最近看了下多进程。
一种接近底层的实现方法是使用 os.fork()方法,fork出子进程。但是这样做事有局限性的。比如windows的os模块里面没有 fork() 方法。
windows: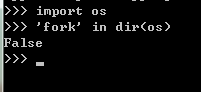 。linux:
。linux: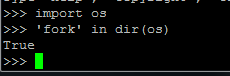
另外还有一个模块:subprocess。这个没整过,但从vamei的博客里看到说也同样有局限性。
所以直接说主角吧 --- multiprocessing模块。 multiprocessing模块会在windows上时模拟出fork的效果,可以实现跨平台,所以大多数都使用multiprocessing。
下面给一段简单的代码,演示一下创建进程:
#encoding:utf-8 from multiprocessing import Process import os, time, random #线程启动后实际执行的代码块 def r1(process_name): for i in range(5): print process_name, os.getpid() #打印出当前进程的id time.sleep(random.random())
def r2(process_name): for i in range(5): print process_name, os.getpid() #打印出当前进程的id time.sleep(random.random()) if __name__ == "__main__": print "main process run..." p1 = Process(target=r1, args=('process_name1', )) #target:指定进程执行的函数,args:该函数的参数,需要使用tuple p2 = Process(target=r2, args=('process_name2', )) p1.start() #通过调用start方法启动进程,跟线程差不多。 p2.start() #但run方法在哪呢?待会说。。。 p1.join() #join方法也很有意思,寻思了一下午,终于理解了。待会演示。 p2.join() print "main process runned all lines..."
执行结果:
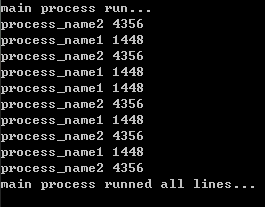
上面提到了两个方法:run 和join
run:如果在创建Process对象的时候不指定target,那么就会默认执行Process的run方法:
#encoding:utf-8 from multiprocessing import Process import os, time, random def r(): print 'run method' if __name__ == "__main__": print "main process run..." #没有指定Process的targt p1 = Process() p2 = Process() #如果在创建Process时不指定target,那么执行时没有任何效果。因为默认的run方法是判断如果不指定target,那就什么都不做 #所以这里手动改变了run方法 p1.run = r p2.run = r p1.start() p2.start() p1.join() p2.join() print "main process runned all lines..."
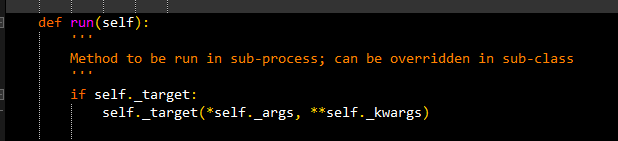
另:python源码里,Process.run方法:
执行结果:
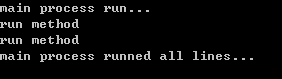
可见如果在实例化Process时不指定target,就会执行默认的run方法。
还有一个join方法:
最上面演示的代码中,在调用Process的start方法后,调用了两次join方法。这个join方法是干什么的呢?
官方文档的意思是:阻塞当前进程,直到调用join方法的那个进程执行完,再继续执行当前进程。
比如还是刚才的代码,只是把两个join注释掉了:
#encoding:utf-8 from multiprocessing import Process import os, time, random def r1(process_name): for i in range(5): print process_name, os.getpid() #打印出当前进程的id time.sleep(random.random()) def r2(process_name): for i in range(5): print process_name, os.getpid() #打印出当前进程的id time.sleep(random.random()) if __name__ == "__main__": print "main process run..." p1 = Process(target=r1, args=('process_name1', )) p2 = Process(target=r2, args=('process_name2', )) p1.start() p2.start() #p1.join()
#p2.join() print "main process runned all lines..."
执行结果:
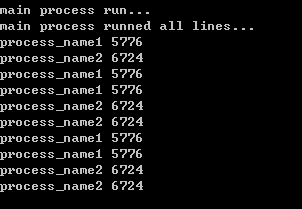
发现主进程不像之前那样,等待两个子进程执行完了,才继续执行。而是启动两个进程后立即向下执行。
为了深刻理解,这次把p2的执行函数里面睡眠时间调大,让他多睡一会,然后保留p1的join,注释掉p2的join,效果更明显:
#encoding:utf-8 from multiprocessing import Process import os, time, random def r1(process_name): for i in range(5): print process_name, os.getpid() #打印出当前进程的id time.sleep(random.random()) def r2(process_name): for i in range(5): print process_name, os.getpid() #打印出当前进程的id time.sleep(random.random()*2) if __name__ == "__main__": print "main process run..." p1 = Process(target=r1, args=('process_name1', )) p2 = Process(target=r2, args=('process_name2', )) p1.start() p2.start() p1.join() #p2.join() print "main process runned all lines..."
执行结果:
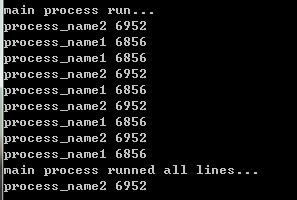
发现主线程只是等待p1完成了,就会向下执行,而不会等待p2是否完成。
所以使用多进程的常规方法是,先依次调用start启动进程,再依次调用join要求主进程等待子进程的结束。
然而为什么要先依次调用start再调用join,而不是start完了就调用join呢,如下:
由:
p1.start()
p2.start()
p1.join()
改为:
p1.start()
p1.join()
p2.start()
执行效果:
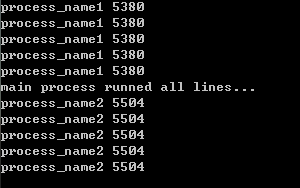
发现是先执行完p1,再执行主线程,最后才开始p2。
今天上午一直困惑这个事,现在终于明白了。join是用来阻塞当前线程的,p1.start()之后,p1就提示主线程,需要等待p1结束才向下执行,那主线程就乖乖的等着啦,自然没有执行p2.start()这一句啦,当然就变成了图示的效果了。