摘要
作者首先回顾CLIP,说道使用图像-文本对进行大规模预训练得到的模型可以很容易迁移到下游任务。然后指出目前还没有人做过将从图像-文本对学到的知识应用于密集预测任务的工作。由此引出本文的核心,即作者提出了一个密集预测框架,将图像-文本匹配问题转化为像素-文本匹配问题,利用图像的上下文信息指导语言模型。
引言
本文作者研究的重点是如何对预训练好的模型进行微调以完成密集预测任务。一个明显的挑战就是上游任务的对比性预训练和下游任务逐像素预测之间巨大的差距。为此作者提出了语言引导的密集预测框架DenseCLIP。直接在下游数据集上微调模型不能充分挖掘CLIP模型的潜力。受CLIP中对比学习框架的启发,作者将CLIP中的原始图像-文本匹配问题转换为像素-文本匹配问题,并使用像素-文本分数图来明确指导密集预测模型的学习。通过进一步利用图像的上下文信息,用Transformer模块提示语言模型,这样能够促进模型通过优化text embedding更好地利用预训练的知识。本文的方法可以成为一个即插即用的模块,以改善CLIP预训练模型在现成的密集预测方法和任务上的微调。
方法
Overview of CLIP
在这一小节作者回顾了CLIP以此阐述本文的动机。CLIP包含两个encoder,一个encoder编码图像(如ResNet或者ViT),另一个encoder编码文本(Transformer),其目标是通过对比学习预训练将视觉和语言的embedding space进行对齐。为了将CLIP学到的知识迁移到下游分类任务中,作者说到一个简单却有效的方式是构建一系列的文本提示(prompts)。之后给定一张输入图像,就可以计算图像和各个文本之间的cosine similarity了。那么问题来了,能否将CLIP的能力迁移到复杂的视觉任务如Dense prediction?作者在下面给出了解决办法。
语言指导的Dense Prediction
作者提出了DenseCLIP框架,结构如图3所示。除了全局图像特征,作者发现同样可以从CLIP图像编码器的最后一层提取到语言兼容的特征图。例如有4个Stage的ResNet,取最后一个Stage的输出算一次全局平均池化,得到形状为\([C, 1]\)的全局特征。再将其与第四个阶段的输出在通道维度concat,之后对其计算多头自注意力:\([\overline{z}, z]=MHSA([\overline{x_4},x_4])\)。
传统的CLIP中,\(\overline{z}\)作为图像encoder的输出而\(z\)被忽略,但本文中作者提到了\(z\)的两个有趣的属性:首先\(z\)仍然包涵足够的空间信息,因此可以作为特征图;因为MHSA对于每个输入元素是对称的,因此\(z\)和\(\overline{z}\)可能会有一定的相似性,会和语言特征相匹配。因此作者考虑让\(z\)作为语言匹配的特征图。
为了得到文本特征,作者使用”a photo of a [CLS]”这样的模版为K个类别名构建了一系列的prompts(提示),使用CLIP的text encoder提取到的特征t形如\([K\times C]\)。当计算像素-文本分数图的时候则使用:\(s = \hat{z}\hat{t}^T\),其中\(s\in R^{H_4W_4\times K}\)。\(\hat{z}\)和\(\hat{t}\)是z和t沿通道维度l2归一化的结果。得到的分数图非常重要,可以看作是低分辨率的分割结果;将s直接concat到最后一个特征图可以显式合并语言先验。该框架是模型无关的,因为可以直接应用于分割或者检测任务。
上下文感知的提示
这一节作者主要探讨寻找一种方法改进文本特征t,而非简单使用人们预定义好的模版。
Language-domain prompting
