Logger类提供了多种方法来处理日志活动。上一篇介绍了开源日志库Logger的使用,今天我主要来分析Logger实现的原理。
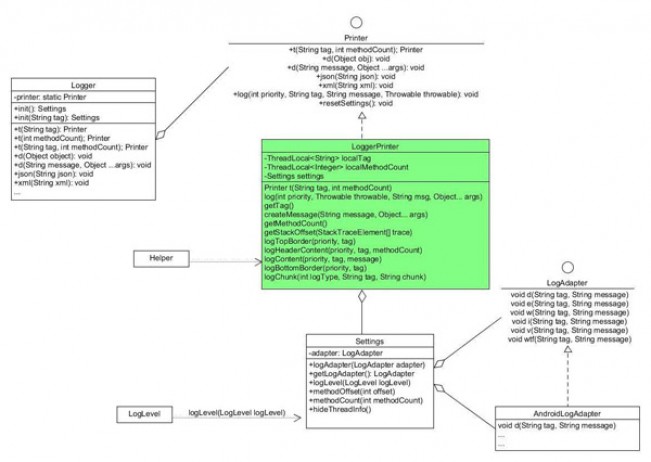
我们从使用的角度来对Logger库抽茧剥丝:
String userName = "Jerry";
Logger.i(userName);
看看Logger.i()这个方法:
public static void i(String message, Object... args) {
printer.i(message, args);
}
还有个可变参数,来看看printer.i(message, args)是啥:
public Interface Printer{
void i(String message, Object... args);
}
是个接口,那我们就要找到这个接口的实现类,找到printer对象在Logger类中声明的地方:
private static Printer printer = new LoggerPrinter();
实现类是LoggerPrinter,而且这还是个静态的成员变量,这个静态是有用处的,后面会讲到,那就继续跟踪LoggerPrinter类的i(String message, Object... args)方法的实现:
@Override public void i(String message, Object... args) {
log(INFO, null, message, args);
}
/**
* This method is synchronized in order to avoid messy of logs' order.
*/
private synchronized void log(int priority, Throwable throwable, String msg, Object... args) {
// 判断当前设置的日志级别,为NONE则不打印日志
if (settings.getLogLevel() == LogLevel.NONE) {
return;
}
// 获取tag
String tag = getTag();
// 创建打印的消息
String message = createMessage(msg, args);
// 打印
log(priority, tag, message, throwable);
}
public enum LogLevel {
/**
* Prints all logs
*/
FULL,
/**
* No log will be printed
*/
NONE
}
首先,log方法是一个线程安全的同步方法,为了防止日志打印时候顺序的错乱,在多线程环境下,这是非常有必要的。
其次,判断日志配置的打印级别,FULL打印全部日志,NONE不打印日志。
再来,getTag():
private final ThreadLocal<String> localTag = new ThreadLocal<>();
/**
* @return the appropriate tag based on local or global */
private String getTag() {
// 从ThreadLocal<String> localTag里获取本地一个缓存的tag
String tag = localTag.get();
if (tag != null) {
localTag.remove();
return tag;
}
return this.tag;
}
这个方法是获取本地或者全局的tag值,当localTag中有tag的时候就返回出去,并且清空localTag的值,关于ThreadLocal还不是很清楚的可以参考主席的文章:http://blog.csdn.net/singwhat...
