数据类型
了解数据的数据类型可以通过以下语句来查看和使用帮助:
mysql> ? 查询关键词
# 如果,我们希望了解关于int的可以填值范围
mysql> ? int
使用数据类型的原则:够用就行,尽量使用取值范围小的,而不用大的,这样可以更多的节省存储空间
-
常用数据类型如下:
-
整数:bit[0-64],tinyint, smallint, int
-
小数:decimal
-
字符串:varchar,char
-
日期时间: date, time, datetime
-
枚举类型(enum) 多选一,例如性别字段 enum('男','女'),后面添加数据时,值得填写只能'男'和'女'这两项,其他值填写进来会报错。
-
-
特别说明的类型如下:
-
decimal表示浮点数,如decimal(5,2)表示共存5位数,小数占2位
-
char表示固定长度的字符串,如char(3),如果填充'ab'时会补一个空格为
'ab ' -
varchar表示可变长度的字符串,如varchar(3),填充'ab'时就会存储'ab'
-
字符串text表示存储大文本,当字符大于4000时推荐使用
-
对于图片、音频、视频等文件,不存储在数据库中,而是上传到某个文件管理服务器上,然后在表中存储这个文件的保存路径
-
-
更全的数据类型可以参考http://blog.csdn.net/anxpp/article/details/51284106
数值类型(常用)
| 类型 | 字节大小 | 有符号范围(Signed) | 无符号范围(Unsigned) |
|---|---|---|---|
| TINYINT | 1 | -128 ~ 127 | 0 ~ 255 |
| SMALLINT | 2 | -32768 ~ 32767 | 0 ~ 65535 |
| MEDIUMINT | 3 | -8388608 ~ 8388607 | 0 ~ 16777215 |
| INT/INTEGER | 4 | -2147483648 ~2147483647 | 0 ~ 4294967295 |
| BIGINT | 8 | -9223372036854775808 ~ 9223372036854775807 | 0 ~ 18446744073709551615 |
小数类型
| 类型 | 使用 | 描述 |
|---|---|---|
| decimal(M,D) | decimal(5,2),表示只能有5个数字, 其中最多设置2个数字在小数点后面 可以存储的数值:1000.5,123.56 不可以存储的数值:1000.51,100000, 1.345 | 十进制小数,用于表示商品的价格 |
开发中,一般QQ号或者手机号都是使用字符串来保存的
字符串
| 类型 | 字节大小 | 示例 |
|---|---|---|
| CHAR | 0-255 | 定长字符串,类型:char(3) 输入 'ab', 实际存储为'ab ', 输入'abcd' 实际存储为 'abc' |
