聚类
聚类定义
- 对大量未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大,而类别间的数据相似度较小--无监督
相似度计算方法

- Jaccard相似度的由来

- 余弦相似度与Pearson相似系数

基本思想
- 给定一个有N个对象的数据集,构造数据的k个簇,k<n 。满足以下条件:
- 每个簇至少包含一个对象
- 每个对象属于且属于一个簇
- 满足条件的簇成为合理划分
- 对于给定的类别数目k,首先给出初始划分,通过迭代改变样本和簇的隶属关系,使得每一次改进之后的划分方案都比前一次好
k-means算法

- k-means过程
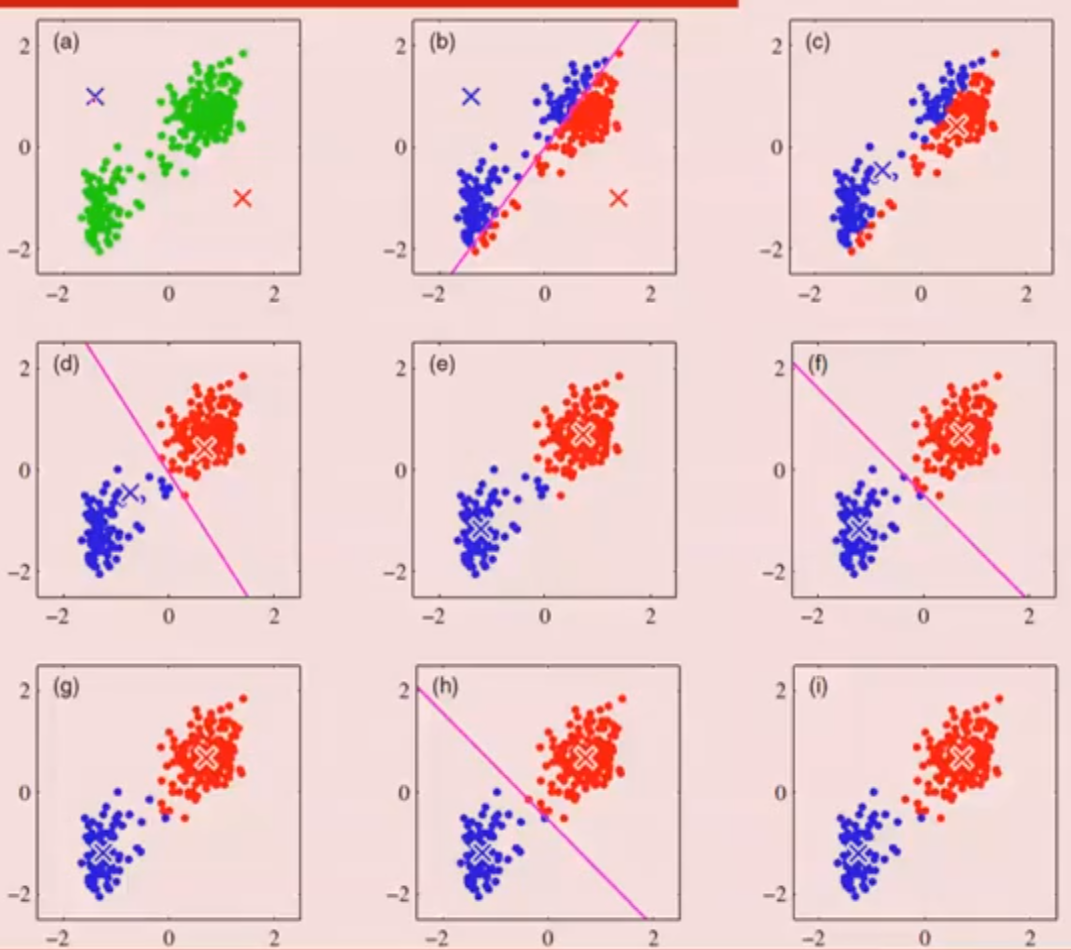
- 初值敏感
- k-means++多了根据距离加权更新距离中心的操作
- k-means的公式化解释
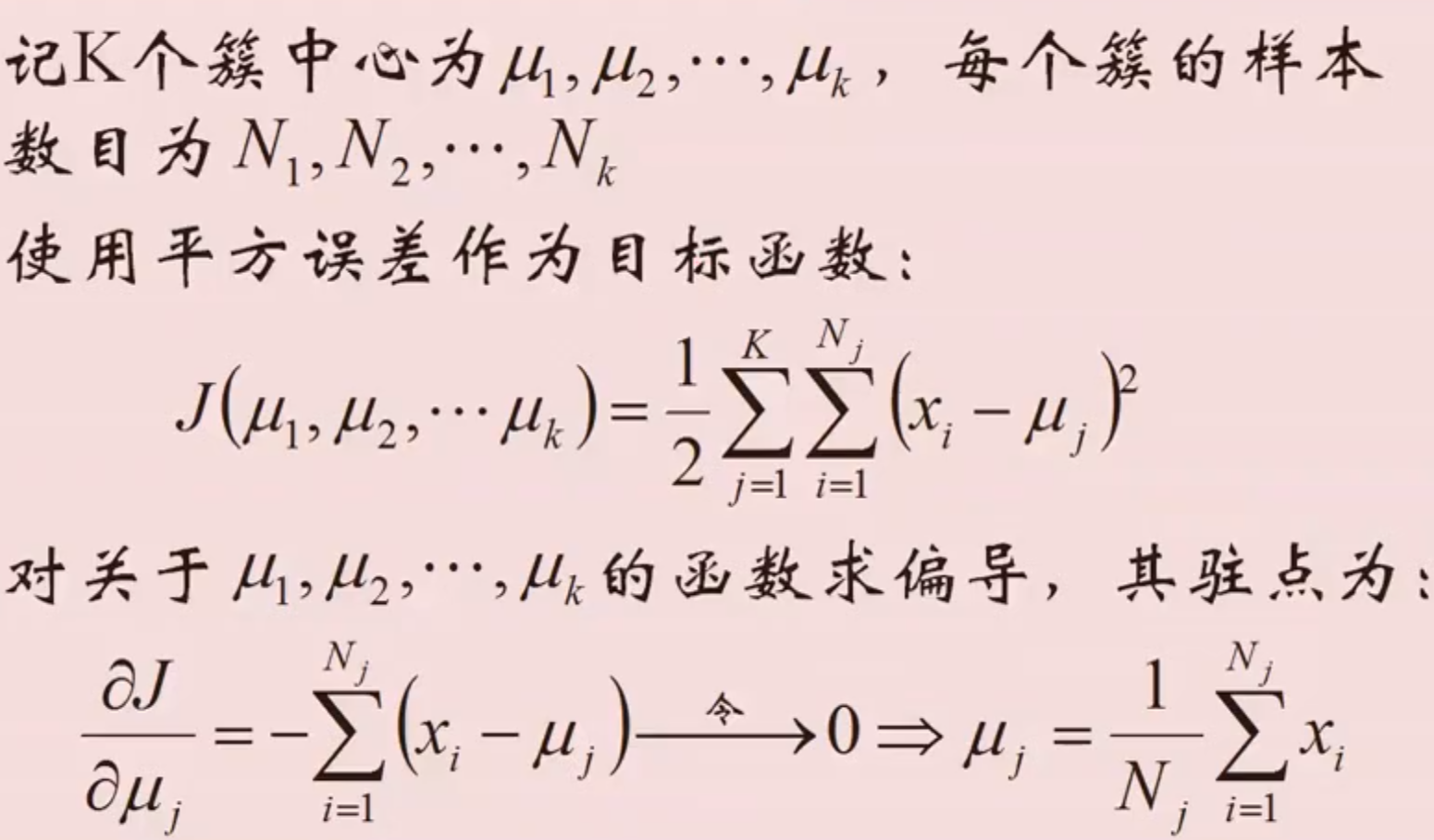
- k-means聚类方法总结

