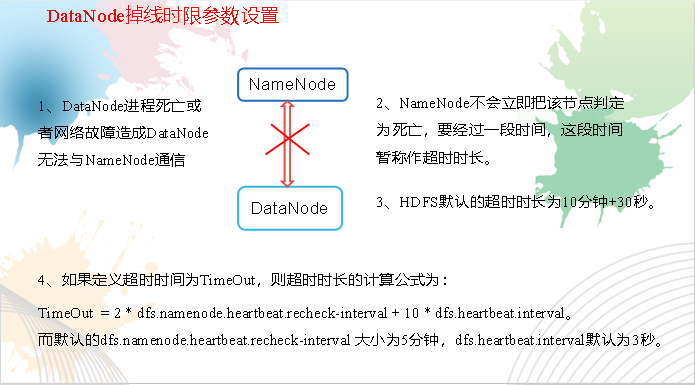
3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器。
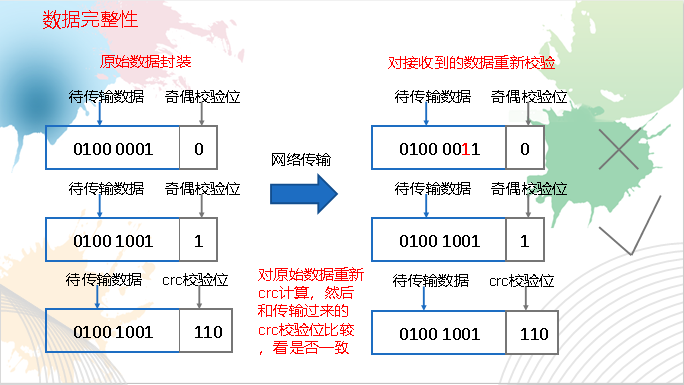
数据完整性
1)当DataNode读取Block的时候,它会计算CheckSum。
2)如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。
3)Client读取其他DataNode上的Block。
4)DataNode在其文件创建后周期验证CheckSum,如图3-16所示。
掉线时限参数设置
退役旧数据节点
添加白名单
添加到白名单的主机节点,都允许访问NameNode,不在白名单的主机节点,都会被退出。
配置白名单的具体步骤如下:
(1)在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts文件
[jinghang@hadoop102 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[jinghang@hadoop102 hadoop]$ touch dfs.hosts
[jinghang@hadoop102 hadoop]$ vi dfs.hosts
添加如下主机名称(不添加hadoop105)
hadoop102
hadoop103
hadoop104
(2)在NameNode的hdfs-site.xml配置文件中增加dfs.hosts属性
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value>
</property>
(3)配置文件分发
[jinghang@hadoop102 hadoop]$ xsync hdfs-site.xml
(4)刷新NameNode
[jinghang@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
(5)更新ResourceManager节点
[jinghang@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
17/06/24 14:17:11 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8033
(6)在web浏览器上查看
黑名单退役
在黑名单上面的主机都会被强制退出。
1.在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts.exclude文件
[jinghang@hadoop102 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[jinghang@hadoop102 hadoop]$ touch dfs.hosts.exclude
[jinghang@hadoop102 hadoop]$ vi dfs.hosts.exclude
添加如下主机名称(要退役的节点)
hadoop105
2.在NameNode的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.exclude</value>
</property>
3.刷新NameNode、刷新ResourceManager
[jinghang@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[jinghang@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
17/06/24 14:55:56 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8033
4. 检查Web浏览器,退役节点的状态为decommission in progress(退役中),

Datanode多目录配置
DataNode也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本
2.具体配置如下
hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value>
</property>
小文件存档