| VARCHAR | 0-255 | 不定长字符串,类型:varchar(3) 输 'ab',实际存储为'ab', 输入'abcd',实际存储为'abc' |
| TEXT | 0-65535 | 大文本 |
在5.5版本的mysql以后,varchar类型可以存储的数据,可以达到65535个字符。
日期时间类型
| 类型 | 字节大小 | 示例 | 场景 |
|---|---|---|---|
| DATE | 4 | '2020-01-01' | 日期记录,会员过期时间,活动时间范围 |
| TIME | 3 | '12:29:59' | 餐厅的餐牌 |
| DATETIME | 8 | '2020-01-01 12:29:59' | 会员登录时间 |
| YEAR | 1 | '2017' | 电影的年份.... |
| TIMESTAMP | 4 | '1970-01-01 00:00:01' UTC ~ '2038-01-01 00:00:01' UTC | 基本用不上 |
DATETIME 和 TIMESTAMP,很多时候,我们会使用程序中的时间戳来代替,后面在数据库中保存时设置字段的类型是数值型,这样的话,可以节省存储空间,同时还可以提高数据的读取速度。
约束规则
-
主键primary key:在表中区分每一行数据的唯一性的标志服,数据在物理上存储的顺序
-
非空not null:此字段不允许填写空值,如果允许填写空值,则直接不填not null
-
惟一unique:此字段的值不允许重复
-
默认default:当不填写此值时会使用默认值,如果填写时以填写为准
-
外键 foreign key:用于连接两个表的关系,对关系字段进行约束,当为关系字段填写值时,会到关联的表中查询时是否此值是否存在,如果存在则填写成功,如果不存在则填写失败并抛出异常
-
说明:虽然外键约束可以保证数据的有效性,但是在进行数据的crud(create增加、update修改、delete删除、read查询)时,都会降低数据库的性能,所以不推荐使用,那么数据的有效性怎么保证呢?答:可以在python的逻辑层进行判断控制[用代码控制]
数据库设计
-
关系型数据库建议在E-R模型的基础上,我们需要根据产品经理的设计策划,抽取出来模型与关系,制定出表结构,这是项目开始的第一步
-
在开发中有很多设计数据库的软件,常用的如power designer,db desinger等,这些软件可以直观的看到实体及实体间的关系
-
设计数据库,可能是由专门的数据库设计人员完成,也可能是由开发组成员完成,一般是项目经理带领组员来完成
-
现阶段不需要独立完成数据库设计,但是要注意积累一些这方面的经验
实体
就是我们根据开发需求,要保存到数据库中作为一张表存在的事物。实体的名称最终会变成表名
实体会有属性,实体的属性就是描述这个事物的内容,实体的属性最终会在表中作为字段存在。
实体与实体之间会存在关系,这种关系一般就是根据三范式提取出来的主外键。
三范式
范式理论【在总结了经验以后,得出规范我们数据库设计的一些理论】
三范式:
1. 数据要保证不可分割.
2. 数据不能冗余(多余).