Canopy算法

聚类的衡量指标

ARI

AMI

轮廓系数


层次聚类

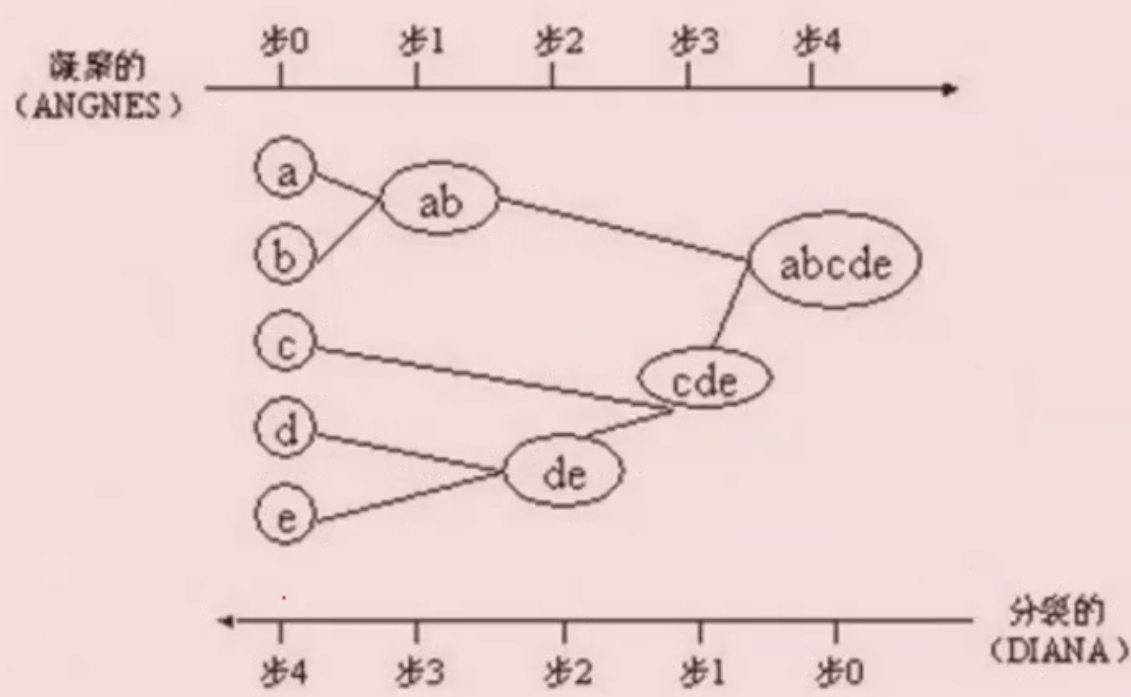
AGNES中簇间距离的不同定义

