注意:本文不讨论linux虚拟机的安装和docker的安装
1、环境
1.1、宿主机
内核版本:Linux localhost 3.16.0-4-amd64 #1 SMP Debian 3.16.7-ckt25-2 (2016-04-08) x86_64 GNU/Linux
系统版本:Debian 8
1.2、docker
版本:Docker version 1.9.1, build a34a1d5
镜像版本:crxy/centos

2、宿主机中创建用户和分组
2.1、创建docker用户组
sudo groupadd docker
2.2、添加当前用户到docker用户组里
sudo gpasswd -a *** docker 注:***为当前系统用户名
2.3、重启docker后台监控进程
sudo service docker restart
2.4、重启后,看docker服务是否生效
docker version
2.5、如果没有生效,可以重试重启系统
sudo reboot
3、Dockerfile创建docker镜像
3.1创建ssh功能镜像,并设置镜像账号:root密码:root
cd /usr/local/
mkdir dockerfile
cd dockerfile/
mkdir centos-ssh-root
cd centos-ssh-root
vi Dockerfile 注:docker识别的dockerfile格式Dockerfile(首字母必须大写)
# 选择一个已有的os镜像作为基础FROM centos# 镜像的作者MAINTAINER crxy# 安装openssh-server和sudo软件包,并且将sshd的UsePAM参数设置成noRUN yum install -y openssh-server sudoRUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config#安装openssh-clientsRUN yum install -y openssh-clients# 添加测试用户root,密码root,并且将此用户添加到sudoers里RUN echo "root:root" | chpasswdRUN echo "root ALL=(ALL) ALL" >> /etc/sudoers# 下面这两句比较特殊,在centos6上必须要有,否则创建出来的容器sshd不能登录RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_keyRUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key# 启动sshd服务并且暴露22端口RUN mkdir /var/run/sshdEXPOSE 22CMD ["/usr/sbin/sshd", "-D"]
创建镜像命令:
docker build -t=’crxy/centos-ssh-root‘ .
创建完成后查看镜像生成情况:
docker images

3.2、创建jdk镜像
注:jdk使用1.7版本及以上版本
cd ..
mkdir centos-ssh-root-jdk
cd centos-ssh-root-jdk
cp ../../jdk-7u80-linux-x64.tar.gz .
vi Dockerfile
#上一步中生成的镜像FROM crxy/centos-ssh-rootADD jdk-7u75-linux-x64.tar.gz /usr/local/RUN mv /usr/local/jdk1.7.0_75 /usr/local/jdk1.7ENV JAVA_HOME /usr/local/jdk1.7ENV PATH $JAVA_HOME/bin:$PATH
创建镜像命令:
docker build -t=’crxy/centos-ssh-root-jdk‘ .
创建完成后查看镜像生成情况:
docker images

3.3、根据jdk镜像创建hadoop镜像
cd ..
mkdir centos-ssh-root-jdk-hadoop
cd centos-ssh-root-jdk-hadoop
cp ../../hadoop-2.2.0.tar.gz .
vi Dockerfile
#从crxy/centos-ssh-root-jdk版本创建FROM crxy/centos-ssh-root-jdkADD hadoop-2.2.0-src.tar.gz /usr/local#安装which软件包RUN yum install which#安装net-tools软件包RUM yum install net-toolsENV HADOOP_HOME /usr/local/hadoop-2.2.0ENV PATH $HADOOP_HOME/bin:$PATH
创建镜像命令:
docker build -t=’crxy/centos-ssh-root-jdk-hadoop‘ .
创建完成后查看镜像生成情况:
docker images

4、搭建hadoop分布式集群
4.1、hadoop集群规划
master:hadoop0 ip:172.17.0.10
slave1:hadoop1 ip:172.17.0.10
slave2:hadoop2 ip:172.17.0.10
查看docker桥接网卡dcker0

