1、什么是PromQL???
PromQL是Prometheus内置的数据查询语言,其提供对时间序列数据丰富的查询,聚合以及逻辑运算能力的支持。并且被广泛应用在Prometheus的日常应用当中,包括对数据查询、可视化、告警处理当中。前面的笔记当中有说道我们通过exporter采集到的数据是以时间序列(time-series)的方式保存在内存数据库中,并定时保存到硬盘。time-series是一个按照时间戳和值的顺序存放,可以说是一种矢量值。
什么是矢量值???就是已知x轴和y轴,得出x和y交叉点的那个值就是矢量值,而这里的time-series就是这样的一个值,每条time-series通过指标名称(metrics name)和一组标签(labels)命名,比如前面的node_memory_MemFree_bytes{instance="node02",job="node02"},"node_memory_MemFree_bytes"为指标名称,{ }内的为标签集合。
metrics通常固定的格式为:
<metric name>{<label name>=<label value>, ...}
指标名称只能由ASCII字符、数字、下划线以及冒号组成并必须符合正则表达式[a-zA-Z_:][a-zA-Z0-9_:]*
其中以__作为前缀的标签,是系统保留的关键字,只能在系统内部使用。标签的值则可以包含任何Unicode编码的字符。在Prometheus的底层实现中指标名称实际上是以__name__=
node_cpu_seconds_total{mode='idle'} 和
{__name__="node_cpu_seconds_total",mode='idle'}
是一样的!!!!
前面也说明了metrics的类型:
-
counter:递增计算器 --> 用于递增类的指标,如请求的总速率http_request_total,一般用_total作后缀。
-
gauge:可增可减仪表盘 --> 用于统计内存,硬盘的使用率,如node_memory_MemFree_bytes。
-
hitogram/summary:统计和分析样本分布情况 --> 通俗地说统计一段时间内的量化指标,比如cpu的平均使用率,页面响应等等。
2、如何查询???
2.1、监控指标名称查询
通过监控指标名称查询,也就是我们上面metrics的名称,而通过指标名称查询又可以分为完全匹配和正则匹配查询。
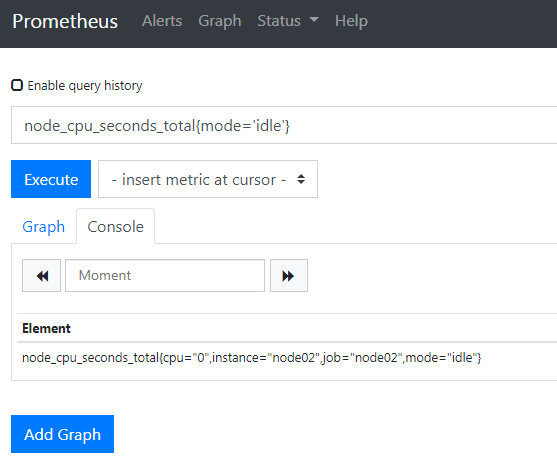
完全匹配查询,即 metrics_name{xxx=ooo 或 metrics_name{xxx!=ooo} ,如:
