| 导读 | 目前的迁移技术,都是通过向QEMUFILE中直接写入裸内存数据来达到传送虚拟机的目的端,这种情况下,发送的数据量大,从而会导致更高的迁移时间(total time)和黑宕时间(downtime)。本文介绍的方法,在发送前对客户机内存进行压缩,在目的端接收到内存后,进行对数据进行解压缩,从而恢复客户机的内存。 |
使用带压缩技术的迁移后,传输的数据总量会减少60%,总迁移时间减少70%+,同时宕机时间减少50%以上。一方面,压缩/解压缩的过程会消耗CPU周期而加大了迁移的时间;另一方面,总传输数据量的锐减,又会减少迁移时间。为了能够进行高速的压缩,本技术中使用了多线程并发的方式,提高压缩的目前虚拟机中,使用ZLIB完成压缩/解压缩的工作。
在CPU相同的情况下,ZLIB官方给出,解压缩的速度是压缩速度的4倍。也就是说,如果迁移的源端和目的端处理器相同的情况下,使得压缩线程数量是解压缩线程数量的4倍就可以在资源消耗最小的情况下,取得最优的压缩为了更多的适应网络状况,虚拟机中引入了压缩级别 -- Compression level。Compression level可以用来控制压缩速率和压缩比例。高的压缩比率会消耗更多的时间,level 0就代表不进行压缩, 1级代表最优的压缩速率, 9级代表了最好的压缩比率(最多的压缩时间)。我们可以选择从0级到9级中的任意一个级别。
压缩/解压缩时间将会消耗CPU周期。所以,如果整个系统CPU都被压得非常满的情况下,避免使用这个特性。当网络带宽有限,CPU资源又足够充足的情况下,使用多线程压缩动态迁移技术会带来比较好的效果。当网络充足且CPU资源充足的情况下,使用本技术也将会减少总迁移时间。
1. 启动虚拟机
/home/liufeng/qemu-system-x86_64 -machine accel=kvm -hda ./disk0.img -m 2048 -vnc 192.168.2.106:0 -monitor stdio
2. 使能源端多线程压缩动态迁移技术
a.) migrate_set_capabilitycompress on //使能压缩 b.) migrate_set_parametercompress-threads 12 //12个压缩线程 c.) migrate_set_parametercompress-level 1 //压缩级别为1级
3. 开始迁移
migrate -d tcp:192.168.2.105:6666
1. 启动虚拟机
/home/liufeng/qemu-system-x86_64 -machine accel=kvm -hda /home/kvm/vm/disk/disk0.img -m 2048 -vnc 192.168.2.105:0 -monitor stdio -incoming tcp:192.168.2.105:6666
2. 使能目的端多线程压缩动态迁移技术
a.) migrate_set_capabilitycompress on b.) migrate_set_parametercompress-level 1 c.) migrate_set_parameterdecompress-threads 3 //3个压缩线程
3. 等待迁移完成
CPU: Intel(R) Xeon(R) CPU E5-2650 v3 @2.30GHz
Logic core: 40
Socket : 2
RAM: 128G
NIC: 1000baseT/Full
Host OS: CentOSLinux release 7.2.1511 (Core) 64-bit
Guest OS: CentOS Linux release 7.2.1511 (Core) 64-bit
| 原动态迁移 | 多线程压缩技术动态迁移
压缩级别: 1 压缩线程数: 12 解压缩线程数:3 |
|
| 迁移总时间(msec): | 9536 | 4466 |
| Downtime时间(msec): | 34 | 22 |
| 传输数据量(KB) | 307783 | 140445 |
效果:总的迁移时间减少50%;downtime时间减少35%
| 原动态迁移 | 多线程压缩技术动态迁移
压缩级别: 1 压缩线程数: 12 解压缩线程数:3 |
|
| 迁移总时间(msec): | 11720 | 5652 |
| Downtime时间(msec): | 169 | 21 |
| 传输数据量(KB) | 311554 | 140189 |
效果:总迁移时间减少了200%,downtime时间减少了800%
虚拟机实现代码分析如下(本分析基于:QEMU 2.5):

有migration_thread()进行迁移工作,在iterator和complete阶段,如果发现使能了多线程压缩技术,则通过compress_page_with_multi_thread()完成数据的压缩和发送
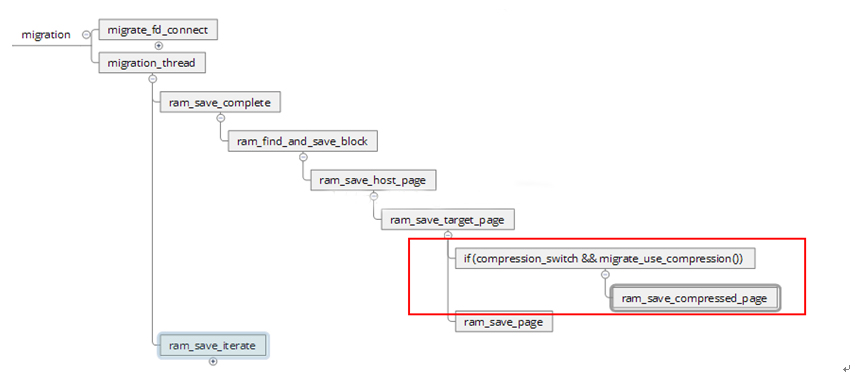
最终在compress_page_with_multi_thread()中激活压缩线程,通过zlib的compress2()函数完成数据的压缩,并通过QEMU-FILE发送
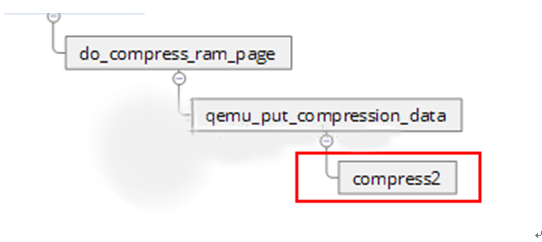
1. 压缩算法
a. 目前使用的是开源zlib库完成压缩,还有其他压缩库的压缩方式可以提供,以便适应更多的场景
b. 商业压缩库有着更好的效率
c. 通过FPGA进行硬件辅助压缩
2. 压缩策略
a. 虚拟机迁移算法自适应所有网络,对网络进行测试(是否满足上面的公式),然后形成反馈因子输入到迁移算法中,迁移算法根据反馈因子决定使用的压缩算法、压缩级别或者根本不压缩,达到在所有网络状况下而缩短downtime的目的。
免费提供最新Linux技术教程书籍,为开源技术爱好者努力做得更多更好:https://www.linuxprobe.com/