密度聚类方法

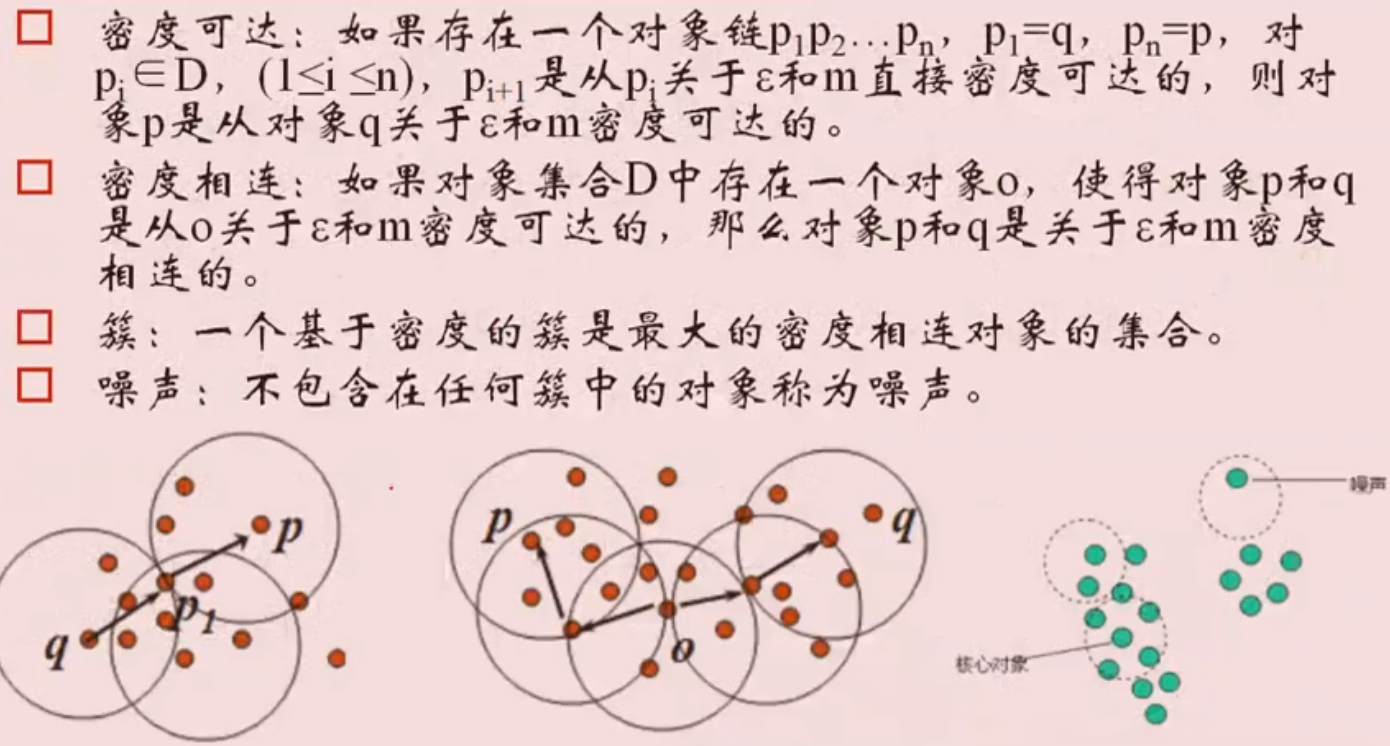
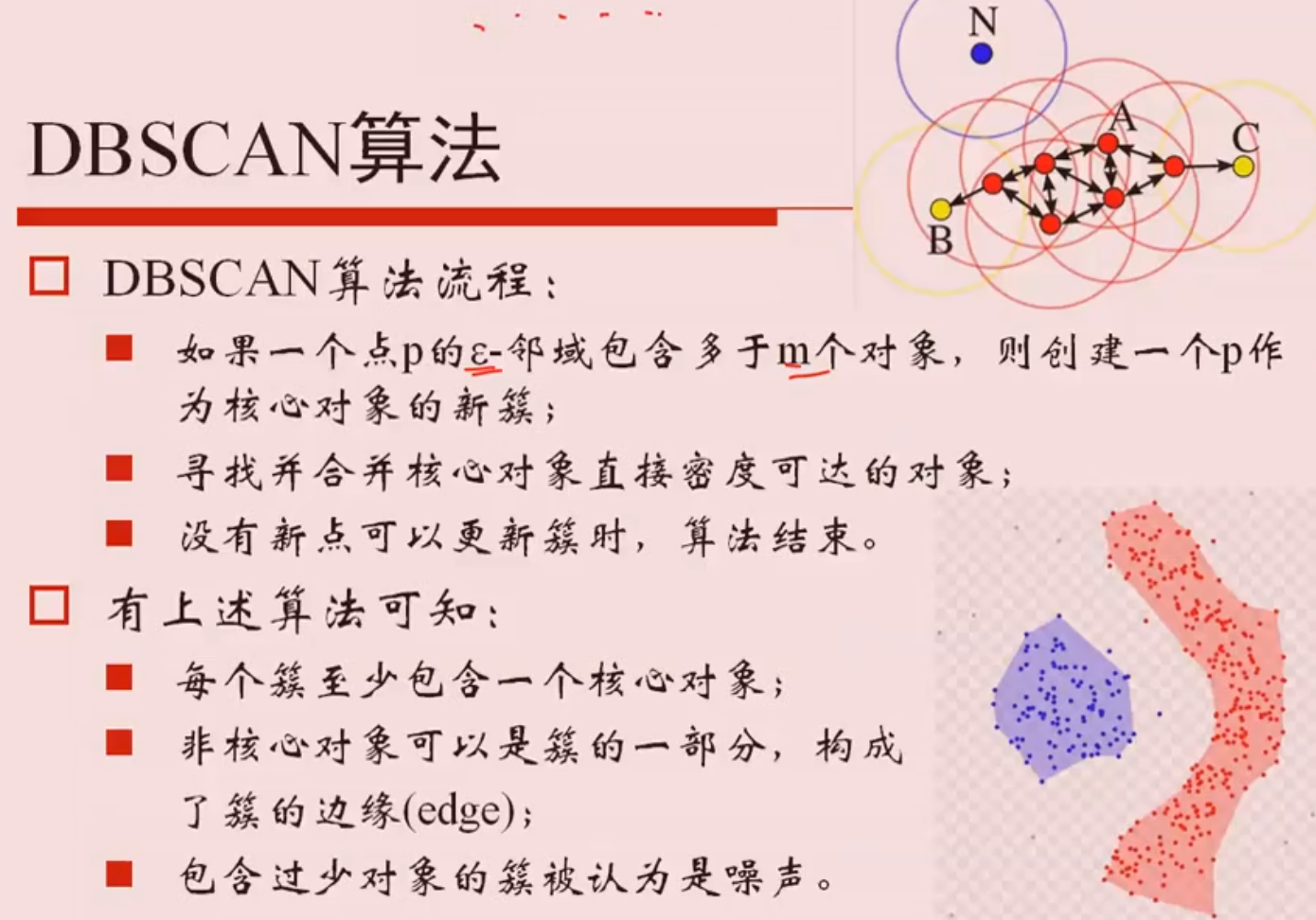
DBSCAN算法