# 如下查询了cpu的空闲和非空闲时的使用时间
node_cpu_seconds_total{mode='idle'} 或 node_cpu_seconds_total{mode!='idle'}

正则匹配查询,即 metrics_name{xxx=~"ooo"} 或 metrics_name{xxx=~"ooo",zzz!=777}
pushgateway_http_requests_total{instance=~"pushgateway",method='get'}
或
pushgateway_http_requests_total{instance=~"pushgateway",method!='get'}
2.2、范围查询
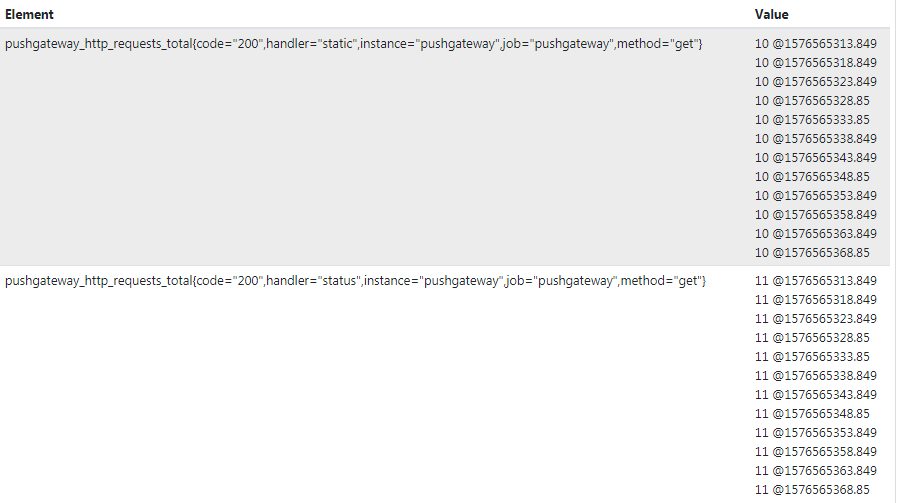
直接通过监控名称进行查询时间序列,直接返回的是一个瞬时矢量值,当我们需要获取一个时段的样本数据时,则需要使用区间矢量表达式,和瞬时矢量值的区别在于区间矢量值可以进行自定义查询的时间范围,比如统计5分钟内的数据,那么久可以通过时间范围选择器"[ ]"进行自定义。如:
pushgateway_http_requests_total{instance=~"pushgateway",method='get'}[1m]
将会返回这1分钟内的所有统计数据,除了用m表示分钟,还可以用s-秒,h-小时,d-天,w-周,y-年
2.3、时间位移查询
使用时间范围查询,也只是以当前时间作为基准去进行统计,如果要统计昨天1天的统计数据时,就需要用到时间位移(offset),如下:
# 统计昨天一天的pushgateway中包含get请求的总请求数
pushgateway_http_requests_total{instance=~"pushgateway",method='get'} offset 1d

2.4、聚合查询
一般来说,如果描述样本特征的标签(label)在并非唯一的情况下,通过PromQL查询数据,会返回多条满足这些特征维度的时间序列。而PromQL提供的聚合操作可以用来对这些时间序列进行处理,形成一条新的时间序列:
# 查询昨天1天内pushgeteway中get的请求总量之和
sum(pushgateway_http_requests_total{instance=~"pushgateway",method='get'} offset 1d)
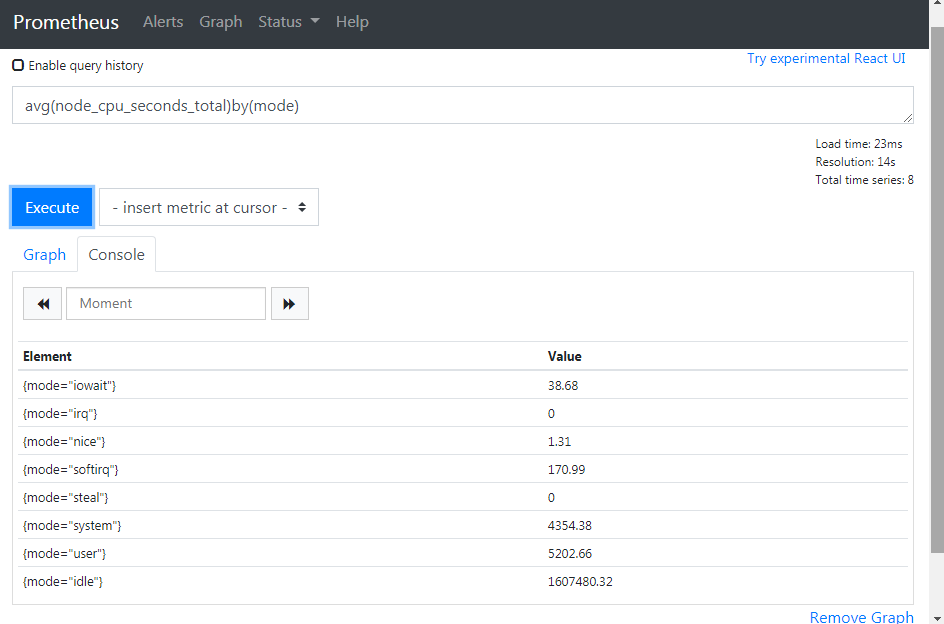
# 按照mode计算主机CPU的平均使用时间
avg(node_cpu_seconds_total)by(mode)