接着,createMessage方法:
private String createMessage(String message, Object... args) {
return args == null || args.length == 0 ? message : String.format(message, args);
}
这里就很清楚了,为什么我们用Logger.i(message, args)的时候没有写args,也就是null,也可以打印,而且是直接打印的message消息的原因。同样博主上一篇文章也提到了:
Logger.i("博主今年才%d,英文名是%s", 16, "Jerry");
像这样的可以拼接不同格式的数据的打印日志,原来实现的方式是用String.format方法,这个想必小伙伴们在开发Android应用的时候String.xml里的动态字符占位符用的也不少,应该很容易理解这个format方法的用法。
重头戏,我们把tag,打印级别,打印的消息处理好了,接下来该打印出来了:
@Override public synchronized void log(int priority, String tag, String message, Throwable throwable) {
// 同样判断一次库配置的打印开关,为NONE则不打印日志
if (settings.getLogLevel() == LogLevel.NONE) {
return;
}
// 异常和消息不为空的时候,获取异常的原因转换成字符串后拼接到打印的消息中
if (throwable != null && message != null) {
message += " : " + Helper.getStackTraceString(throwable);
}
if (throwable != null && message == null) {
message = Helper.getStackTraceString(throwable);
}
if (message == null) {
message = "No message/exception is set";
}
// 获取方法数
int methodCount = getMethodCount();
// 判断消息是否为空
if (Helper.isEmpty(message)) {
message = "Empty/NULL log message";
}
// 打印日志体的上边界
logTopBorder(priority, tag);
// 打印日志体的头部内容
logHeaderContent(priority, tag, methodCount);
//get bytes of message with system's default charset (which is UTF-8 for Android)
byte[] bytes = message.getBytes();
int length = bytes.length;
// 消息字节长度小于等于4000
if (length <= CHUNK_SIZE) {
if (methodCount > 0) {
// 方法数大于0,打印出分割线
logDivider(priority, tag);
}
// 打印消息内容
logContent(priority, tag, message);
// 打印日志体底部边界
logBottomBorder(priority, tag);
return;
}
if (methodCount > 0) {
logDivider(priority, tag);
}
for (int i = 0; i < length; i += CHUNK_SIZE) {
int count = Math.min(length - i, CHUNK_SIZE);
//create a new String with system's default charset (which is UTF-8 for Android)
logContent(priority, tag, new String(bytes, i, count));
}
logBottomBorder(priority, tag);
}
我们重点来看看logHeaderContent方法和logContent方法:
@SuppressWarnings("StringBufferReplaceableByString")
private void logHeaderContent(int logType, String tag, int methodCount) {
// 获取当前线程堆栈跟踪元素数组
//(里面存储了虚拟机调用的方法的一些信息:方法名、类名、调用此方法在文件中的行数)
// 这也是这个库的 “核心”
StackTraceElement[] trace = Thread.currentThread().getStackTrace();
// 判断库的配置是否显示线程信息
if (settings.isShowThreadInfo()) {
// 获取当前线程的名称,并且打印出来,然后打印分割线
logChunk(logType, tag, HORIZONTAL_DOUBLE_LINE + "Thread: " + Thread.currentThread().getName()); logDivider(logType, tag);
}
String level = "";
// 获取追踪栈的方法起始位置
int stackOffset = getStackOffset(trace) + settings.getMethodOffset();
//corresponding method count with the current stack may exceeds the stack trace. Trims the count
// 打印追踪的方法数超过了当前线程能够追踪的方法数,总的追踪方法数扣除偏移量(从调用日志的起算扣除的方法数),就是需要打印的方法数量
if (methodCount + stackOffset > trace.length) {
methodCount = trace.length - stackOffset - 1;
}
for (int i = methodCount; i > 0; i--) {
int stackIndex = i + stackOffset;
if (stackIndex >= trace.length) {
continue;
}
// 拼接方法堆栈调用路径追踪字符串
StringBuilder builder = new StringBuilder();
builder.append("U ")
.append(level)
.append(getSimpleClassName(trace[stackIndex].getClassName())) // 追踪到的类名
.append(".")
