MySQL-day02
查询表记录
-- 准备数据: 以下练习将使用db10库中的表及表记录,请先进入db10数据库!!!
基础查询
SELECT 语句用于从表中选取数据。结果被存储在一个结果表中(称为结果集)。
语法:SELECT 列名称 | * FROM 表名
提示:(1) *(星号)为通配符,表示查询所有列。
(2)但使用 *(星号)有时会把不必要的列也查出来了,并且效率不如直接指定列名
-- 15.查询emp表中的所有员工,显示姓名,薪资,奖金
select * from emp;
select name,sal,bonus from emp;
-- 16.查询emp表中的所有部门和职位
select dept,job from emp;
思考:如果查询的结果中,存在大量重复的记录,如何剔除重复记录,只保留一条? */
-- 在select之后、列名之前,使用DISTINCT 剔除重复的记录
select distinct dept,job from emp; -- 去除重复记录
WHERE子句查询
WHERE子句查询语法:SELECT 列名称 | * FROM 表名称 WHERE 列 运算符 值
WHERE子句后面跟的是条件,条件可以有多个,多个条件之间用连接词(or | and)进行连接
下面的运算符可在 WHERE 子句中使用:
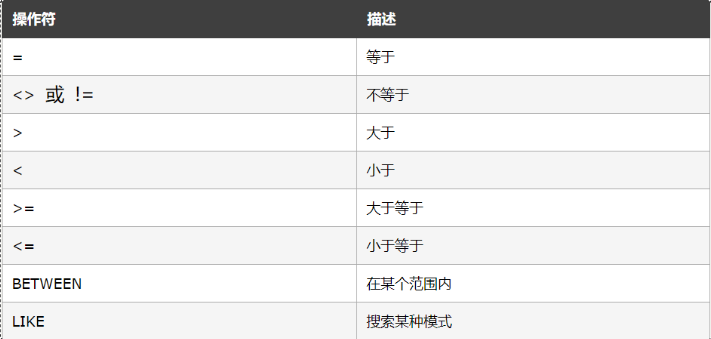
-- 17.查询emp表中【薪资大于3000】的所有员工,显示员工姓名、薪资
select name,sal from emp where sal>3000;
-- 18.查询emp表中【总薪资(薪资+奖金)大于3500】的所有员工,显示员工姓名、总薪资
select name,sal+bonus from emp
where sal+bonus>3500; -- 错误!
-- ifnull(列名, 值)函数: 判断指定的列是否包含null值,如果有null值,用第二个值替换null值
select name,sal+ifnull(bonus,0) from emp
where sal+ifnull(bonus,0) > 3500;
-- 注意查看上面查询结果中的表头,如何将表头中的 sal+bonus 修改为 "总薪资"
-- 使用as可以为表头指定别名
select name as 姓名,sal+ifnull(bonus,0) as 总薪资 from emp
where sal+ifnull(bonus,0) > 3500;
-- 另外as可以省略
select name 姓名,sal+ifnull(bonus,0) 总薪资 from emp
where sal+ifnull(bonus,0) > 3500;
-- 在where子句中不能使用列别名
-- 19.查询emp表中【薪资在3000和4500之间】的员工,显示员工姓名和薪资
select name,sal from emp
where sal>=3000 and sal<=4500;
-- 提示: between...and... 在...和...之间
select name,sal from emp
where sal between 3000 and 4500;
-- 20.查询emp表中【薪资为 1400、1600、1800】的员工,显示员工姓名和薪资
select name,sal from emp
where sal=1400 or sal=1600 or sal=1800;
-- 或者
select name,sal from emp
where sal in(1400,1600,1800);
-- 21.查询薪资不为1400、1600、1800的员工,显示员工姓名和薪资
方式一:
select name,sal from emp
where sal!=1400 and sal!=1600 and sal!=1800
方式二:
select name,sal from emp
where not(sal=1400 or sal=1600 or sal=1800);
方式三:
select name,sal from emp
where sal not in(1400,1600,1800);
-- 22.(自己完成) 查询emp表中薪资大于4000和薪资小于2000的员工,显示员工姓名、薪资。
select name,sal from emp
where sal>4000 or sal<2000;
-- 23.(自己完成) 查询emp表中薪资大于3000并且奖金小于600的员工,显示员工姓名、薪资、奖金。
select name,sal,bonus from emp
where sal>3000 and bonus<600; -- 不处理null值,结果有误!