3. 数据不能重复.重复的数据,新建一张表存储.
-
经过研究和对使用中问题的总结,对于设计数据库提出了一些规范,这些规范被称为范式(Normal Form)
-
目前有迹可寻的共有8种范式,一般需要遵守3范式即可
-
◆ 第一范式(1NF):强调的是列的原子性,即列不能够再分成其他几列。
考虑这样一个表:【联系人】(姓名,性别,电话) 如果在实际场景中,一个联系人有家庭电话和公司电话,那么这种表结构设计就没有达到 1NF。要符合 1NF 我们只需把列(电话)拆分,即:【联系人】(姓名,性别,家庭电话,公司电话)。1NF 很好辨别,但是 2NF 和 3NF 就容易搞混淆。
-
◆ 第二范式(2NF):首先是 1NF,另外包含两部分内容,一是表必须有一个主键;二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。
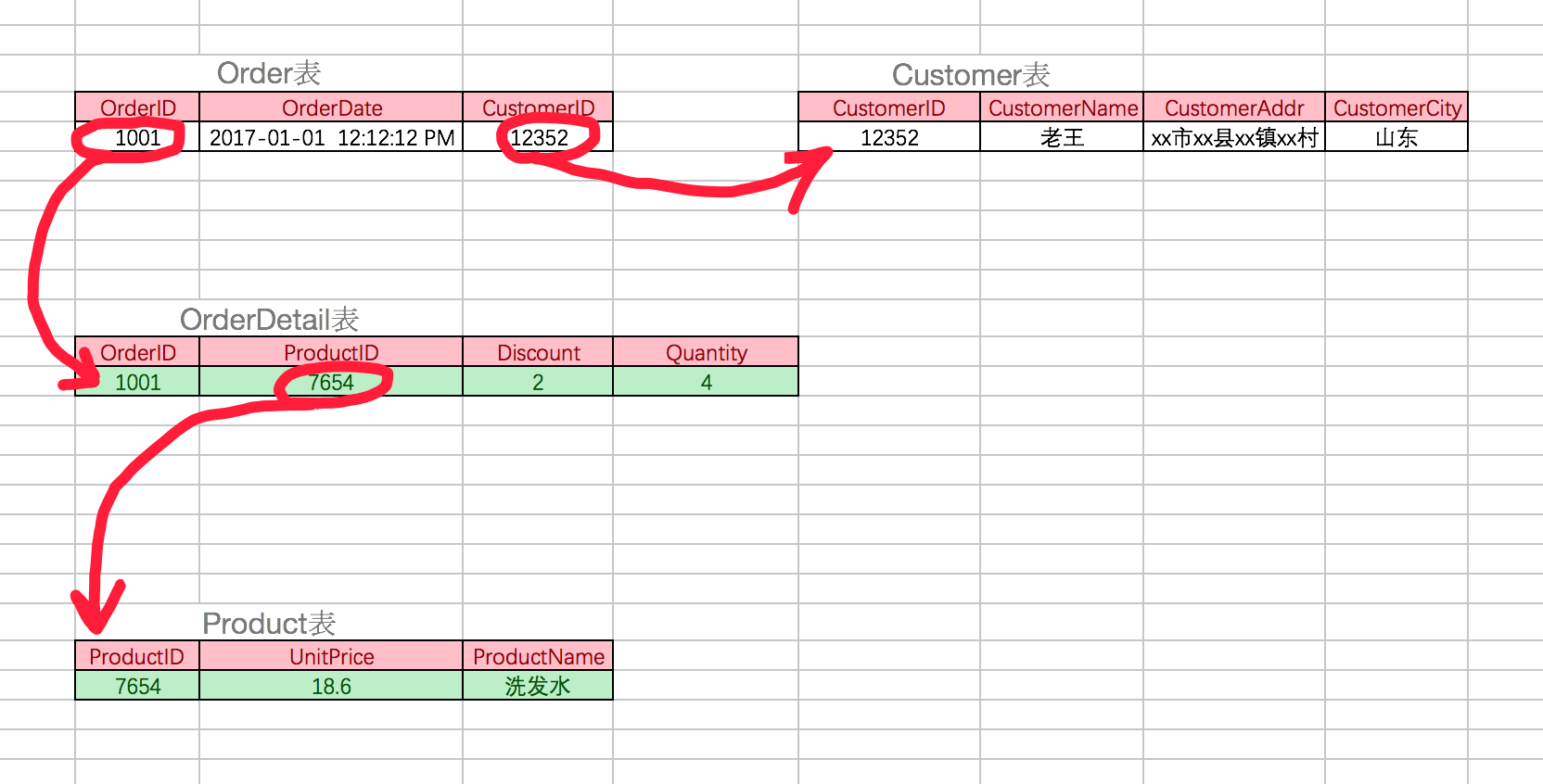
考虑一个订单明细表:【OrderDetail】(OrderID,ProductID,UnitPrice,Discount,Quantity,ProductName)。 因为我们知道在一个订单中可以订购多种产品,所以单单一个 OrderID 是不足以成为主键的,主键应该是(OrderID,ProductID)。显而易见 Discount(折扣),Quantity(数量)完全依赖(取决)于主键(OderID,ProductID),而 UnitPrice,ProductName 只依赖于 ProductID。所以 OrderDetail 表不符合 2NF。不符合 2NF 的设计容易产生冗余数据。
可以把【OrderDetail】表拆分为【OrderDetail】(OrderID,ProductID,Discount,Quantity)和【Product】(ProductID,UnitPrice,ProductName)来消除原订单表中UnitPrice,ProductName多次重复的情况。
-
◆ 第三范式(3NF):首先是 2NF,另外非主键列必须直接依赖于主键,不能存在传递依赖。即不能存在:非主键列 A 依赖于非主键列 B,非主键列 B 依赖于主键的情况。
考虑一个订单表【Order】(OrderID,OrderDate,CustomerID,CustomerName,CustomerAddr,CustomerCity)主键是(OrderID)。 其中 OrderDate,CustomerID,CustomerName,CustomerAddr,CustomerCity 等非主键列都完全依赖于主键(OrderID),所以符合 2NF。不过问题是 CustomerName,CustomerAddr,CustomerCity 直接依赖的是 CustomerID(非主键列),而不是直接依赖于主键,它是通过传递才依赖于主键,所以不符合 3NF。 通过拆分【Order】为【Order】(OrderID,OrderDate,CustomerID)和【Customer】(CustomerID,CustomerName,CustomerAddr,CustomerCity)从而达到 3NF。 *第二范式(2NF)和第三范式(3NF)的概念很容易混淆,区分它们的关键点在于,2NF:非主键列是否完全依赖于主键,还是依赖于主键的一部分;3NF:非主键列是直接依赖于主键,还是直接依赖于非主键列。
