Hadoop生态构成
- HDFS:分布式文件系统
- ZKFC:为实现NameNode高可用,在NameNode和Zookeeper之间传递信息,选举主节点工具。
- NameNode:存储文件元数据
- DateNode:存储具体数据
- JournalNode:同步主NameNode节点数据到从节点NameNode
- MapReduce:开源的分布式批处理计算框架
- Spark:分布式基于内存的批处理框架
- Zookeeper:分布式协调管理
- Yarn:调度资源管理器
- HBase:基于HDFS的NoSql列式数据库
- Hive:将SQL转换为MapReduce进行计算
- Hue:是CDH的一个UI框架
- Impala:是Cloudra公司开发的一个查询系统,类似于Hive,可以通过SQL执行任务,但是它不基于MapReduce算法,而是直接执行分布式计算,这样就提高了效率。
- oozie:是一个工作流调度引擎,负责将多个任务组合在一起按序执行。
- kudu:Apache Kudu是转为hadoop平台开发的列式存储管理器。和impala结合使用,可以进行增删改查。
- Sqoop:将hadoop和关系型数据库互相转移的工具。
- Flume:采集日志
- 还有一些其它的
HDFS
hdfs的局限性
1)低延时数据访问。在用户交互性的应用中,应用需要在ms或者几个s的时间内得到响应。由于HDFS为高吞吐率做了设计,也因此牺牲了快速响应。对于低延时的应用,可以考虑使用HBase或者Cassandra。
2)大量的小文件。标准的HDFS数据块的大小是64M,存储小文件并不会浪费实际的存储空间,但是无疑会增加了在NameNode上的元数据,大量的小文件会影响整个集群的性能。
前面我们知道,Btrfs为小文件做了优化-inline file,对于小文件有很好的空间优化和访问时间优化。
3)多用户写入,修改文件。HDFS的文件只能有一个写入者,而且写操作只能在文件结尾以追加的方式进行。它不支持多个写入者,也不支持在文件写入后,对文件的任意位置的修改。
但是在大数据领域,分析的是已经存在的数据,这些数据一旦产生就不会修改,因此,HDFS的这些特性和设计局限也就很容易理解了。HDFS为大数据领域的数据分析,提供了非常重要而且十分基础的文件存储功能。
hdfs保证可靠性的措施
1)冗余备份
每个文件存储成一系列数据块(Block)。为了容错,文件的所有数据块都会有副本(副本数量即复制因子,课配置)(dfs.replication)
2)副本存放
采用机架感知(Rak-aware)的策略来改进数据的可靠性、高可用和网络带宽的利用率
3)心跳检测
NameNode周期性地从集群中的每一个DataNode接受心跳包和块报告,收到心跳包说明该DataNode工作正常
4)安全模式
系统启动时,NameNode会进入一个安全模式。此时不会出现数据块的写操作。
5)数据完整性检测
HDFS客户端软件实现了对HDFS文件内容的校验和(Checksum)检查(dfs.bytes-per-checksum)。
YARN
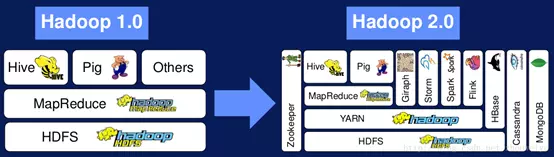
YARN是Hadoop从1.0升级至2.0出现的,hadoop1.0只支持MapReduce任务、资源利用率低。如图,Hadoop2.0中加入YARN使得hadoop中的编程模型有了除MapReduce外的更多选择,并且多种应用程序如MapReduce、Spark可以使用同一个数据集。
YARN中有四个基本组件:ResourceManager、NodeManager、ApplicationMaster、Container。
ResourceManager每个集群仅有一个,负责集群资源的统一管理和调度, NodeManager每个节点都有一个,负责单节点资源管理和调度。 每个应用程序有一个ApplicationMaster管理该应用程序。 Container是对任务运行资源的抽象,可以理解为一台计算机。
YARN的工作流程大致如下:

- 步骤1 client程序向YARN中提交应用程序,ResourceManager为该应用程序分配第一个Container,并与相应的NodeManager通信,要求它在这个Container中启动应用程序的ApplicationMaster。步骤2 ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后ApplicationMaster将为各个任务申请资源,并监控任务的运行状态,直到运行结束。
- 步骤3 ApplicationMaster向ResourceManager申请和获取资源,一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务。
- 步骤4 NodeManager启动任务。
- 步骤5 各个任务向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
- 步骤6 应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。