CoOp这篇文章引入了可学习的文本上下文,通过反向传播对其进行优化,这样在下游任务中可以提高可迁移性。受此启发,作者在本文框架中使用可学习的文本上下文作为baseline。文本编码器的输入为\([p, e_k]\),其中\(p\in R^{N\times C}\)为可学习的文本上下文而\(e_k\in R^C\)是第k个类名称的embedding。
Vision-to-language prompting
包括视觉上下文的描述可以使文本内容更加准确。因此,作者研究了如何使用视觉上下文来优化文本特征。通常可以使用Transformer decoder中的交叉注意力机制建模视觉与语言之间的相互作用。
作者提出了两种不同的内容感知的提示,如图4所示。
第一个策略是pre-language-model prompting。作者将\([\overline{z}, z]\)传入Transformer decoder来编码视觉上下文:
\(v_{pre}=TransDecoder(q, [\overline{z}, z])\)
其中\(q\in R^{N\times C}\)是一系列可学习的queries,\(v_{pre}\in R^{N\times C}\)是提取到的视觉上下文。最后将前面提到的\([p, e_k]\)中的p替换为v。
另一个策略是post-model prompting,即在文本编码器后优化文本特征。此处作者使用CoOp生成文本特征并直接使用它们作为Transformer decoder的queries:
\(v_{post}=TransDecoder(t,[\overline{z}, z])\)
这种实现方式鼓励文本特征查找最相关的视觉线索,随后通过残差连接更新文本特征:
\(t\leftarrow t+\gamma v_{post}\)
其中\(\gamma \in R^C\)是可学习的参数,用于控制残差的尺度,其值使用非常小的数进行初始化以保留文本特征中的语言先验。
对于上述两种方式,作者认为post-model prompting更好:(1)这种方式更加高效。因为文本编码器的输入依赖于图像,因此在推理过程中,pre-model prompting需要额外的前向传播,而post-model prompting可以在训练后存储提取到的文本特征,从而减少文本编码器在推理过程中的开销。(2)实验结果表明Post-model prompting的性能更好。
Instantiations
Semantic segmentation
本文的框架是模型不可知的,因此可以用于任何密集预测pipeline。同时,作者提出使用辅助目标在分割中更好地利用文本分数图。因为分数图可以看作较小的分割结果,因此作者构建了如下分割损失:
\(L_{aux}^{seg}=CE(Softmax(s/\tau),y)\)
其中\(\tau=0.07\)是温度系数,\(y\in \{1,…K\}^{H_4W_4}\)是gt图。辅助分割损失有利于恢复特征图的局部性。
Object detection & instance segmentation
对于这两种任务没有gt标签,为了构造类似分割中的损失,作者使用bounding box和label构造了一个二值target:
\(\widetilde{y}\in {0, 1}^{H_4W_4\times K}\)。将前面的CE改成BCE即可。
Applications to any backbone models
作者说可以用任何骨干网络替代CLIP的图像编码器。虽然视觉骨干的输出和文本编码器之间可能没有很强的关系,但其可以在语言指导下学习得更好更快。
实验
语义分割
实验中作者使用了CLIP预训练好的image encoder作为分割的骨架。对于text encoder在训练时是冻结的以保留从大规模预训练中学到的自然语言知识。
