摘要
在端到端深度学习系统中,图像区域的分组通常是通过像素级识别标签的自上而下的监督而隐式发生。在本文中,作者将分组机制带回深度网络中,这使得语义分割可以在只有文本信号监督的情况下完成。具体来说,作者提出了一种分组group的ViT模型,通过对比损失,在一个大规模的图像-文本数据集上与文本编码器共同训练GroupViT。在只有文本监督和没有任何像素级注释的情况下,GroupViT学会了将语义区域组合在一起,并成功地以zero-shot的方式转移到语义分割的任务上,不需要任何微调。
补充:传统的无监督分割中,分组的做法是首先选取若干个聚类中心,然后从这些聚类中心开始发散,将周围相似的像素扩充为一个group。
传统的全卷积网络语义分割方法的不足:1. 逐像素标注比较贵。2. 仅能识别有限的类别,无法做zs。
本文的贡献:提出一个纯文本监督的语义分割模型,无需做任何像素标注,就能够以零样本方式泛化到不同对象类别或词汇集。
方法
Grouping Vision Transformer
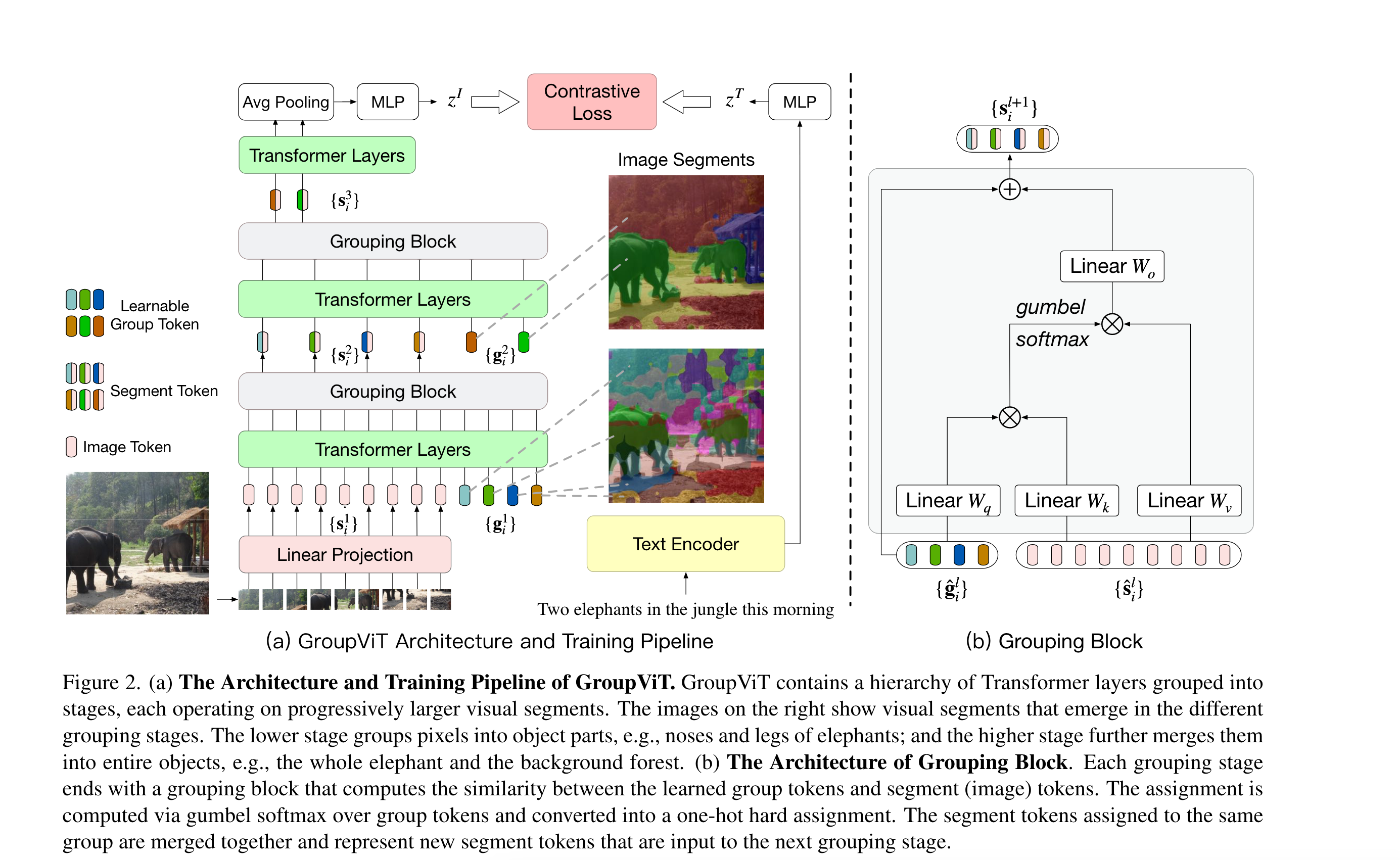
