awk工作原理
awk -F":" '{print $1,$3}' access.log
(1)awk使用一行作为输入,并将这一行赋给变量$0,每一行可称作为一个记录,以换行符结束
(2)然后,行被空格分解成字段,每个字段存储在已编号的变量中,从$1开始
(3)awk如何知道空格来分隔字段的呢?因为有一个内部变量FS来确定字段分隔符,初始时,FS赋为空格或者是tab
(4)awk打印字段时,将以设置的方法,使用print函数打印,awk在打印的字段间加上空格,因为$1,$2间有一个,逗号。逗号比较特殊,映射为另一个变量,成为输出字段分隔符OFS,OFS默认为空格
(5)awk打印字段时,将从文件中获取另一行,并将其存储在$0中,覆盖原来的内容,然后将新的字符串分隔成字段并进行处理。该过程持续到处理文件结束。记录与字段相关内部变量:
1.记录和字段 awk 按记录处理:一行是一条记录,因为awk默认以换行符分开的字符串是一条记录。(默认\n换行符:记录分隔符) 字段:以字段分割符分割的字符串 默认是单个或多个“ ” tab键。 2.awk中的变量 $0:表示整行; NF : 统计字段的个数 $NF:是number finally,表示最后一列的信息 RS:输入记录分隔符; ORS:输出记录分隔符。 NR:打印记录号,(行号) FNR:可以分开,按不同的文件打印行号。 FS : 输入字段分隔符,默认为一个空格。 OFS 输出的字段分隔符,默认为一个空格。 FILENAME 文件名 被处理的文件名称 $1 第一个字段,$2第二个字段,依次类推...
FS(输入字段分隔符)---一般简写为-F(属于行处理前)cat access.log | awk 'BEGIN{FS=":"} {print $1,$2}'
cat /etc/passwd | awk -F":" '{print $1,$2}'#注:如果-F不加默认为空格区分!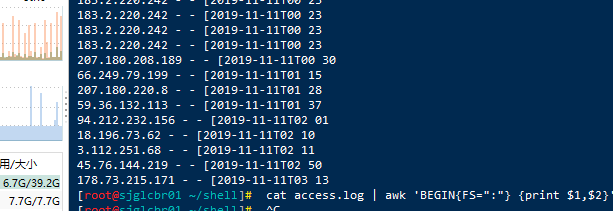
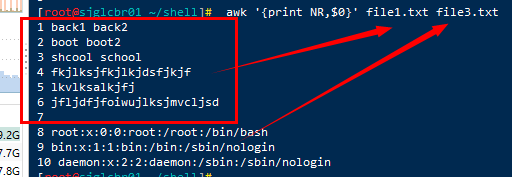
NR 表示记录编号, 在awk将行做为记录, 该变量相当于当前行号,也就是记录号
awk '{print NR,$0}' file1.txt file3.txt
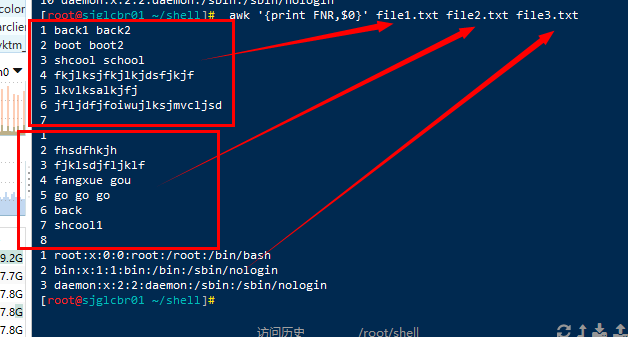
FNR:表示记录编号, 在awk将行做为记录, 该变量相当于当前行号,也就是记录号(#会将不同文件分开)
awk '{print FNR,$0}' file1.txt file2.txt file3.txt
NF:统计列的个数cat /etc/passwd | awk -F":" '{print NF}
打印最后一列 cat file3.txt | awk -F":" '{print $NF}'