4.2、创建容器并启动容器,hadoop0、hadoop1、hadoop2
#主节点docker run --name hadoop0 --hostname hadoop0 -d -P -p 50070:50070 -p 8088:8088 crxy/centos-ssh-root-jdk-hadoop#nodedocker run --name hadoop1 --hostname hadoop1 -d -P crxy/centos-ssh-root-jdk-hadoop#nodedocker run --name hadoop2 --hostname hadoop2 -d -P crxy/centos-ssh-root-jdk-hadoop
查看容器:docker ps -a
 4.3、为hadoop集群设置固定ip
4.3、为hadoop集群设置固定ip
4.3.1、下载pipework
https://github.com/jpetazzo/pipework.git
4.3.2、把下载的zip包上传到宿主机服务器上,解压,改名字
unzip pipework-master.zipmv pipework-master pipeworkcp -rp pipework/pipework /usr/local/bin/
4.3.3、安装bridge-utils
yum -y install bridge-utils
4.3.4、给容器设置固定ip
pipework docker0 hadoop0 172.17.0.10/24pipework docker0 hadoop1 172.17.0.11/24pipework dcoker0 hadoop2 172.17.0.12/24
4.3.5、验证ip是否通
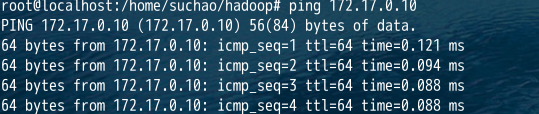
4.4、配置hadoop0
4.4.1、链接hadoop0
docker exec -it hadoop0 /bin/bash
4.4.2、为hadoop0添加host
vi /etc/hosts
172.17.0.10 hadoop0172.17.0.11 hadoop1172.17.0.12 hadoop2
4.4.3、hadoop0上修改hadoop的配置文件
cd /usr/local/hadoop/etc/hadoop-2.2.0
修改四大配置文件:core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml
1)、hadoop-env.sh
#导入环境变量export JAVA_HOME=/usr/local/jdk1.7
2)、core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://hadoop0:9000</value></property><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop/tmp</value></property><property><name>fs.trash.interval</name><value>1440</value></property></configuration>
3)、hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.permissions</name><value>false</value></property></configuration>
4)、yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><description>The hostname of the RM.</description><name>yarn.resourcemanager.hostname</name><value>hadoop0</value></property></configuration>
5)、mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
4.4.4、格式化hdfs
bin/hdfs namenode -format
4.5、配置hadoop1、hadoop2、
4.5.1、执行4.4配置
4.6、切回到hadoop0,执行ssh免密码登陆
4.6.1 、配置ssh
cd ~mkdir .sshcd .sshssh-keygen -t rsa(一直按回车即可)ssh-copy-id -i localhostssh-copy-id -i hadoop0ssh-copy-id -i hadoop1ssh-copy-id -i hadoop2在hadoop1上执行下面操作cd ~cd .sshssh-keygen -t rsa(一直按回车即可)ssh-copy-id -i localhostssh-copy-id -i hadoop1在hadoop2上执行下面操作cd ~cd .sshssh-keygen -t rsa(一直按回车即可)ssh-copy-id -i localhostssh-copy-id -i hadoop2
4.6.2、配置slaves
vi etc/hadoop/slaves
hadoop1hadoop2
4.6.3、执行远程复制
scp -rq /usr/local/hadoop-2.2.0 hadoop1:/usr/localscp -rq /usr/local/hadoop-2.2.0 hadoop2:/usr/local
5、启动hadoop集群
5.1、启动
hadoop namenode -format -clusterid clustername
cd /usr/local/hadoop-2.2.0
sbin/start-all.sh
5.2、验证集群启动是否正常
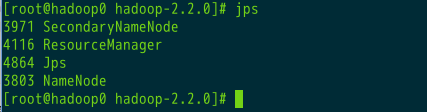
5.2.1、hadoop0
jps
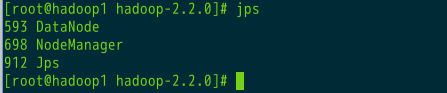
5.2.2、hadoop1
jps
5.2.3、hadoop2
jps

5.3、验证hafs文件系统状态
bin/hdfs dfsadmin -report
6、测试hdfs、yarn是否正常
6.1、创建普通文件在master主机上(hadoop0)
1)、查看文件系统中是否有文件存在
hadoop fs -ls

2)、创建dfs文件夹,#默认/user/$USER
hadoop fs -mkdir /user/data

3)、创建普通文件在用户文件夹
4)、将文件写入dfs文件系统中
hadoop fs -put /home/suchao/data/1.txt /user/data
5)、在终端显示
hadoop fs -cat /user/data/1.txt

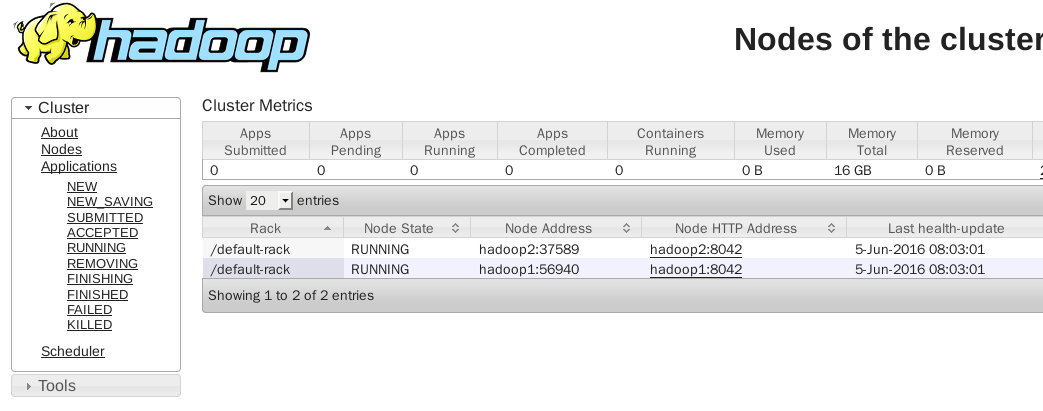
摘自:http://blog.csdn.net/xu470438000/article/details/50512442