在工作当作, 经常会遇到需要了解一些新的领域或是知识。如何快速了解,并能够达到一定的深度的掌握,是我们今天这篇文章讨论的主题
学习方式的改变
当前互联网的发展,让资读的获取变得非常便捷。同时,也带来了资讯的泛滥。在没有电脑互联网之前,学习主要是通过书籍来获取知识。而书籍经过了专业知识领域的编辑审核,已经过滤了一些粗制乱造的文章,让我们能够节省一些辨识的工作。但是现在人们遇到问题,第一时间是去搜索引擎查找,快捷但是查到的内容通常泥沙俱下,不成系统。这也是为什么与很多人谈论一个话题时,知道有这个知识,但是稍微深入一点,就茫然不知了。而且,常常是之前遇到过的问题,过了一阵子又忘记了,因为这项知识并没有在你的体系结构上分枝结果,而是散乱在各处,当你检索时,犹如大海捞针,是以又得重新查找学习。这样就带来效率的低下。
了解知识概貌
一例胜千言。以下皆以Linux内核学习为例。
Linux内核发展到当前阶段,已是非常庞大。有些人学习内核,上来就下载一份代码开始阅读。拜托,这样读下去,你可能最后还是什么也没有学到,哪怕你是下载0.0.1内核完全注释版之类的去看也是一样。
凡事的发展都有一个过程。我们要学习Linux内核,首先要对Linux内核有一个大致的了解,知识它的分层结构,涉及到哪些模块,然后划定范围,深入去了解。
这里面了解知识的概貌是一个关键。通常的方式是去查找书籍,把目录过一遍,对所要了解的内容有个整体的概念。还是以Linux内核为例,相关的书籍非常多。我们找一些比较经典的书籍,如《Linux Kernel Development 3rd》
- 1 Introduction to the Linux Kernel
- 2 Getting Started with the Kernel
- 3 Process Management
- 4 Process Scheduling
- 5 System Calls
- 6 Kernel Data Structures
- 7 Interrupts and Interrupt Handlers
- 8 Bottom Halves and Deferring Work
- 9 An Introduction to Kernel Synchronization
- 10 Kernel Synchronization Methods
- 11 Timers and Time Management
- 12 Memory Management
- 13 The Virtual Filesystem
- 14 The Block I/O Layer
- 15 The Process Address Space
- 16 The Page Cache and Page Writeback
- 17 Devices and Modules
- 18 Debugging
- 19 Portability
- 20 Patches, Hacking, and the Community
从这个目录中我们可以看到有很多的内容,这就是书籍的好处。它已经帮你梳理出来一个知识的概貌了。