-- 处理null值
select name,sal,bonus from emp
where sal>3000 and ifnull(bonus,0)<600; -- 处理null值
-- 24.查询没有部门的员工(即部门列为null值)
select * from emp
where dept is null;
-- 思考:如何查询有部门的员工(即部门列不为null值)
select * from emp where not(dept is null);
select * from emp where dept is not null;
模糊查询
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。
可以和通配符(%、_)配合使用,其中"%"表示0或多个任意的字符,"_"表示一个任意的字符。
语法:SELECT 列 | * FROM 表名 WHERE 列名 LIKE 值
示例:
-- 25.查询emp表中姓名中以"刘"字开头的员工,显示员工姓名。
select name from emp
where name like '刘%'; -- 以'刘'开头
select name from emp
where name like '%涛'; -- 以'涛'结尾
-- 26.查询emp表中姓名中包含"涛"字的员工,显示员工姓名。
select name from emp
where name like '%涛%'; -- %匹配0或多个任意字符
-- 27.查询emp表中姓名以"刘"开头,并且姓名为两个字的员工,显示员工姓名。
select name from emp
where name like '刘_'; -- _表示匹配一个任意字符
select name from emp
where name like '刘__'; -- 以'刘'开头,并且姓名为两个字
多行函数查询
多行函数也叫做聚合(聚集)函数,根据某一列或所有列进行统计。
常见的多行函数有:
| 多行函数 | 作用 |
|---|---|
| COUNT( 列名 | * ) | 统计结果集中指定列的记录的行数。 |
| MAX( 列名 ) | 统计结果集中某一列值中的最大值 |
| MIN( 列名 ) | 统计结果集中某一列值中的最小值 |
| SUM( 列名 ) | 统计结果集中某一列所有值的和 |
| AVG( 列名 ) | 统计结果集中某一列值的平均值 |
提示:(1)多行函数不能用在where子句中
(2)多行函数和是否分组有关,分组与否会直接影响多行函数的执行结果。
(3)多行函数在统计时会对null值进行过滤,直接将null值丢弃,不参与统计。
-- 28.统计emp表中薪资大于3000的员工个数
select count(*) from emp where sal>3000; -- count统计查询的结果有多少行
-- 29.求emp表中的最高薪资
select sal from emp; -- 求所有薪资
select max(sal) from emp; -- 统计最高薪资
select min(sal) from emp; -- 统计最低薪资
select name, max(sal) from emp; -- 错误写法!name是整个结果中的第一个name,和最高薪资很可能不对应。
-- 30.统计emp表中所有员工的薪资总和(不包含奖金)
select sum(sal) from emp; -- 统计薪资这一列中所有值的和
select sum(bonus) from emp; -- 统计奖金这一列中所有值的和,多行函数会处理null值
select sum( ifnull(bonus,0) ) from emp;
-- 31.统计emp表员工的平均薪资(不包含奖金)
select avg(sal) from emp;