.append(trace[stackIndex].getMethodName()) // 追踪到的方法名
.append(" ")
.append(" (")
.append(trace[stackIndex].getFileName()) // 方法所在的文件名
.append(":")
.append(trace[stackIndex].getLineNumber()) // 在文件中的行号
.append(")");
level += " ";
// 打印出头部信息
logChunk(logType, tag, builder.toString());
}
}
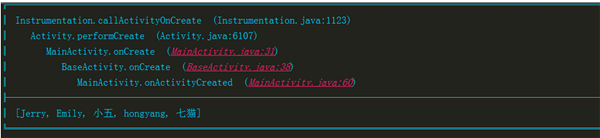
接下来看logContent方法:
private void logContent(int logType, String tag, String chunk) {
// 这个作用就是获取换行符数组,getProperty方法获取的就是"//n"的意思
String[] lines = chunk.split(System.getProperty("line.separator"));
for (String line : lines) {
// 打印出包含换行符的内容
logChunk(logType, tag, HORIZONTAL_DOUBLE_LINE + " " + line);
}
}
如上图来说内容是字符串数组,本身里面是没用换行符的,所以不需要换行,打印出来的效果就是一行,但是json、xml这样的格式是有换行符的,所以打印呈现出来的效果就是:
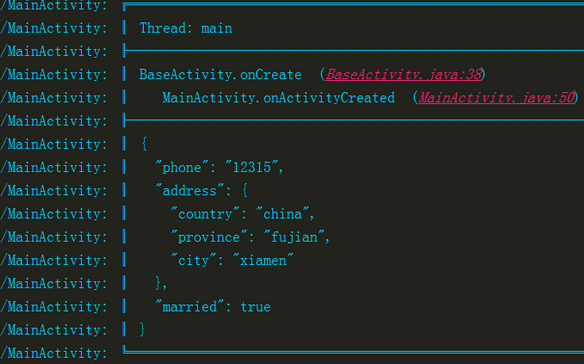
上面说了大半天,都还没看到具体的打印是啥,现在来看看logChunk方法:
private void logChunk(int logType, String tag, String chunk) {
// 最后格式化下tag
String finalTag = formatTag(tag);
// 根据不同的日志打印类型,然后交给LogAdapter这个接口来打印
switch (logType) {
case ERROR:
settings.getLogAdapter().e(finalTag, chunk);
break;
case INFO:
settings.getLogAdapter().i(finalTag, chunk);
break;
case VERBOSE:
settings.getLogAdapter().v(finalTag, chunk);
break;
case WARN:
settings.getLogAdapter().w(finalTag, chunk);
break;
case ASSERT:
settings.getLogAdapter().wtf(finalTag, chunk);
break;
case DEBUG:
// Fall through, log debug by default
default:
settings.getLogAdapter().d(finalTag, chunk);
break;
}
}
这个方法很简单,就是最后格式化tag,然后根据不同的日志类型把打印的工作交给LogAdapter接口来处理,我们来看看settings.getLogAdapter()这个方法(Settings.java文件):
public LogAdapter getLogAdapter() {
if (logAdapter == null) {
// 最终的实现类是AndroidLogAdapter
logAdapter = new AndroidLogAdapter();
}
return logAdapter;
}
找到AndroidLogAdapter类:
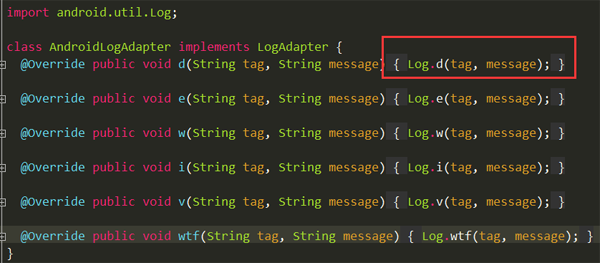
原来绕了一大圈,最终打印还是使用了:系统的Log。
好了Logger日志框架的源码解析完了,有没有更清晰呢,也许小伙伴会说这个最终的日志打印,我不想用系统的Log,是不是可以换呢。这是自然的,看开篇的那种整体架构图,这个LogAdapter是个接口,只要实现这个接口,里面做你自己想要打印的方式,然后通过Settings 的logAdapter(LogAdapter logAdapter)方法设置进去就可以。
以上就是博主分析一个开源库的思路,从使用的角度出发抽茧剥丝,基本上一个库的核心部分都能搞懂。画画整个框架的大概类图,对分析库非常有帮助,每一个轮子都有值得学习的地方,吸收了就是进步的开始,耐心的分析完一个库,还是非常有成就感的。
本文转载地址:https://www.linuxprobe.com/open-logger-analysiss.html