Prometheus简介和架构
Prometheus 是由 SoundCloud 开源监控告警解决方案。架构图如下:
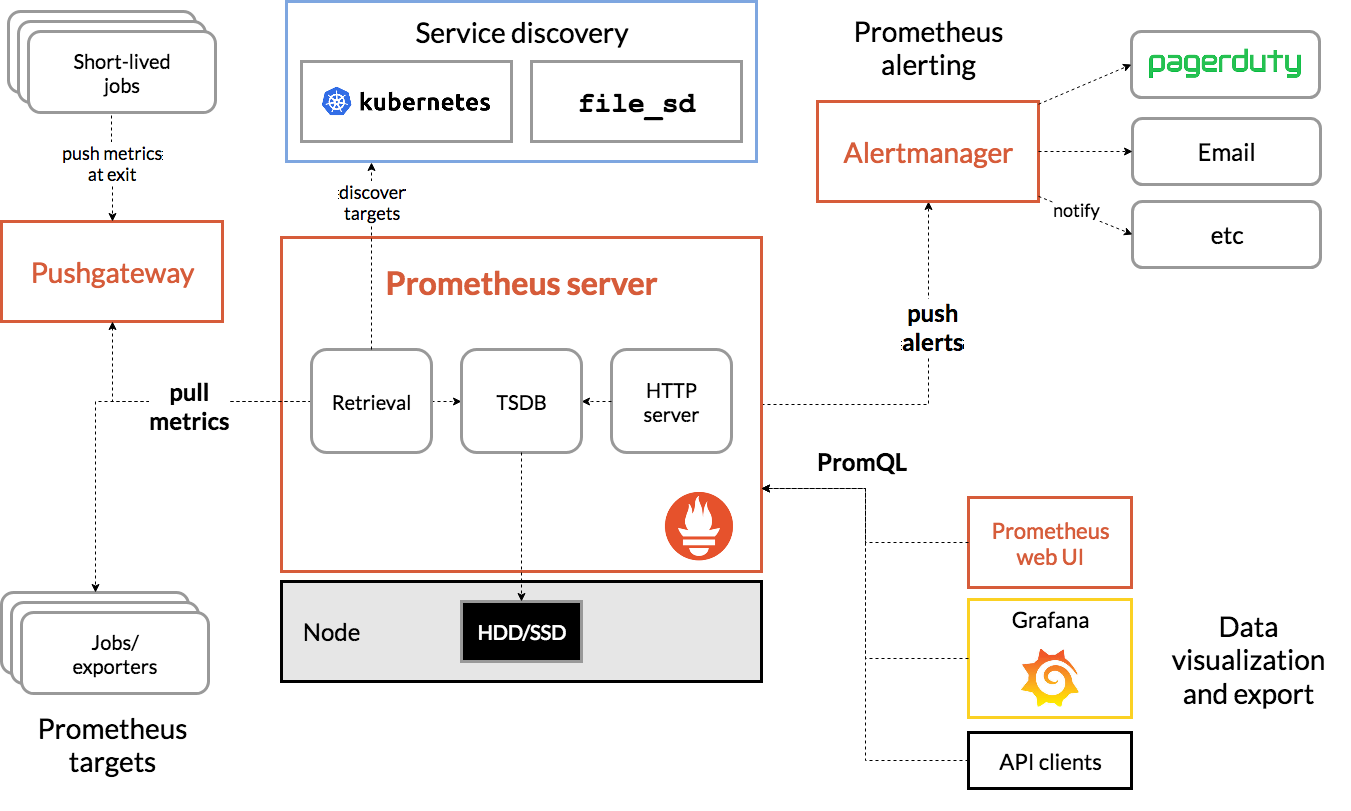
如上图,Prometheus主要由以下部分组成:
- Prometheus Server:用于抓取和存储时间序列化数据
- Exporters:主动拉取数据的插件
- Pushgateway:被动拉取数据的插件
- Altermanager:告警发送模块
- Prometheus web UI:界面化,也包含结合Grafana进行数据展示或告警发送
prometheus本身是一个以进程方式启动,之后以多进程和多线程实现监控数据收集、计算、查询、更新、存储的这样一个C/S模型运行模式。了解以下疑问信息
1、Prometheus是如何存储数据的???