select sum(sal) / count(*) from emp;
多行函数需要注意的问题:
-
多行函数和是否分组有关,如果查询结果中的数据没有经过分组,默认整个查询结果是一个组,多行函数就会默认统计当前这一个组的数据。产生的结果只有一个。
-
如果查询结果中的数据经过分组(分的组不止一个),多行函数会根据分的组进行统计,有多少个组,就会统计出多少个结果。
例如:统计emp表中的人数(将emp表中的所有员工看作一个组)
select count(*) from emp;
结果返回的就是emp表中的所有人数
再例如:根据性别进行分组,再统计emp表中每组的人数,显示性别和对应人数
select gender,count(*) from emp group by gender;
分组查询
GROUP BY 语句根据一个或多个列对结果集进行分组。
在分组的列上我们可以使用 COUNT,SUM,AVG,MAX,MIN等函数。
语法:SELECT 列 | * FROM 表名 [WHERE子句] GROUP BY 列;
-- 32.对emp表,按照部门对员工进行分组,查看分组后效果。
select * from emp group by dept;
-- 33.对emp表按照职位进行分组,并统计每个职位的人数,显示职位和对应人数
select job,count(*) from emp group by job;
-- 34.对emp表按照部门进行分组,求每个部门的最高薪资(不包含奖金),显示部门名称和最高薪资
select dept,max(sal) from emp group by dept;
排序查询
使用 ORDER BY 子句将结果集中记录根据指定的列排序后再返回
语法:SELECT 列名 FROM 表名 ORDER BY 列名 [ASC|DESC]
ASC(默认)升序,即从低到高;DESC 降序,即从高到低。
-- 35.对emp表中所有员工的薪资进行升序(从低到高)排序,显示员工姓名、薪资。
select name,sal from emp order by sal asc; -- 按照薪资升序(从低到高)排序
select name,sal from emp order by sal; -- asc是默认值,可以省略
-- 36.对emp表中所有员工的奖金进行降序(从高到低)排序,显示员工姓名、奖金。
select name, bonus from emp order by bonus desc; -- 按照奖金降序排序
-- 根据奖金降序排序, 如果奖金相同, 再按照薪资升序排序
select name,bonus,sal from emp order by bonus desc, sal asc;
分页查询
在mysql中,通过limit进行分页查询:
limit (页码-1)*每页显示记录数, 每页显示记录数
-- 37.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 1 页。
select * from emp limit 0,3; -- 每页3条,返回第1页
select * from emp limit 3,3; -- 每页3条,返回第2页
select * from emp limit 6,3; -- 每页3条,返回第3页
select * from emp limit 9,3; -- 每页3条,返回第4页
...
-- 38.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 2 页。
select * from emp limit 3,3; -- 每页3条,返回第2页
-- 补充练习:求emp表中薪资最高的前3名员工的信息,显示姓名和薪资
select name,sal from emp order by sal desc limit 0,3;
其他函数
| 函数名 | 解释说明 |