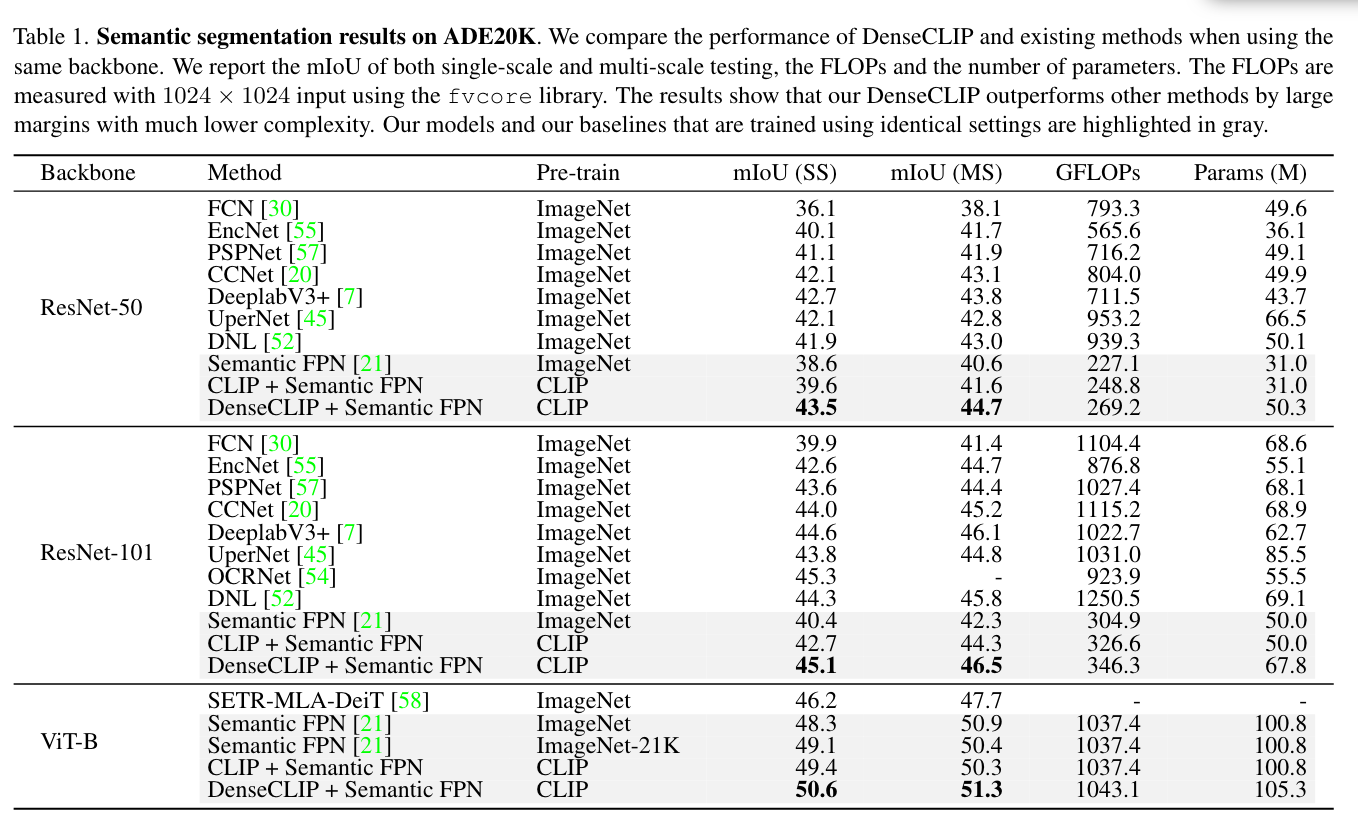
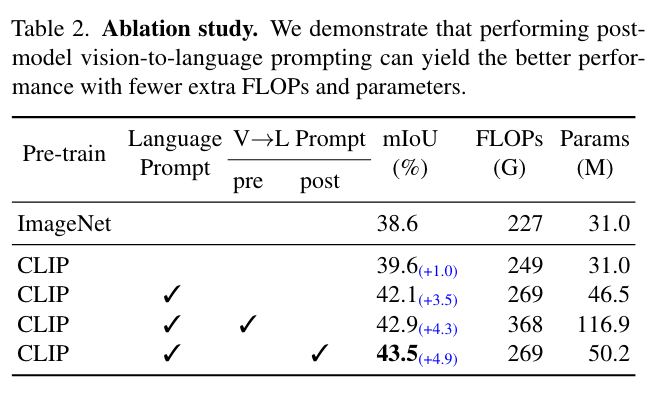
作者提到直接使用默认的训练策略在CLIP上进行微调效果不好,因此进行了两处关键的修改:
1.使用AdamW代替SGD
2.为了更好地保留预训练的权重,将image encoder的学习率设置为其它参数学习率的\(\frac{1}{10}\)。
物体检测
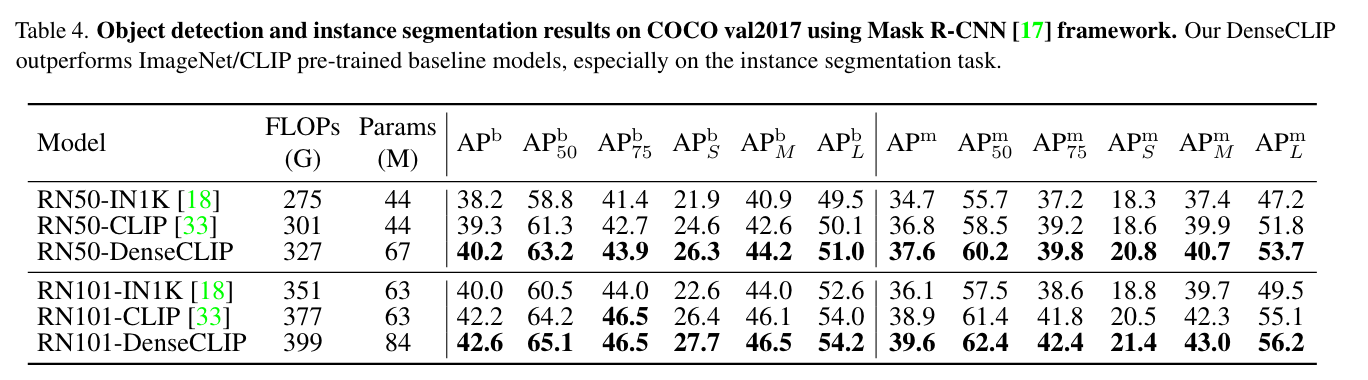
一些实现细节
loss
CLIP的loss(参考https://blog.csdn.net/caroline_wendy/article/details/125088243):
import numpy as np
import torch
import torch.nn.functional as F
batchsize = 4
a = torch.randn(batchsize, 3)
b = torch.randn(batchsize, 3)
score1 = a @ b.t()
score2 = score1.t()
labels = torch.arange(batchsize)
print(labels)
total_loss = (
F.cross_entropy(score1, labels) + #第一个参数的shape:[batchsize, C] 第二个:[batchsize]
F.cross_entropy(score2, labels)
) / 2
与CLIP的loss不同,论文中将loss分为Task Loss以及Pixel-Text Matching Loss,通过Image Decoder得到的结果算出来的是Task Loss,代码中是loss_decode = self._decode_head_forward_train(x, img_metas, gt_semantic_seg),这里的Decoder用的是FPN Head;Pixel-Text Matching Loss应该是:
if self.with_identity_head:
loss_identity = self._identity_head_forward_train(
score_map/self.tau, img_metas, gt_semantic_seg)
losses.update(loss_identity)
if self.with_auxiliary_head:
loss_aux = self._auxiliary_head_forward_train(
_x_orig, img_metas, gt_semantic_seg)
losses.update(loss_aux)
但很奇怪的是没有找到论文3.4节的语义分割loss在哪里(貌似和with_identity_head有点像,但gt_semantic_seg是原始尺寸的)。
代码
AttentionPool2D:
class AttentionPool2d(nn.Module):
def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):
super().__init__()
self.positional_embedding = nn.Parameter(torch.randn(spacial_dim ** 2 + 1, embed_dim) / embed_dim ** 0.5)
self.k_proj = nn.Linear(embed_dim, embed_dim)
self.q_proj = nn.Linear(embed_dim, embed_dim)
