现在的服务器大部分都是运行在Linux上面的,所以作为一个程序员有必要简单地了解一下系统是如何运行的。
对于内存部分需要知道:
- 地址映射
- 内存管理的方式
- 缺页异常
先来看一些基本的知识,在进程看来,内存分为内核态和用户态两部分,经典比例如下:

从用户态到内核态一般通过系统调用、中断来实现。用户态的内存被划分为不同的区域用于不同的目的:

当然内核态也不会无差别地使用,所以,其划分如下:

下面来仔细看这些内存是如何管理的。
在Linux内部的地址的映射过程为逻辑地址–>线性地址–>物理地址,物理地址最简单:地址总线中传输的数字信号,而线性地址和逻辑地址所表示的则是一种转换规则,线性地址规则如下:
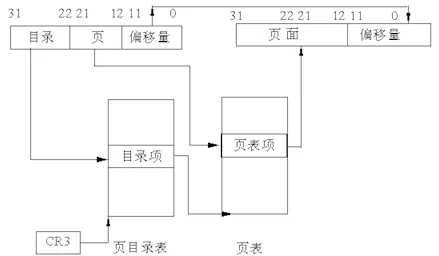
这部分由MMU完成,其中涉及到主要的寄存器有CR0、CR3。机器指令中出现的是逻辑地址,逻辑地址规则如下:
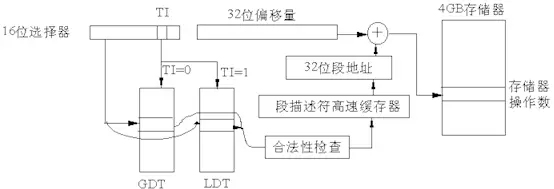
在Linux中的逻辑地址等于线性地址,也就是说Inter为了兼容把事情搞得很复杂,Linux简化顺便偷个懒。
在系统boot的时候会去探测内存的大小和情况,在建立复杂的结构之前,需要用一个简单的方式来管理这些内存,这就是bootmem,简单来说就是位图,不过其中也有一些优化的思路。
bootmem再怎么优化,效率都不高,在要分配内存的时候毕竟是要去遍历,buddy系统刚好能解决这个问题:在内部保存一些2的幂次大小的空闲内存片段,如果要分配3page,去4page的列表里面取一个,分配3个之后将剩下的1个放回去,内存释放的过程刚好是一个逆过程。用一个图来表示:
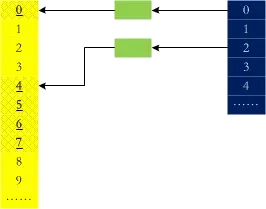
可以看到0、4、5、6、7都是正在使用的,那么,1、2被释放的时候,他们会合并吗?
static inline unsigned long
__find_buddy_index(unsigned long page_idx, unsigned int order)
{
return page_idx ^ (1 << order);// 更新最高位,0~1互换
}
从上面这段代码中可以看到,0、1是buddy,2、3是buddy,虽然1、2相邻,但他们不是。内存碎片是系统运行的大敌,伙伴系统机制可以在一定程度上防止碎片~~另外,我们可以通过cat /proc/buddyinfo获取到各order中的空闲的页面数。
伙伴系统每次分配内存都是以页(4KB)为单位的,但系统运行的时候使用的绝大部分的数据结构都是很小的,为一个小对象分配4KB显然是不划算了。Linux中使用slab来解决小对象的分配:
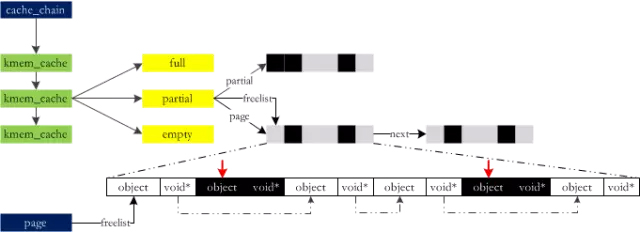
在运行时,slab向buddy“批发”一些内存,加工切块以后“散卖”出去。随着大规模多处理器系统和NUMA系统的广泛应用,slab终于暴露出不足:
- 复杂的队列管理
- 管理数据和队列存储开销较大
- 长时间运行partial队列可能会非常长
- 对NUMA支持非常复杂
为了解决这些高手们开发了slub:改造page结构来削减slab管理结构的开销、每个CPU都有一个本地活动的slab(kmem_cache_cpu)等。对于小型的嵌入式系统存在一个slab模拟层slob,在这种系统中它更有优势。
小内存的问题算是解决了,但还有一个大内存的问题:用伙伴系统分配10 x 4KB的数据时,会去16 x 4KB的空闲列表里面去找(这样得到的物理内存是连续的),但很有可能系统里面有内存,但是伙伴系统分配不出来,因为他们被分割成小的片段。那么,vmalloc就是要用这些碎片来拼凑出一个大内存,相当于收集一些“边角料”,组装成一个成品后“出售”:
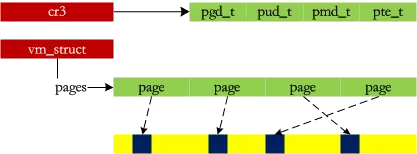
之前的内存都是直接映射的,第一次感觉到页式管理的存在:D 另外对于高端内存,提供了kmap方法为page分配一个线性地址。
进程由不同长度的段组成:代码段、动态库的代码、全局变量和动态产生数据的堆、栈等,在Linux中为每个进程管理了一套虚拟地址空间:
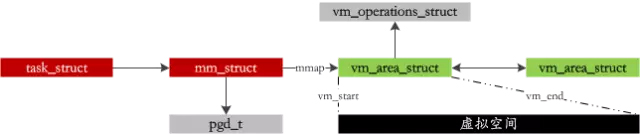
在我们写代码malloc完以后,并没有马上占用那么大的物理内存,而仅仅是维护上面的虚拟地址空间而已,只有在真正需要的时候才分配物理内存,这就是COW(COPY-ON-WRITE:写时复制)技术,而物理分配的过程就是最复杂的缺页异常处理环节了,下面来看!
在实际需要某个虚拟内存区域的数据之前,和物理内存之间的映射关系不会建立。如果进程访问的虚拟地址空间部分尚未与页帧关联,处理器自动引发一个缺页异常。在内核处理缺页异常时可以拿到的信息如下:
- cr2:访问到线性地址
- err_code:异常发生时由控制单元压入栈中,表示发生异常的原因
- regs:发生异常时寄存器的值
处理的流程如下:
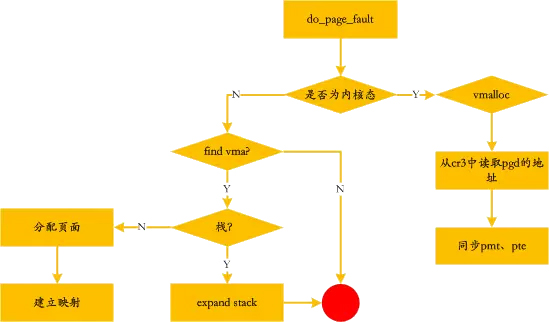
发生缺页异常的时候,可能因为不常使用而被swap到磁盘上了,swap相关的命令如下:
swapon 开启swap swapoff 关闭swap /proc/sys/vm/swapiness 分值越大越积极使用swap,可以修改/etc/sysctl.conf中添加vm.swappiness=xx[1-100]来修改
如果内存是mmap映射到内存中的,那么在读、写对应内存的时候也会产生缺页异常。