图2展示的是GroupViT encoder,利用Transformer架构对视觉概念进行分层渐进式分组。在GroupViT中,作者将Transformer层分成多个分组阶段,在每个阶段通过自注意来学习一些分组标记,这些标记从所有的图像标记(片段)中聚合信息,然后使用学到的分组标记,通过分组块将类似的图像标记合并在一起。
结构
如ViT,作者首先将图像(假设大小为\(224\times 224\))打成N个不重叠的patch,并进行线性变换得到token。在每个grouping stage,除了这些image token(总的大小为\(196\times 384\),因为使用的是ViT small,所以特征维度是384),作者还将若干个可学习的group token(这个token可以理解为cls token,cls token只有一个的原因是做分类图像只有一个特征,而做分割图像可以有多个特征。总的大小为\(64\times 384\),64是超参数,第一层设为64是为了有尽可能多的聚类中心,反正最后可以进行合并)直接concat起来作为输入,也就是\(\{g_i^1\}\)等。
Multi-stage Grouping
每次经过若干个Transformer layer(第一次有6个layer)后,可以认为group token已经学习得差不多了,因此会有一个Grouping Block,尝试将现有的组合并为更大的组,相当于做了聚类分配:

第一次合并完后,如图2(a)所示,得到的Segment token的维度就是\(64\times 384\)了。这里grouping还有一个好处,相当于缩短序列长度,减小计算复杂度以及训练时间,就像swin transformer一样,是一个层级式的网络结构。
在最后一个Grouping Stage后,作者对所有的segment tokens使用Transformer layer,并将输出进行聚合得到最终的全局图像表示\(z^I\):
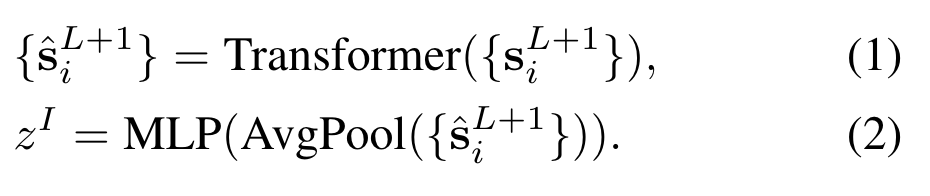
其中输出的大小为\(8\times 384\),这里的8也是超参数,这也意味着最多只能分割出8个类。经过AP后变为\(1\times 384\),再通过MLP得到\(z^I\)。
Grouping Block
Grouping Block就是利用计算自注意力的方式先算了一个相似度矩阵,维度为\(64\times 196\)(以第一个Grouping Block为例)。然后用相似度矩阵帮助image token做聚类中心的分配,计算得到的结果大小为\(64\times 384\),再加到group token上得到最后的结果。这里作者用了Gumbel softmax,是因为聚类中心的分配不可导,这里需要将这个操作变成可导的。具体细节还是要看论文。