self.v_proj = nn.Linear(embed_dim, embed_dim)
self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim)
self.num_heads = num_heads
self.embed_dim = embed_dim
self.spacial_dim = spacial_dim
def forward(self, x):
B, C, H, W = x.shape
x = x.reshape(x.shape[0], x.shape[1], x.shape[2] * x.shape[3]).permute(2, 0, 1) # NCHW -> (HW)NC
x = torch.cat([x.mean(dim=0, keepdim=True), x], dim=0) # (HW+1)NC
cls_pos = self.positional_embedding[0:1, :]
spatial_pos = F.interpolate(self.positional_embedding[1:,].reshape(1, self.spacial_dim, self.spacial_dim, self.embed_dim).permute(0, 3, 1, 2), size=(H, W), mode='bilinear')
spatial_pos = spatial_pos.reshape(self.embed_dim, H*W).permute(1, 0)
positional_embedding = torch.cat([cls_pos, spatial_pos], dim=0)
x = x + positional_embedding[:, None, :]
x, _ = F.multi_head_attention_forward(
query=x, key=x, value=x,
embed_dim_to_check=x.shape[-1],
num_heads=self.num_heads,
q_proj_weight=self.q_proj.weight,
k_proj_weight=self.k_proj.weight,
v_proj_weight=self.v_proj.weight,
in_proj_weight=None,
in_proj_bias=torch.cat([self.q_proj.bias, self.k_proj.bias, self.v_proj.bias]),
bias_k=None,
bias_v=None,
add_zero_attn=False,
dropout_p=0,
out_proj_weight=self.c_proj.weight,
out_proj_bias=self.c_proj.bias,
use_separate_proj_weight=True,
training=self.training,
need_weights=False
)
x = x.permute(1, 2, 0)
global_feat = x[:, :, 0]
feature_map = x[:, :, 1:].reshape(B, -1, H, W)
return global_feat, feature_map
在CLIPResNetWithAttention网络forward时使用。
denseclip.py中,关注forward_train函数:
def forward_train(self, img, img_metas, gt_semantic_seg):
"""Forward function for training.