- DBSCAN算法的若干概念

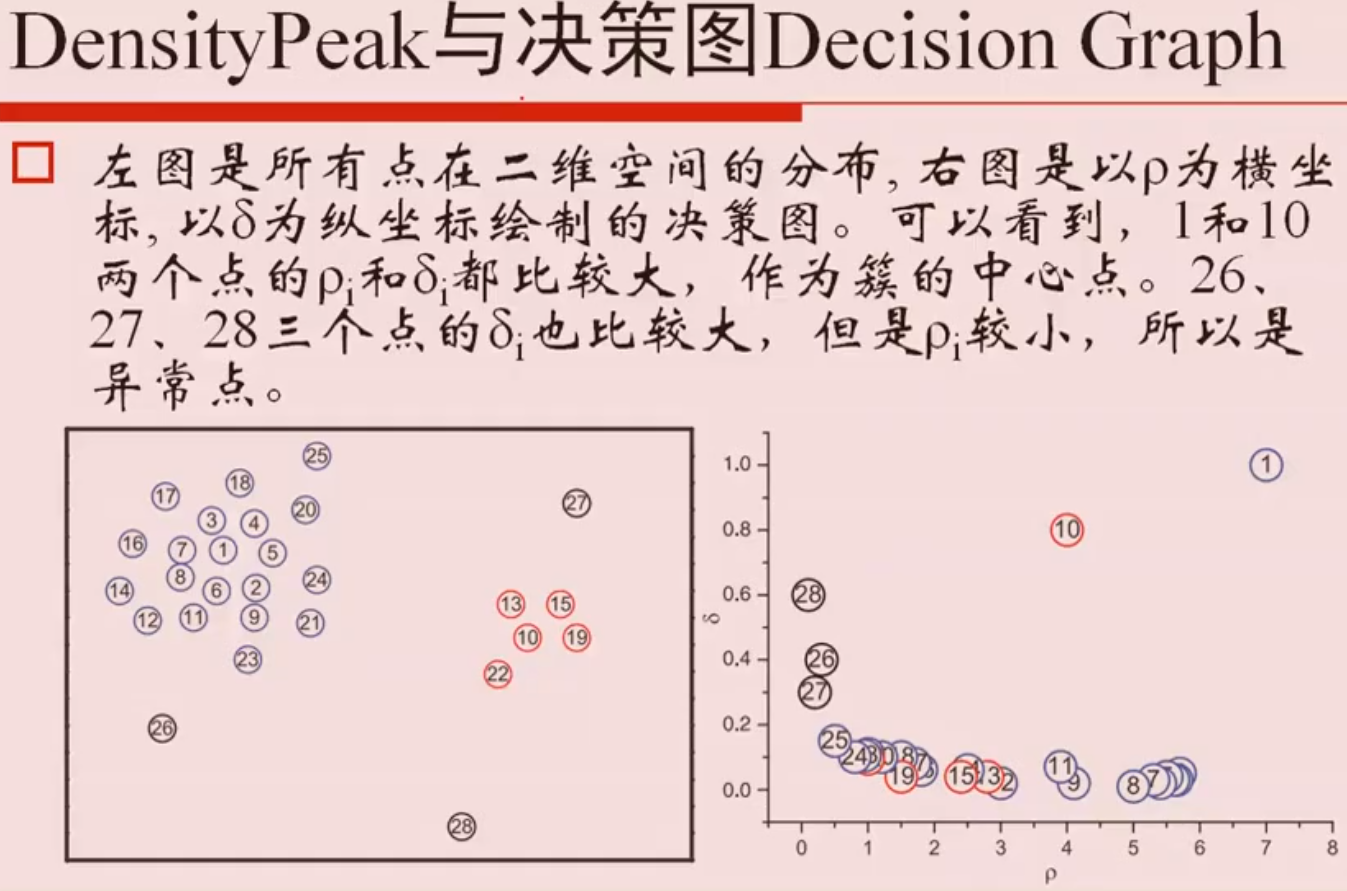
密度最大值聚类

局部密度的其他定义
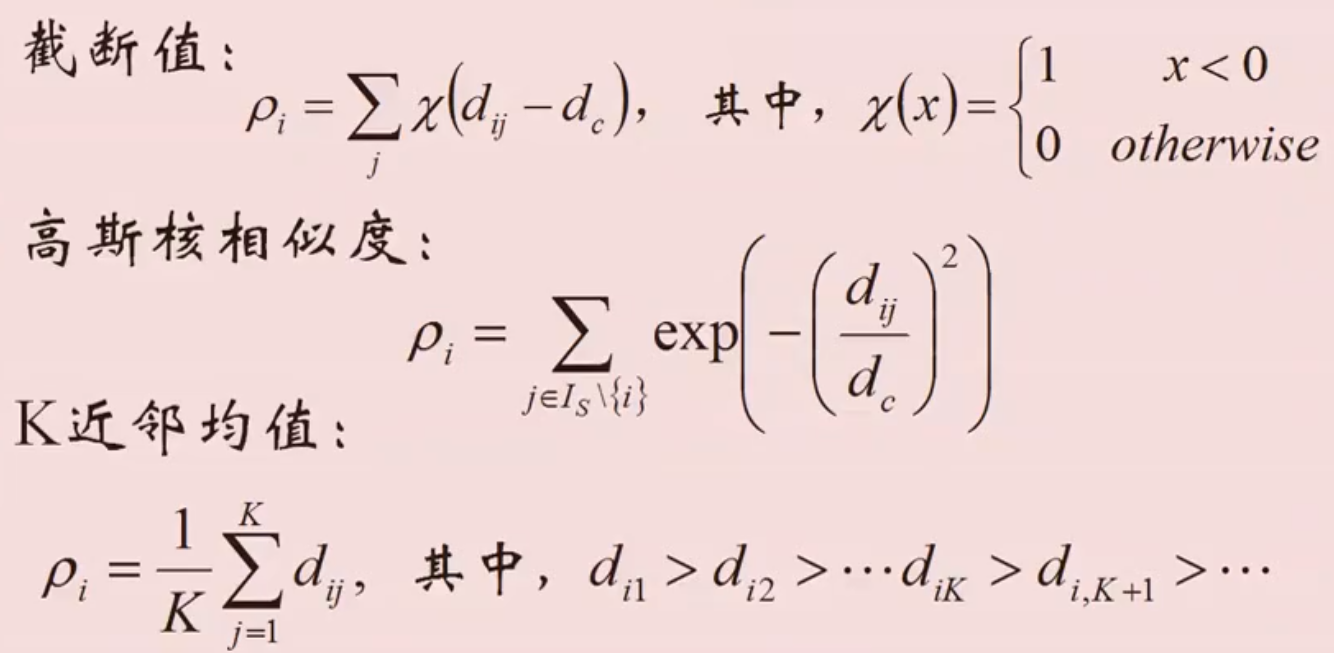