|---|---|
| curdate() | 获取当前日期,格式是:年月日 |
| curtime() | 获取当前时间 ,格式是:时分秒 |
| sysdate()/now() | 获取当前日期+时间,格式是:年月日 时分秒 |
| year(date) | 返回date中的年份 |
| month(date) | 返回date中的月份 |
| day(date) | 返回date中的天数 |
| hour(date) | 返回date中的小时 |
| minute(date) | 返回date中的分钟 |
| second(date) | 返回date中的秒 |
| CONCAT(s1,s2..) | 将s1,s2 等多个字符串合并为一个字符串 |
| CONCAT_WS(x,s1,s2..) | 同CONCAT(s1,s2,..)函数,但是每个字符串之间要加上x,x是分隔符 |
-- 39.查询emp表中所有【在1993和1995年之间出生】的员工,显示姓名、出生日期。
select name,birthday from emp
where birthday between 1993 and 1995; -- 错误!birthday是年月日格式,无法和年份比较
-- ---------------------------------
select name,birthday from emp
where birthday between '1993-1-1' and '1995-12-31'; -- 正确
-- ---------------------------------
select name,birthday from emp
where year(birthday) between 1993 and 1995; -- 正确
-- 40.查询emp表中本月过生日的所有员工
-- 如何获取本月:month( curdate() )
-- 如何员工的出生月份:month( birthday )
select * from emp
where month( birthday ) = month( curdate() );
-- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
select name,concat(sal,'(元)') from emp;
-- 补充练习:查询emp表中员工的姓名和薪资(薪资格式为: xxx/元 )
select name,concat(sal,'/元') from emp;
select name,concat_ws('/',sal,'元') from emp;
表关系
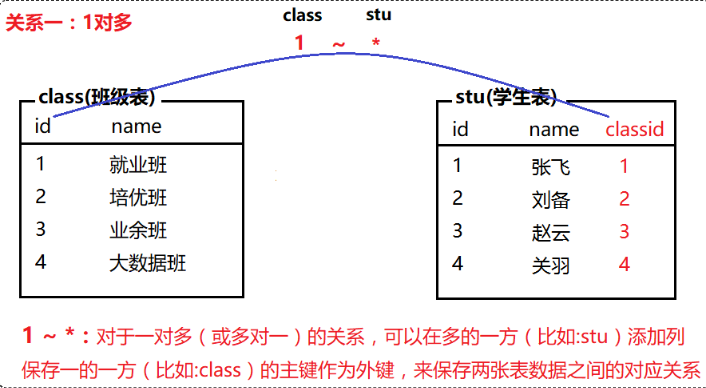
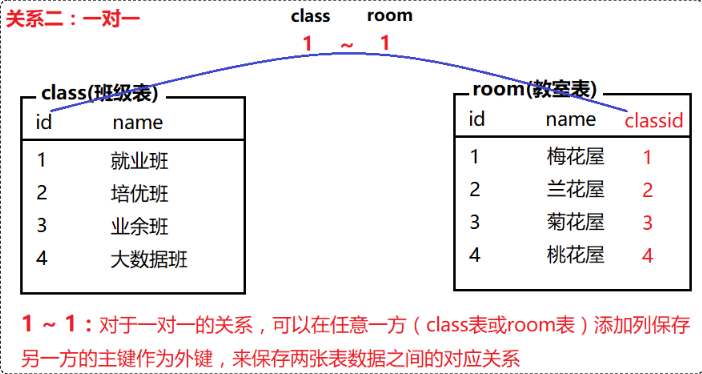
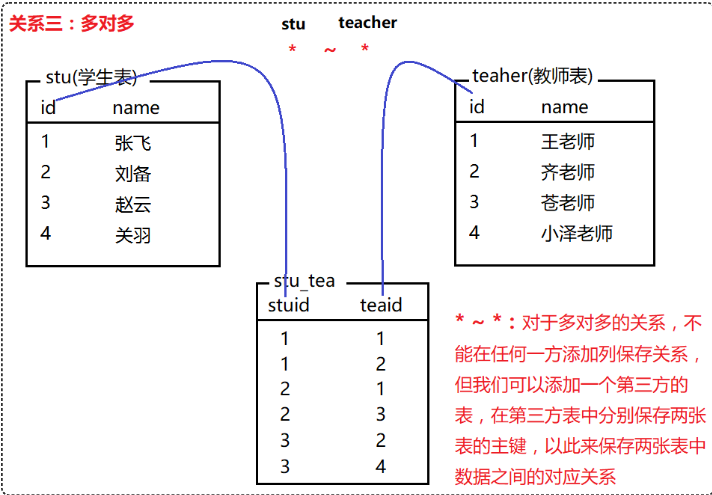
常见的表关系分为以下三种:
一对多(多对一)、一对一、多对多
多表查询
-- 准备数据: 以下练习将使用db30库中的表及表记录,请先进入db30数据库!!!
连接查询
-- 42.查询部门和部门对应的员工信息
select * from dept,emp;
上面的查询中存在大量错误的数据,一般我们不会直接使用这种查询。
笛卡尔积查询:所谓笛卡尔积查询就是指,查询两张表,其中一张表有m条记录,另一张表有n条记录,查询的结果是m*n条。
虽然笛卡尔积查询中包含大量错误数据,但我们可以通过where子句将错误数据剔除,保留下来的就是正确数据。
-- 条件: 员工所属的部门编号等于部门的编号
select * from dept,emp
where emp.dept_id=dept.id;
通过where子句将笛卡尔积查询中的错误数据剔除,保留正确的数据,这就是连接查询!