Args:
img (Tensor): Input images.
img_metas (list[dict]): List of image info dict where each dict
has: 'img_shape', 'scale_factor', 'flip', and may also contain
'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
For details on the values of these keys see
`mmseg/datasets/pipelines/formatting.py:Collect`.
gt_semantic_seg (Tensor): Semantic segmentation masks
used if the architecture supports semantic segmentation task.
Returns:
dict[str, Tensor]: a dictionary of loss components
"""
x = self.extract_feat(img)#通过CLIPResNetWithAttention网络进行特征提取
_x_orig = [x[i] for i in range(4)]#resnet的4个stage的feature map
text_embeddings, x_orig, score_map = self.after_extract_feat(x)#得到pixel-text的分数图
if self.with_neck:
x_orig = list(self.neck(x_orig))
_x_orig = x_orig
losses = dict()
#这里的x_orig经过after_extract_feat函数已经加上了score_map的信息了
if self.text_head:
x = [text_embeddings,] + x_orig
else:
x = x_orig
# decode_head=dict(type='FPNHead',num_classes=150,loss_decode=dict(type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
loss_decode = self._decode_head_forward_train(x, img_metas,
gt_semantic_seg)
losses.update(loss_decode)
if self.with_identity_head:
loss_identity = self._identity_head_forward_train(
score_map/self.tau, img_metas, gt_semantic_seg)
losses.update(loss_identity)
if self.with_auxiliary_head:
loss_aux = self._auxiliary_head_forward_train(
_x_orig, img_metas, gt_semantic_seg)
losses.update(loss_aux)
return losses
def after_extract_feat(self, x):
x_orig = list(x[0:4])
global_feat, visual_embeddings = x[4]
B, C, H, W = visual_embeddings.shape#H4W4 x C
if self.context_feature == 'attention':
visual_context = torch.cat([global_feat.reshape(B, C, 1), visual_embeddings.reshape(B, C, H*W)], dim=2).permute(0, 2, 1) # B, N, C
#visual_context就是论文中说的$[\overline{z}, z]$
# (B, K, C)
# 根据3.3节的Language-domain prompting,送入text_encoder的是[p, ek](基线方法)
# p是self.texts = torch.cat([tokenize(c, context_length=self.context_length) for c in class_names]),即learnable textual contexts,ek是nn.Parameter(torch.randn(1, context_length, token_embed_dim)),即embedding for the name of the k-th class
# 如果是premodel prompting的话,需要把p换成TransDecoder(q, [ ̄ z, z]),但代码没有使用
text_embeddings = self.text_encoder(self.texts.to(global_feat.device), self.contexts).expand(B, -1, -1)#
# update text_embeddings by visual_context!
# (B, 1, C)
# text_diff 就是vpost,vpost = TransDecoder(t, [ ̄ z, z])
text_diff = self.context_decoder(text_embeddings, visual_context)
# (B, K, C)
#代码实现用的是post-model prompting,text_diff 就是vpost 这两行代码构建的是prompt
text_embeddings = text_embeddings + self.gamma * text_diff
# compute score map and concat
B, K, C = text_embeddings.shape
visual_embeddings = F.normalize(visual_embeddings, dim=1, p=2)#L2 norm
text = F.normalize(text_embeddings, dim=2, p=2)#L2 norm
score_map = torch.einsum('bchw,bkc->bkhw', visual_embeddings, text)
# 论文中说的x4'=[x4, s] 形状为[H4W4 x (C + K)]
# concatenate the score maps to the last feature map to explicitly incorporate language priors
# self.score_concat_index = 3
x_orig[self.score_concat_index] = torch.cat([x_orig[self.score_concat_index], score_map], dim=1)
return text_embeddings, x_orig, score_map
推理部分:
def encode_decode(self, img, img_metas):
"""Encode images with backbone and decode into a semantic segmentation
map of the same size as input."""