高局部密度点距离

簇中心的识别

边界和噪声的重认识

谱和谱聚类

谱分析的整体过程

若干概念
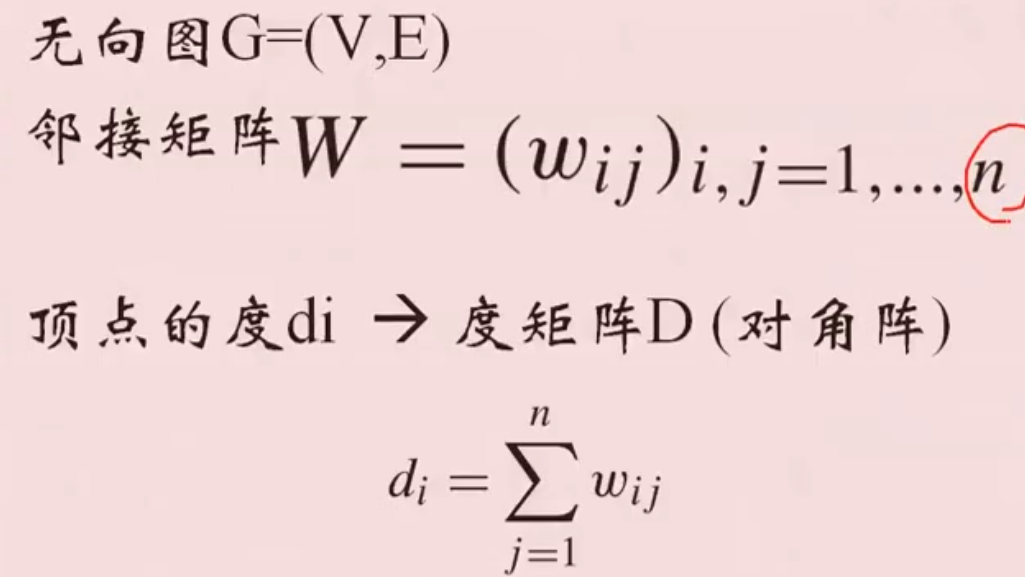
相似图G的建立方法

拉普拉斯矩阵及其性质