prometheus采用time-series(时间序列)方式,存储在本地硬盘
-
prometheus本地T-S数据库以每2小时间隔来分block(块)存储,每个块又分为多个chunk文件,chunk文件用来存放采集的数据的T-S(time-series)数据,metadata和索引文件;
-
index文件是对metrics和labels进行索引之后存储在chunk中,chunk是作为基本存储单位,index和metadata作为子集;
-
prometheus平时采集到的数据先存放在内存之中,对内存消耗大,以缓存的方式可以加快搜索和访问;
-
在prometheus宕机时,prometheus有一种保护机制WAL,可以将数据定期存入硬盘中以chunk来表示,在重新启动时,可以恢复进内存当中。
-
当通过API删除序列时,删除的记录存储在单独的tombstone文件中(而不是立即从块文件中删除数据)。
如下,是在进行数据收集后,在Prometheus中的data目录的数据
[root@prometheus prometheus]# tree data/
data/
├── 01DVRSS47GBRWVCH50GEXXHBQ5
│ ├── chunks
│ │ └── 000001
│ ├── index
│ ├── meta.json
│ └── tombstones
├── 01DVS0MVFHDN6ZS0R0Z3YR94VM
│ ├── chunks
│ │ └── 000001
│ ├── index
│ ├── meta.json
│ └── tombstones
├── 01DVS0MVMFEAAYQSNYHPV86E5T
│ ├── chunks
│ │ └── 000001
│ ├── index
│ ├── meta.json
│ └── tombstones
├── 01DVS7GJQT4GQBHBMX20V9JW4H
│ ├── chunks
│ │ └── 000001
│ ├── index
│ ├── meta.json
│ └── tombstones
├── lock
├── queries.active
└── wal
├── 00000012
├── 00000013
├── 00000014
├── 00000015
└── checkpoint.000011
└── 00000000
这里需要注意的是,本地存储的一个限制是它不是集群的或可复制的。因此,在磁盘或节点宕机时,它也不是任意可伸缩或持久的,对于磁盘可用性,建议使用RAID、备份快照、容量规划等,以提高持久性。应该通过适当的存储持久性和计划在本地存储中存储多年的数据。
2、prometheus集成的服务发现功能???
prometheus是通过Consul做的服务发现,和其他开源软件类似,prometheus也是通过配置文件来指定需要监控的项目和被监控的节点。如下面的配置模板:
[root@prometheus ~]# cat /usr/local/prometheus/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
external_labels:
monitor: 'codelab-monitor'
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
scrape_interval: 5s
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
3、Prometheus数据采集的方式???
prometheus客户端主要由2种数据采集的方式:
- pull:主动拉取形式
- push:被动推送的形式
pull:指的是客户端(被监控主机)先安装各类已有的exporters在系统上,exporters以守护进程的模式运行,并开始采集数据,exporters本身也是一个http_server,可以对http请求作出响应,并返回K/V数据,也就是metrics。prometheus通过用pull的方式(HTTP_GET)去访问每个节点上的exporter并采集回需要的数据。
push:指的是客户端(或服务端)安装官方的pushgateway插件,然后通过我们自行编写的各种脚本,将监控数据组织成K/V的形式(metrics形式)发送给pushgateway,而后pushgateway再推送给prometheus,这里需要注意的是pushgateway不一定要安装在被监控端,也可以安装在服务端,甚至是一台不相关的主机上,换句话来说,它只是一个中间转发的媒介。
4、Prometheus如何实现告警???
Prometheus有自带的altermanager模块,配合商业化的pageduty可以实现告警和邮件的发送功能,但是由于该功能模块在国内结合pageduty使用是一件很头疼的事,你懂的。所以一般是将Prometheus的数据集成在Grafana进行展示并进行告警配置。
5、什么是metrics???
一组K/V数据就是metrics,总体上来说metrics是对采集过来的数据的一种统称,并非一个具体的数值或指标。
6、metrics的类型???
-
Gauges:最简单的度量指标,只有一个简单的返回值,或者叫做瞬时状态,比如要采集硬盘容量或内存使用率,就可以用gauges的metrics格式来度量。因为硬盘和内存是随着时间推移不断地变化,没有规则的变化,当前是多少,采集回来的就是多少,既不能肯定是一直持续增长,也不能肯定是一直降低,是多少就是多少,这种就是Gauges使用类型的代表。
-
Counters:Counters就是计数器,从数据量0开始累积计算,理想状态下,只能是永远的增长,绝不会出现降低,比如用户的访问量采样数据,我们的产品被用户访问了一次就是1,过了10分钟后积累到100,过了1天就累积到20000。
-
Histograms:柱状图,用于观察结果采样,分组及统计,如:请求持续时间,响应大小。其主要用于表示一段时间内对数据的采样,并能够对其指定区间及总数进行统计。根据统计区间计算。
-
Summary:类似Histogram,用于表示一段时间内数据采样结果,其直接存储quantile数据,而不是根据统计区间计算出来的。不需要计算,直接存储结果。
7、什么是node-exporter???
Prometheus为了支持各种中间件以及第三方的监控提供了exporter,大家可以把它理解成监控适配器,将不同指标类型和格式的数据统一转化为Prometheus能够识别的指标类型。
譬如Node exporter主要通过读取Linux的/proc以及/sys目录下的系统文件获取操作系统运行状态,reids exporter通过Reids命令行获取指标,mysql exporter通过读取数据库监控表获取MySQL的性能数据。他们将这些异构的数据转化为标准的Prometheus格式,并提供HTTP查询接口。
8、什么是pushgateway???
通过node-exporter可以收集到各种服务器的相关性指标,但是并没有办法满足我们的定制化需求,比如需要监控某个进程数,某个进程打开的文件数,某个进程消耗的内存等等,这就需要一个定制化的监控项,类似于zabbix的自定义监控项是一个道理。