x = self.extract_feat(img)
_x_orig = [x[i] for i in range(4)]
text_embeddings, x_orig, score_map = self.after_extract_feat(x)
if self.with_neck:
x_orig = list(self.neck(x_orig))
if self.text_head:
x = [text_embeddings,] + x_orig
else:
x = x_orig
# print('text_embedding=', text_embeddings[0])
out = self._decode_head_forward_test(x, img_metas)
# print('cls_map=', out[0,:,40, 40])
out = resize(
input=out,
size=img.shape[2:],
mode='bilinear',
align_corners=self.align_corners)
return out
def slide_inference(self, img, img_meta, rescale):
"""Inference by sliding-window with overlap.
If h_crop > h_img or w_crop > w_img, the small patch will be used to
decode without padding.
"""
h_stride, w_stride = self.test_cfg.stride
h_crop, w_crop = self.test_cfg.crop_size
batch_size, _, h_img, w_img = img.size()
num_classes = self.num_classes
h_grids = max(h_img - h_crop + h_stride - 1, 0) // h_stride + 1
w_grids = max(w_img - w_crop + w_stride - 1, 0) // w_stride + 1
preds = img.new_zeros((batch_size, num_classes, h_img, w_img))
count_mat = img.new_zeros((batch_size, 1, h_img, w_img))
for h_idx in range(h_grids):
for w_idx in range(w_grids):
y1 = h_idx * h_stride
x1 = w_idx * w_stride
y2 = min(y1 + h_crop, h_img)
x2 = min(x1 + w_crop, w_img)
y1 = max(y2 - h_crop, 0)
x1 = max(x2 - w_crop, 0)
crop_img = img[:, :, y1:y2, x1:x2]
crop_seg_logit = self.encode_decode(crop_img, img_meta)
preds += F.pad(crop_seg_logit,
(int(x1), int(preds.shape[3] - x2), int(y1),
int(preds.shape[2] - y2)))
count_mat[:, :, y1:y2, x1:x2] += 1
assert (count_mat == 0).sum() == 0
if torch.onnx.is_in_onnx_export():
# cast count_mat to constant while exporting to ONNX
count_mat = torch.from_numpy(
count_mat.cpu().detach().numpy()).to(device=img.device)
preds = preds / count_mat
if rescale:
preds = resize(
preds,
size=img_meta[0]['ori_shape'][:2],
mode='bilinear',
align_corners=self.align_corners,
warning=False)
return preds
def whole_inference(self, img, img_meta, rescale):
"""Inference with full image."""
seg_logit = self.encode_decode(img, img_meta)
if rescale:
# support dynamic shape for onnx
if torch.onnx.is_in_onnx_export():
size = img.shape[2:]
else:
size = img_meta[0]['ori_shape'][:2]
seg_logit = resize(
seg_logit,
size=size,
mode='bilinear',
align_corners=self.align_corners,
warning=False)
if torch.isnan(seg_logit).any():
print('########### find NAN #############')
return seg_logit
def inference(self, img, img_meta, rescale):
"""Inference with slide/whole style.
Args:
img (Tensor): The input image of shape (N, 3, H, W).
img_meta (dict): Image info dict where each dict has: 'img_shape',
'scale_factor', 'flip', and may also contain
'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
For details on the values of these keys see
`mmseg/datasets/pipelines/formatting.py:Collect`.
rescale (bool): Whether rescale back to original shape.
Returns:
Tensor: The output segmentation map.
"""
assert self.test_cfg.mode in ['slide', 'whole']
ori_shape = img_meta[0]['ori_shape']
assert all(_['ori_shape'] == ori_shape for _ in img_meta)
if self.test_cfg.mode == 'slide':
seg_logit = self.slide_inference(img, img_meta, rescale)
else:
seg_logit = self.whole_inference(img, img_meta, rescale)
output = F.softmax(seg_logit, dim=1)
flip = img_meta[0]['flip']
if flip:
flip_direction = img_meta[0]['flip_direction']
assert flip_direction in ['horizontal', 'vertical']
if flip_direction == 'horizontal':
output = output.flip(dims=(3, ))
elif flip_direction == 'vertical':
output = output.flip(dims=(2, ))
return output