Learning from Image-Text
在训练方面GroupViT和CLIP是非常相似的,都是通过图像-文本对计算对比学习的loss。但是对于CLIP,图像有一个特征,文本有一个特征,很容易计算对比学习的loss。但对于分割,文本端得到的还是一个文本特征,但是图像端得到的是序列长度为8的特征序列,那么怎么得到Image level的特征?作者这里直接用平均池化将\(8\times 384\)的特征序列变为\(1\times 384\)的特征序列。
Image-Text Contrastive Loss。
和CLIP一样,计算的都是对比学习的Loss。作者把GroupViT作为Image encoder,Transformer作为Text encoder。其中Text embedding是Text transformer最后一个输出的token。 训练时把图像和文本送入对应的encoder,然后投影到同样的embedding space计算相似度。这样为什么能work,个人感觉是用8个group token学到的信息汇总后能得到Image level的特征,这个Image level的特征与相应的文本是对应的,而文本中会包含图像中各个类别的信息(以名词体现)。如果单独拿出来一个group token,其与融合后的特征形式上是很相似的,所以可以直接用于推理。
Multi-Label Image-Text Contrastive Loss
为了使grouping更有效,除了上述对比学习loss,作者还提出了基于prompting的多标签对比学习loss。
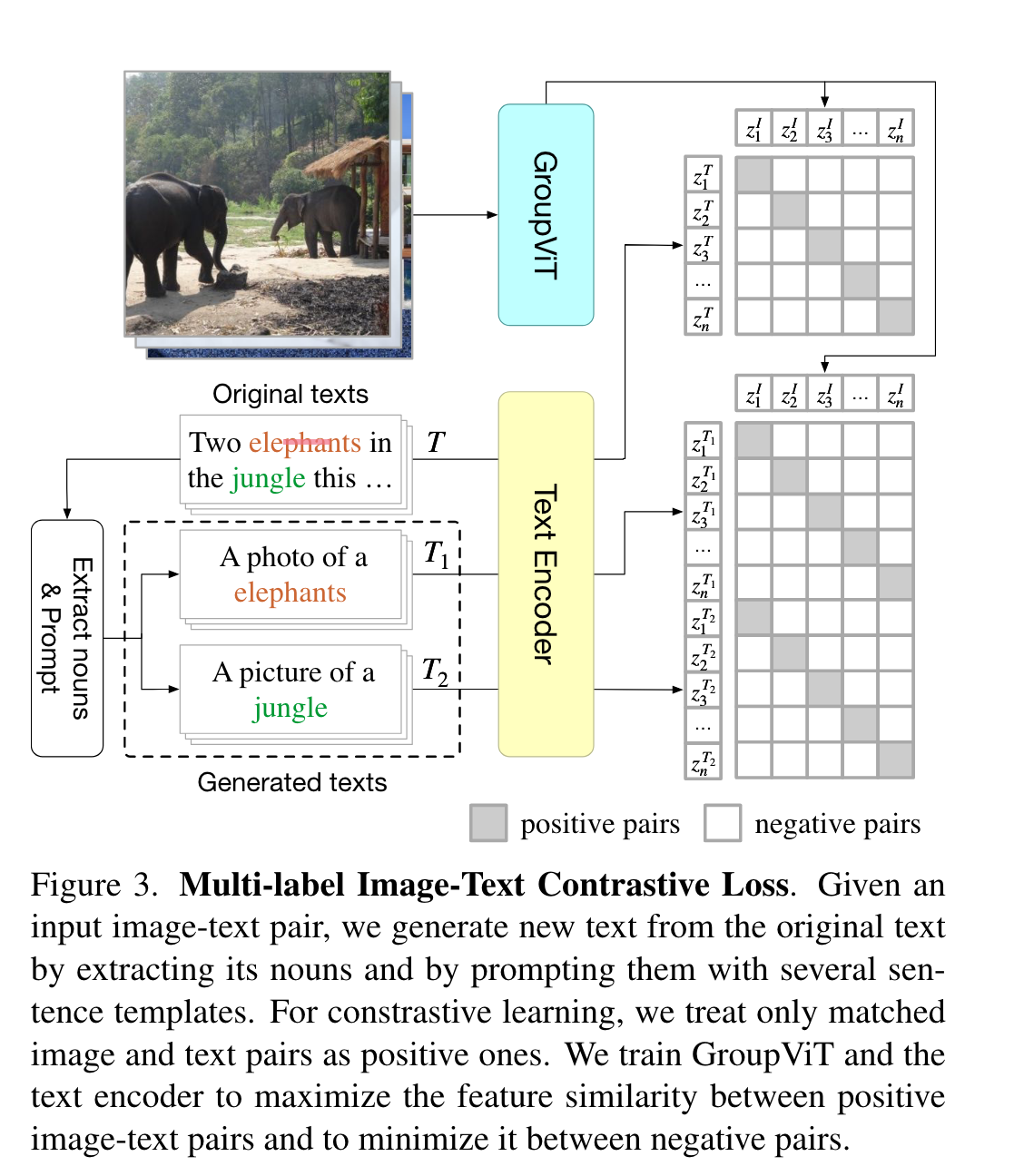
这里作者通过提取原始文本中的名词,使用提示模版生成新的文本,用这些文本再分别计算对比学习的loss。在每个batch中,每张图像有K个正样本和\(B(K-1)\)个负样本。这里个人感觉有点问题,为什么是\(B(K-1)\)而非\(K(B-1)\)?。
总的对比loss:
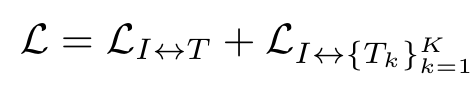
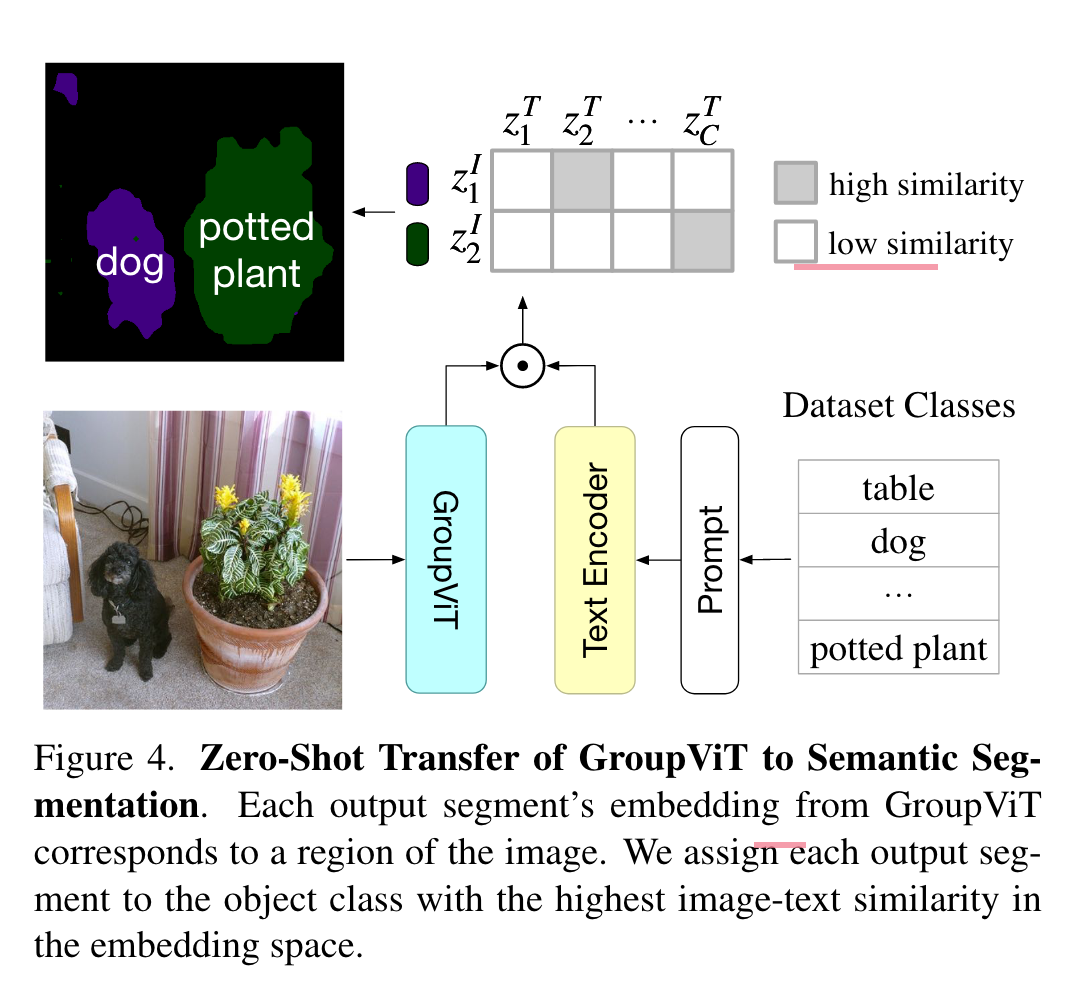
Zero-Shot Transfer to Semantic Segmentation