不遵循1NF

不遵循2NF

不遵循3NF

最终表
E-R模型
-
E表示entry,实体,设计实体就像定义一个类一样,指定从哪些方面描述对象,一个实体转换为数据库中的一个表
-
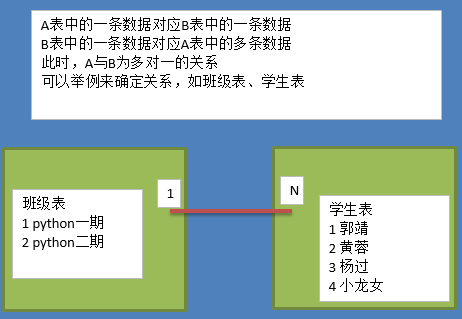
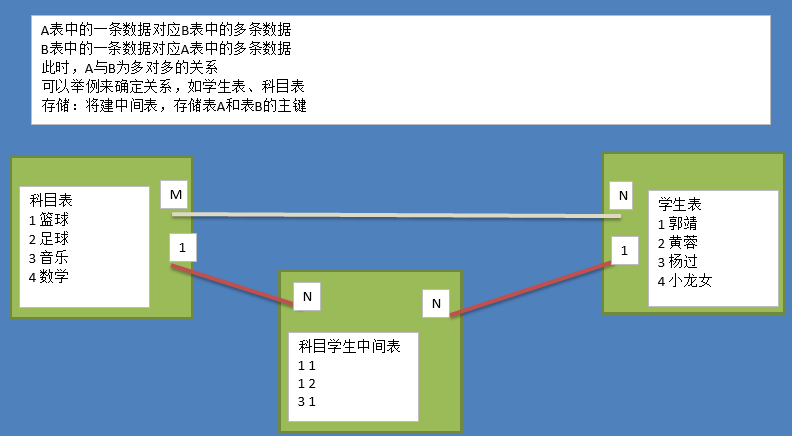
R表示relationship,关系,关系描述两个实体之间的对应规则,关系的类型包括包括一对一、一对多、多对多
-
关系也是一种数据,需要通过一个字段存储在表中
实体之间会因为引用相互引用字段而存在关系,这种关系一般有三种:
1-1
1-n
n-m[ 多对多一般表现为2个 1对多 ]
-
实体A对实体B为1对1,则在表A或表B中创建一个字段,存储另一个表的主键值

-
实体A对实体B为1对多:在表B中创建一个字段,存储表A的主键值
-
实体A对实体B为多对多:新建一张表C,这个表只有两个字段,一个用于存储A的主键值,一个用于存储B的主键值
-
想一想:举些例子,满足一对一、一对多、多对多的对应关系
逻辑删除
-
对于重要数据,并不希望物理删除,一旦删除,数据无法找回
-
删除方案:设置isDelete的列,类型为bit,表示逻辑删除,默认值为0
-
对于非重要数据,可以进行物理删除
-
数据的重要性,要根据实际开发决定
示例
-
设计两张表:班级表、学生表
-
班级表classes
-
id
-
name
-
isdelete
-
-
学生表students
-
id
-
name
-
birthday
-
gender
-
clsid
-
isdelete
-
扩展阅读
消除重复行
-
在select后面列前使用distinct可以消除重复的行
select distinct 列1,... from 表名;
例:
select distinct gender from students;
where条件的运算符进阶
空判断
-
注意:null与''是不同的
-
判空is null
例13:查询没有填写身高的学生
select * from students where height is null;
-
判非空is not null
例14:查询填写了身高的学生
select * from students where height is not null;
例15:查询填写了身高的男生
select * from students where height is not null and gender=1;
优先级
-
优先级由高到低的顺序为:小括号,not,比较运算符,逻辑运算符
-
and比or先运算,如果同时出现并希望先算or,需要结合()使用
###