上面的查询可以换成下面的查询:
select * from dept inner join emp
on emp.dept_id=dept.id; -- 内连接查询
左外连接查询
-- 43.查询所有部门和部门下的员工,如果部门下没有员工,员工显示为null
select * from dept left join emp
on emp.dept_id=dept.id; -- 左外连接查询,会将左边表中的数据全部查询出来

左外连接查询:可以将左边表中的所有记录都查询出来,右边表只显示和左边相对应的数据,如果左边表中某些记录在右边没有对应的数据,右边显示为null即可。
右外连接查询
-- 44.查询部门和所有员工,如果员工没有所属部门,部门显示为null
select * from dept right join emp
on emp.dept_id=dept.id; -- 右外连接查询,会将右边表中的数据全部查询出来

右外连接查询:可以将右边表中的所有记录都查询出来,左边表只显示和右边相对应的数据,如果右边表中某些记录在左边没有对应的数据,可以显示为null。
扩展:如果想将两张表中的所有数据都查询出来(左外+右外并去除重复记录),可以使用全外连接查询,但是mysql又不支持全外连接查询。
可以使用union将左外连接查询的结果和右外连接查询的结果合并在一起,并去除重复的记录。例如:

需要注意的是:union可以将两条SQL语句执行的结果合并有前提:
(1)两条SQL语句查询的结果列数必须一致
(2)两条SQL语句查询的结果列名、顺序也必须一致
并且union默认就会将两个查询中重复的记录去除(如果不希望去除重复记录,可以使用union all)
子查询练习
-- 准备数据:以下练习将使用db40库中的表及表记录,请先进入db40数据库!!!
-- 45.列出薪资比'王海涛'的薪资高的所有员工,显示姓名、薪资
-- 求出'王海涛'的薪资
select sal from emp where name='王海涛'; -- 2450
-- 列出比'王海涛'薪资还高的员工
select name,sal from emp
where sal>(select sal from emp where name='王海涛');
-- 46.列出与'刘沛霞'从事相同职位的所有员工,显示姓名、职位。
-- 求出'刘沛霞'的职位
select job from emp where name='刘沛霞'; -- 推销员
-- 求出和'刘沛霞'从事相同职位的员工
select name,job from emp
where job=(select job from emp where name='刘沛霞');
-- 47.列出薪资比'大数据部'部门(已知部门编号为30)所有员工薪资都高的员工信息,显示员工姓名、薪资和部门名称。
如果不考虑没有部门的员工
-- 1、连接查询员工和部门
select e.name,e.sal,d.name from dept d,emp e
where e.dept_id=d.id;
-- 2、求出大数据部门的最高薪资(查询员工表中部门编号为30的最高薪资)
select max(sal) from emp where dept_id=30;
-- 3、求出比大数据部门最高薪资还高的员工信息
select e.name,e.sal,d.name from dept d,emp e
where e.dept_id=d.id
and sal>(select max(sal) from emp where dept_id=30);
如果加上没有部门的员工
-- 1、用外连接查询所有员工和对应的部门
select e.name,e.sal,d.name from dept d right join emp e
on e.dept_id=d.id;
-- 2、求出大数据部门的最高薪资
select max(sal) from emp where dept_id=30;
-- 3、求出比大数据部门最高薪资还高的员工信息
select e.name,e.sal,d.name from dept d right join emp e
on e.dept_id=d.id and
sal>3000;
多表查询练习
-- 48.列出在'培优部'任职的员工,假定不知道'培优部'的部门编号,显示部门名称,员工名称。
-- 关联查询两张表
select d.name,e.name from dept d, emp e
where e.dept_id=d.id;
-- 求出在培优部的员工
select d.name,e.name from dept d, emp e
where e.dept_id=d.id and d.name='培优部';
-- 49.(自查询)列出所有员工及其直接上级,显示员工姓名、上级编号,上级姓名
/* emp e1 员工表, emp e2 上级表
* 查询的表: emp e1, emp e2
* 显示的列: e1.name, e2.id, e2.name
* 连接条件: e1.topid=e2.id
*/
select e1.name, e2.id, e2.name
from emp e1, emp e2
