刚好这两天看了陈硕muduo和libevent2的对比代码,作些笔记。
https://blog.csdn.net/Solstice/article/details/5864889
https://github.com/chenshuo/recipes/tree/master/pingpong/libevent
先看下单线程测试脚本:
1 #!/bin/sh 2 3 killall server 4 timeout=${timeout:-100} 5 bufsize=${bufsize:-16384} 6 nothreads=1 7 8 for nosessions in 1 10 100 1000 10000; do 9 sleep 5 10 echo "Bufsize: $bufsize Threads: $nothreads Sessions: $nosessions" 11 taskset -c 1 ./server 2> /dev/null & srvpid=$! 12 sleep 1 13 taskset -c 2 ./client 9876 $bufsize $nosessions $timeout 14 kill -9 $srvpid 15 done
taskset可以绑定cpu,这里详见之前提到的cpu亲和性绑定。
$!获取Shell最后运行的后台Process的PID。
再看下server实现。
1 int one = 1; 2 setsockopt(fd, IPPROTO_TCP, TCP_NODELAY, &one, sizeof one);
TCP_NODELAYIf set, disable the Nagle algorithm. This means that segments are always sent as soon as possible, even if there is only a small amount of data. When not set, data is buffered until there is a sufficient amount to send out, thereby avoiding the frequent sending of small packets, which results in poor utilization of the network. This option is overridden by TCP_CORK; however, setting this option forces an explicit flush of pending output, even if TCP_CORK is currently set.
TCP/IP协议中针对TCP默认开启了Nagle算法。Nagle算法通过减少需要传输的数据包,来优化网络。在内核实现中,数据包的发送和接受会先做缓存,分别对应于写缓存和读缓存。
启动TCP_NODELAY,就意味着禁用了Nagle算法,允许小包的发送。对于延时敏感型,同时数据传输量比较小的应用,开启TCP_NODELAY选项无疑是一个正确的选择。比如,对于SSH会话,用户在远程敲击键盘发出指令的速度相对于网络带宽能力来说,绝对不是在一个量级上的,所以数据传输非常少;而又要求用户的输入能够及时获得返回,有较低的延时。如果开启了Nagle算法,就很可能出现频繁的延时,导致用户体验极差。当然,你也可以选择在应用层进行buffer,比如使用java中的buffered stream,尽可能地将大包写入到内核的写缓存进行发送;vectored I/O(writev接口)也是个不错的选择。
对于关闭TCP_NODELAY,则是应用了Nagle算法。数据只有在写缓存中累积到一定量之后,才会被发送出去,这样明显提高了网络利用率(实际传输数据payload与协议头的比例大大提高)。但是这由不可避免地增加了延时;与TCP delayed ack这个特性结合,这个问题会更加显著,延时基本在40ms左右。当然这个问题只有在连续进行两次写操作的时候,才会暴露出来。
(整理自知乎:https://www.zhihu.com/question/42308970/answer/123620051)
不过这里提到的benchmark有点看不懂。为啥千兆网络,吞吐量能好几百MB?
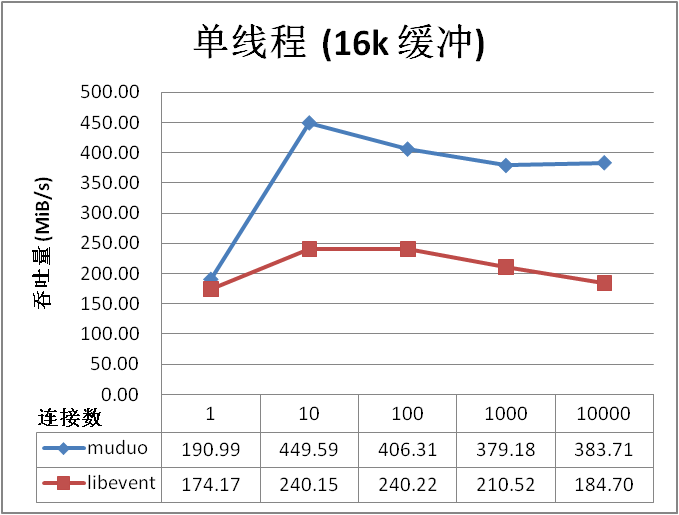
https://github.com/Qihoo360/evpp/blob/master/docs/benchmark_throughput_vs_asio.md
吞吐量统计的是client接收总字节数。
1 static void readcb(struct bufferevent *bev, void *ctx) 2 { 3 /* This callback is invoked when there is data to read on bev. */ 4 struct evbuffer *input = bufferevent_get_input(bev); 5 struct evbuffer *output = bufferevent_get_output(bev); 6 7 ++total_messages_read; 8 total_bytes_read += evbuffer_get_length(input); 9 10 /* Copy all the data from the input buffer to the output buffer. */ 11 evbuffer_add_buffer(output, input); 12 }
因为这里测试是本地测试,走的是本地回环,如果是unix domain socket,也一样不需要走物理设备,所以不受物理网卡的限制。