进行zero-shot推理时,首先将图像送入没有AvgPool的GroupViT,这样就得到了每一个segment的embedding。之后计算这些segment token的embedding与语义类别的text embedding。
实验
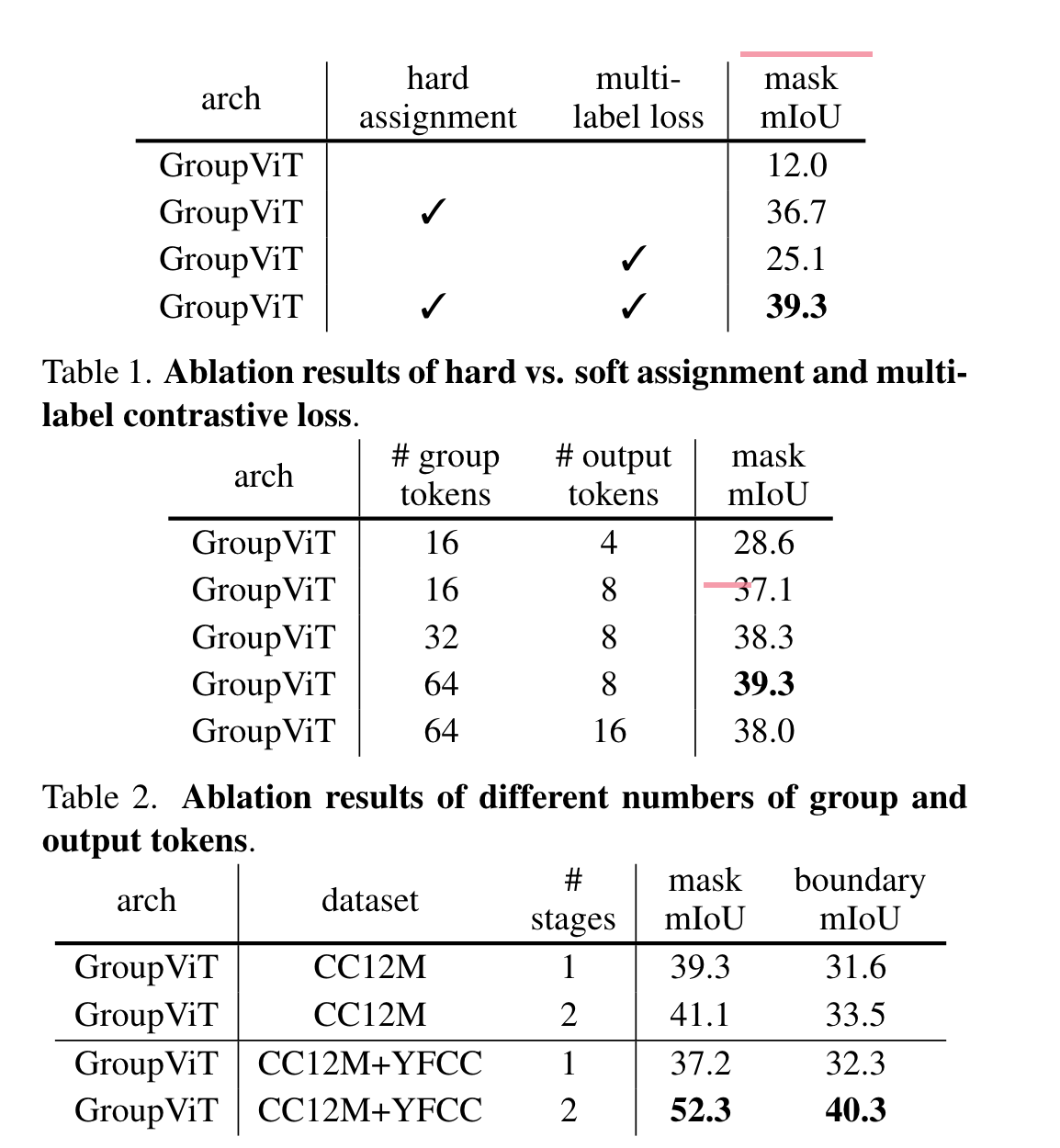
相比于soft assignment,hard assignment提升了20多个点,使用multi-label loss则起到了一个更好的辅助作用。同时作者还尝试了不同的group tokens以及output tokens的设置,发现64和8效果最好。

上面的结果显示两个stage相比于一个stage而言分割图更加准确且平滑。
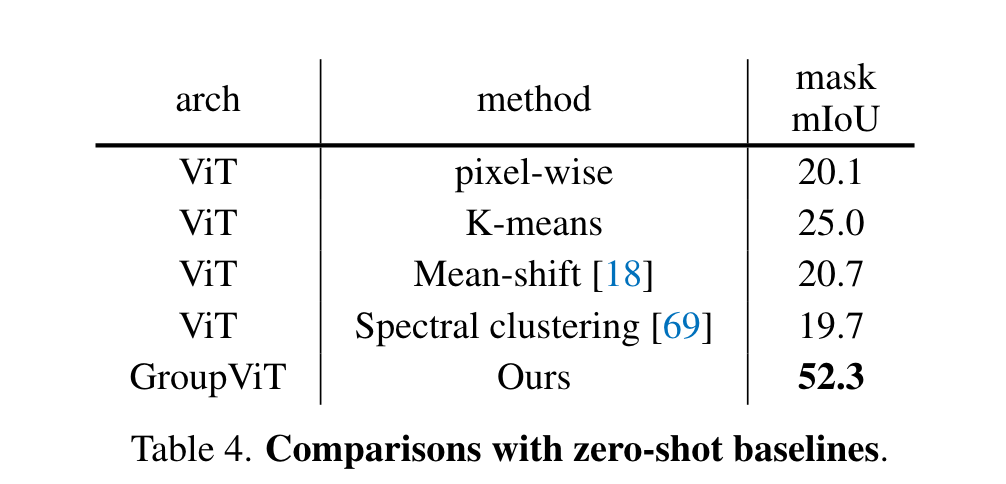

上面的结果比较有趣,作者可视化了在每个stage,group token都学到了什么。在第一个stage,group tokens主要关注mid-level的概念如眼睛等,而在第二个阶段则更关注high-level的概念。这里比较好奇这些标签是怎么得到的。
一些疑问:
推理的时候只能知道每个group token对应哪个类,但怎么做到逐像素分配类别?
见论文3.3节的后半部分。相当于连乘assignment matrix得到每个像素属于每个group token的概率。