在awk中使用for循环
awk '{for(i=1;i<=2;i++) {print $0}}' file3.txt

#把要统计的对象作为索引,最后对他们的值进行累加,累加出来的这个值就是你的统计数量
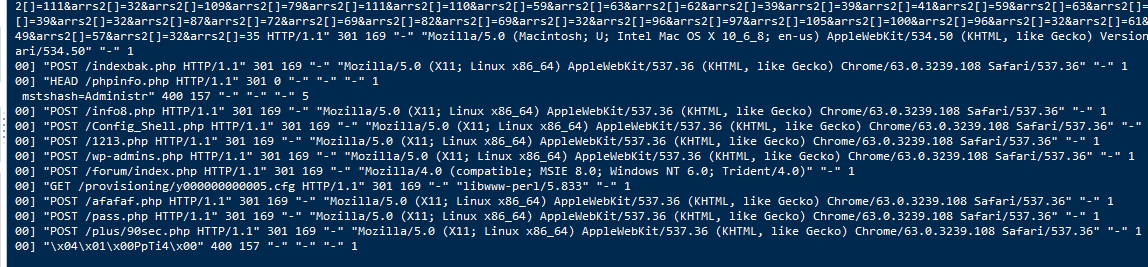
1. 统计access.log中各种类型shell的数量
cat access.log | awk -F: '{shells[$NF]++} END{ for(i in shells){print i,shells[i]} }'
2.统计nginx日志出现的状态码
cat access.log | awk '{stat[$9]++} END{for(i in stat){print i,stat[i]}}'

3.统计当前nginx日志中每个ip访问的数量
cat access.log | awk '{ips[$1]++} END{for(i in ips){print i,ips[i]}}'

4.统计某一天的nginx日志中的不同ip的访问量cat access.log |grep '28/Sep/2019' | awk '{ips[$1]++} END{for(i in ips){print i,ips[i]}}'
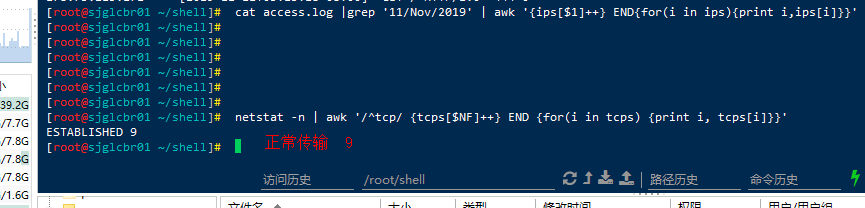
统计tcp连接的状态---下去自己查各个状态,包括什么原因造成的!netstat -n | awk '/^tcp/ {tcps[$NF]++} END {for(i in tcps) {print i, tcps[i]}}'LAST_ACK 5 (正在等待处理的请求数) SYN_RECV 30 ESTABLISHED 1597 (正常数据传输状态) FIN_WAIT1 51 FIN_WAIT2 504 TIME_WAIT 1057 (处理完毕,等待超时结束的请求数)
经典案例
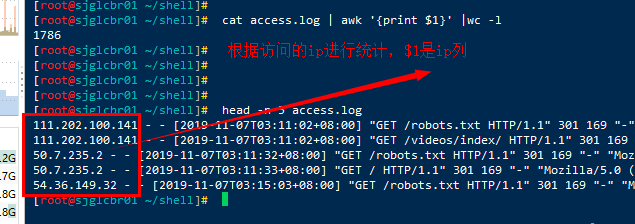
UV与PV统计 PV:即访问量,也就是访问您商铺的次数; 例如:今天显示有300 PV,则证明今天你的商铺被访问了300次。 ================================================================ UV:即访问人数,也就是有多少人来过您的商铺; #需要去重 例如:今天显示有50 UV,则证明今天有50个人来过你的商铺。 ================================================================= 1.根据访问IP统计UV
cat access.log | awk '{print $1}' |sort |uniq -c | wc -l
uniq:去重
-c:统计每行连续出现的次数
2.根据访问ip统计PV
# cat access.log | awk '{print $1}' |wc -l
cat access.log | awk '{print $7}' |wc -l 根据url进行查询统计
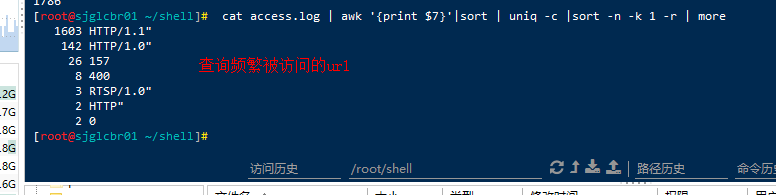
3.查询访问最频繁的URL
# cat access.log | awk '{print $7}'|sort | uniq -c |sort -n -k 1 -r | more
4.查询访问最频繁的IP
# cat access.log | awk '{print $1}'|sort | uniq -c |sort -n -k 1 -r | more
sort:排序,默认升序
-k:指定列数
-r:降序
-n:以数值来排序