但如果我们要学习的内容并非有很多书籍帮我们梳理好这样的结构呢?或是有,但是你不知道有这样的书籍。继续Linux内核的例子,假设我们对内核及安全比较关心,但是对安全方面的知识一无所知。这本书涉及很少,我们要如何梳理出安全学习的知识点呢? 这时候你可以发挥搜索引擎的长处了。多查找一些文献,发表的文章,然后梳理出要了解的知识,把它像书籍一样列成目录结构。
以我目前在深入了解的领域嵌入式安全而言,之前对于这部分知之甚少。即不知道有什么这方面的书籍,也不知从哪里入手去学习。去google搜索嵌入式/安全字眼,会出来一大堆结果的。通过搜索,我们可以列出来如下一些关键词:
- 安全算法,如RSA,AES,SHA。
- 可信执行环境,如OPTEE
- 安全操作系统,如L4,
- 量子安全
- 数字签名
- 密钥分发
- 公钥安全体系
- HTTPS/SSL/TSL
- DRM/CA
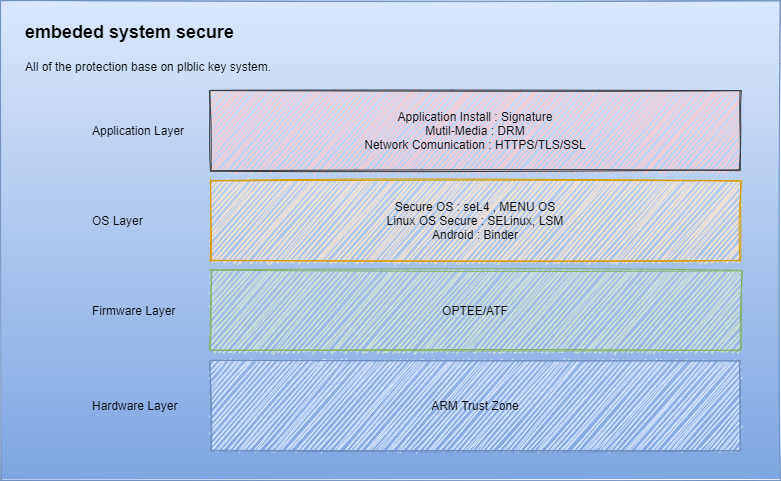
哇,好多内容,我知道有这么多内容需要了解,但是还是一脸茫然。要从哪里下手去看?通常找到几篇比较详细的文章,对整体有个认识。比如我就把这篇文章,《嵌入式安全综述》做了详细的阅读,知道了嵌入式安全从大的方面来讲,分为硬件安全和软件安全。对于硬件有哪些攻击手段,而通常这是我们所了解比较少的。以及嵌入式安全未来的研究趋势。这了这样大体的概念,我们可以继续发掘,如何保障硬件的安全,如何保障软件的安全。文章提到了安全可信的执行环境。这又是一个未了解过的概念,以此类推,我们以一篇综述性的文章将之前搜索过的知识梳理成结构化的目录,通常大家喜欢使用mindmap来整理,达到一目了然的效果。如最后我整理了如下图示:
拟定学习计划
有了上述的基本了解后,已经可以说完成一大半的任务了。毕竟从不了解到整理出一个概貌来,是极其不容易的事情。迈出这一步,后面就是具体的任务执行了。但是这一环节也是有技巧的,最重要的一点就是任务的分解,这些都是老生常谈。结合自己项目管理多年的经验,一个没有时间点或是优先级很低的任务,通常最后都是不会完全的。所以,你要给自己设定deadline,这个deadline不是公司的KPI,不是其它人的监督,完全是自律去实现。当然,如果所学的东西能够与工作相结合,那是最好不过了。
记住,任务的分解,一定要写出来,不能是心里朦胧的想法,似是而非的计划。这也是大多数人最后没有坚持下来的原因。唉,都是一些讲烂的东西,却又不得不断的强调。就是因为这些都不难做却很难坚持下来的。如果我们把所学的方法论之类的都能够贯彻执行,长期来看,你会有惊人的发现。
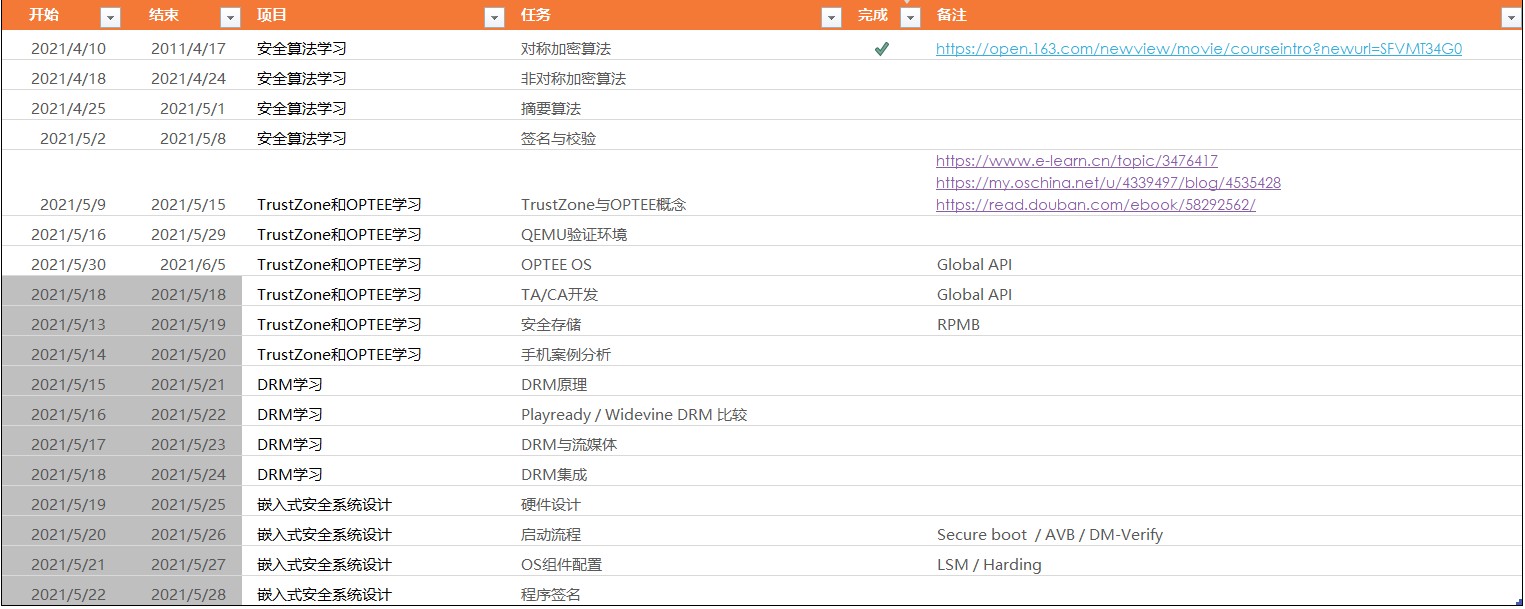
列一下我所制定的嵌入式安全学习的计划,供参考:
接收学习反馈
有一个模型讲到
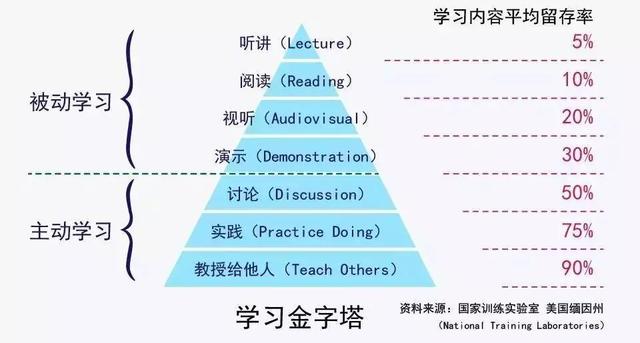
从上图可以看出来,单纯的看和听,能够留在下来的知识少之又少。要想提高知识的留在率,必须多参与讨论与好为人师。在这个过程中,知识可以得以加固,甚至有时候会修正自己多年的认知错误。
参与的方式多种多样,工作当中可以与同事讨论。如果所学与工作不太相关,可以去相关的论坛灌水。从回复别人的问题开始,到写传栏,录制视频课程,参与开源项目,甚至出版图书,都不是都可能。
在这些参与的过程中,你对知识的了解会从心中无剑,手中无剑,到心中有剑,手中有剑,到心中无剑,手中无剑境界之提升