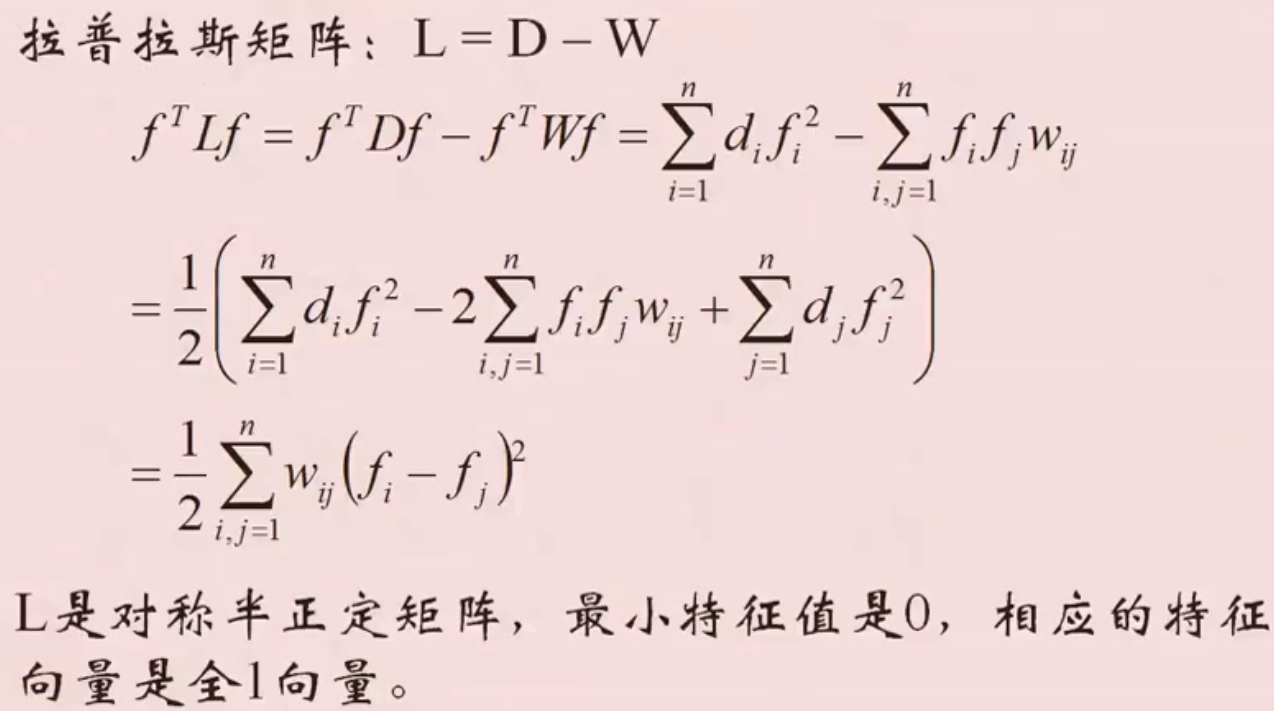
谱聚类算法:对称拉普拉斯矩阵

谱聚类算法:未正则拉普拉斯矩阵

谱聚类算法:随机游走拉普拉斯矩阵

- 随机游走和拉普拉斯矩阵的关系

进一步思考