where e1.topid=e2.id;
-- 50.列出最低薪资大于1500的各种职位,显示职位和该职位的最低薪资
-- 根据职位进行分组,求出每种职位的最低薪资
select job,min(sal) from emp group by job;
-- 求出最低薪资大于1500的职位
select job,min(sal) from emp where min(sal)>1500 group by job; -- 错误写法
select job,min(sal) from emp group by job having min(sal) > 1500; -- 正确
补充内容:where和having子句的区别:
(1)相同点: where和having都可以对记录进行筛选过滤。
(2)区别:where是在分组之前,对记录进行筛选过滤,并且where子句中不能使用多行函数以及列别名(但是可以使用表别名)
(3)区别:having是在分组之后,对记录进行筛选过滤,并且having子句中可以使用多行函数以及列别名、表别名。
-- 51.列出在每个部门就职的员工数量、平均工资。显示部门编号、员工数量,平均薪资。
-- 根据部门对员工进行分组, 统计每个组(部门)的人数和平均薪资
select dept_id, count(*), avg(sal) from emp group by dept_id;
-- 52.查出至少有一个员工的部门,显示部门编号、部门名称、部门位置、部门人数。
-- 连接查询部门表和员工表
select d.id,d.name,d.loc from emp e,dept d
where e.dept_id=d.id;
-- 按照部门进行分组,统计部门人数
select d.id,d.name,d.loc,count(*) from emp e,dept d
where e.dept_id=d.id
group by d.id
having count(*) >= 1;
-- 53.列出受雇日期早于直接上级的所有员工,显示员工编号、员工姓名、部门名称。
/* emp e1 员工表, emp e2 上级表, dept d 部门表
* 显示的列: e1.id, e1.name, d.name
* 查询的表: emp e1,emp e2,dept d
* 连接条件: e1.topid=e2.id e1.dept_id=d.id
* 筛选条件: e1.hdate<e2.hdate
*/
select e1.id, e1.name, d.name
from emp e1,emp e2,dept d
where e1.topid=e2.id and e1.dept_id=d.id
and e1.hdate<e2.hdate;
-- 补充:查询员工表中薪资最高的员工信息
select name, max(sal) from emp; -- 错误写法
select name,sal from emp order by sal desc limit 0,1; -- 正确写法
-- 求出emp表中的最高薪资
select max(sal) from emp;
-- 根据最高薪资到emp表中查询, 该薪资对应的员工信息
select * from emp where sal=(select max(sal) from emp);
数据库备份与恢复
备份数据库
在cmd窗口中(未登录的状态下),可以通过如下命令对指定的数据库进行备份:
mysqldump -u用户名 -p 数据库的名字 > 备份文件的位置
示例1: 对db40库中的数据(表,表记录)进行备份,备份到 d:/db40.sql文件中
mysqldump -uroot -p db40 > d:/db40.sql
键入密码,如果没有提示,即表示备份成功!
也可以一次性备份所有库,例如:
对mysql服务器中所有的数据库进行备份,备份到 d:/all.sql文件中
mysqldump -uroot -p --all-database > d:/all.sql
键入密码,如果没有提示错误(警告信息不是错误,可以忽略),即表示备份成功!
恢复数据库
1、恢复数据库方式一:
在cmd窗口中(未登录的状态下),可以通过如下命令对指定的数据库进行恢复:
mysql -u用户名 -p 数据库的名字 < 备份文件的位置
示例:将d:/db40.sql文件中的数据恢复到db60库中
-- 在cmd窗口中(已登录的状态下),先创建db60库:
create database db60 charset utf8;
-- 在cmd窗口中(未登录的状态下)
mysql -uroot -p db60 < d:/db40.sql
2、恢复数据库方式二:
在cmd窗口中(已登录的状态下),可以通过source执行指定位置的SQL文件:
source sql文件的位置
示例:将d:/db40.sql文件中的数据恢复到db80库中
-- 在cmd窗口中(已登录的状态下),先创建db80库,进入db80库:
create database db80 charset utf8;
use db80;
-- 再通过source执行指定位置下的sql文件:
source d:/db40.sql