一、基础概念
- 字符与字节
字符是相对于人类而言的可识别的符号标识,是一种人类语言,如中文、英文、拉丁文甚至甲骨文、梵语等等。
字节是计算机内部识别可用的符号标识(0和1组成的二进制串,机器语言),属于机器语言。
人与计算机交互就需要在人类语言和机器语言之间来回转换,因此当把各种各样的字符存储或输入到计算机时,最终都必须以字节形式来表示;反之当计算机输出相应信息给人类用户时,最终也需要以人类可识别的字符形式来传递。
综上所述,字符与人类更为接近,而字节则与计算机(机器)更为接近。
上面的概念区分看起来非常清楚了,但实际应用尤其是在进行python开发又很容易犯迷糊,各种编码什么的一旦有些许模糊就会出现意想不到的结果。那么怎么区分字符与字节呢?
通用原则:
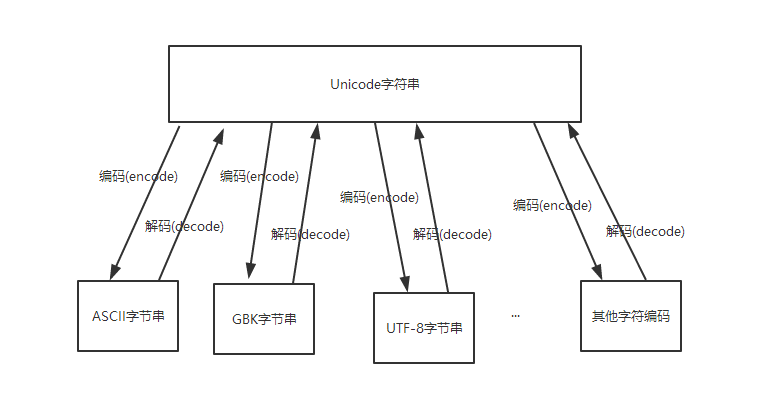
Unicode才是真正的字符串,而ASCII、UTF-8、GBK等编码格式表示的都是字节码。
原因是:字符串是由字符构成,字符在计算机硬件中通过二进制形式存储,这种二进制形式就是字节码(编码)。如果直接使用 “字符串↔️字符↔️二进制表示(编码)”,会增加不同类型编码之间转换的复杂性。所以引入了一个抽象层,“字符串↔️字符↔️与存储无关的表示↔️二进制表示(编码)” ,这样,可以用一种与存储无关的形式表示字符,不同的编码之间转换时可以先转换到这个抽象层,然后再转换为其他编码形式。在这里,unicode 就是 “与存储无关的表示”,是一种字符集,而ASCII、UTF-8、GBK等就是字符串对应的“二进制表示”。(以上文字绝大部分引自
链接:https://www.zhihu.com/question/23374078/answer/28710945,作者:flyer,原文博客成死链接了 https://link.zhihu.com/?target=http%3A//flyer103.diandian.com/post/2014-03-09/40061199665
因此,Unicode解决了人类识别计算机语言的兼容性和可用性问题,是一种字符串(只是一种字符集,而没有编码格式),而ASCII、UTF-8、GBK等是解决字符信息(Unicode)如何在计算机内部存储和表示的,是二进制形式的字节码。
关于这点,我们可以在Python的官方文档中经常可以看到这样的描述"Unicode string" , " translating a Unicode string into a sequence of bytes",我们写代码是写在文件中的,而字符是以字节形式保存在文件中的,因此当我们在文件中定义个字符串时被当做字节串也是可以理解的。但是,我们需要的是字符串,而不是字节串。(这段文字引用自http://www.cnblogs.com/yyds/p/6171340.html)Python2.0没有对此作严格区分,好在Python 3里已经开始严格区分了,并且默认的字符集就是Unicode。换句话讲,我们通过pycharm进行python 3.0开发时,编辑器里呈现的代码都是字符串,都是Unicode,无论我们在文件头声明使用什么文件格式(文件头的申明决定了源代码文件以什么样的二进制格式存储)。
- 编码
前面章节所述从人类可识别的字符到计算机可识别处理(存储传输)的字节的转换,就是一个编码的过程,即encode。而ASCII、UTF-8、GBK等,则决定了如何把字符转换为二进制字节码(转换规则)和转换后的二进制码的内容,所以它们是具体的编码格式(同一个符号可以有多种二进制字节码的表示)。借用网上某大神搬出来的通信理论强化一下,unicode是信源编码,对字符集数字化;utf8是信道编码,为更好的存储和传输。
- 解码
解码就是编码的逆过程,把计算机中存储运行的二进制字节码转换为字符的过程,即decode。
简单总结:
编码(encode):将Unicode字符串转换特定字符编码对应的字节串的过程和规则
解码(decode):将特定字符编码的字节串转换为对应的Unicode字符串的过程和规则
可见,无论是编码还是解码,都需要一个重要因素,就是特定的字符编码。因为一个字符用不同的字符编码进行编码后的字节值以及字节个数大部分情况下是不同的,反之亦然。
还是来一张图示吧:

- Python源代码的执行过程
首先明确一下基本概念,我们借助Pycharm来进行Python程序开发时,需要与编辑器和解释器打交道,Pycharm作为IDE就是编辑器,提高我们编写代码的效率;而我们安装的来自官方的Python程序(在Pycharm中运行时显示的python.exe)则是解释器。
结合上面章节对字符串和字节码相互转换的过程讲解,可以确定在开发过程中会在以下两个地方用到字符编码:
- 磁盘文件的存储写入和读取
这是对源代码文件编写后的保存和读取处理过程,由编辑器Pycharm自动完成。保存时需要encode,读取时则需要decode,这是由编辑器指定的工程或文件的字符编码决定的(Pycharm中还是推荐用默认的UTF-8)。 - 程序执行时的输入和输出
这是程序执行时的信息的表示过程,由解释器Python.exe完成。同理输入时需要encode(转换成机器码),输出时需要decode。请注意,这里的程序执行时的输出不仅包括程序运行后的各种print,更重要的是包括程序启动运行时,Python解释器将源代码文件中的字节码读取后转换为Unicode(decode)的过程,在此基础上Python解释器才会进行后续的处理(如print一个字符串或者变量)。这个过程需要我们指定源代码文件中保存字节时所使用的字符编码。
总结如下:
通过文件头指定字符编码:
1 # -*- coding:utf-8 -*-
Python源代码执行过程:

图片和上述思想主要摘自http://www.cnblogs.com/yyds/p/6171340.html
补充一下,Python解释器通过指定的字符编码把字节码转换为Unicode只是程序执行的刚刚开始,后续解释器还需要把Unicode字符串翻译为c代码(默认的cpython),然后转换成二进制流通过操作系统的相应接口调用CPU来执行二进制数据(机器只识别二进制数据),最后以Unicode方式返回我们需要的结果。
二、Unicode的由来与UTF-8的关系
理清了字符串和字节码各自的概念和转换过程, 现在不得不引入Unicode的由来以及它与UTF-8的关系了。
Unicode的由来
众所周知计算机由美国人发明, 由于英文字母相对固定简单, 美国大叔仅仅通过不到128位的ASCII就解决了字符编码问题. 随着计算机技术的不断发展和推广,其他国家也陆续开始使用计算机.遗憾的是对于非英语母语国家而言,由于母语相对于英语字母的复杂性和多样性,不到128位的ASCII没法扛起字符编码的重担.于是很多多家都结合自己的母语开发了适用于本国语言的字符编码体系,我们现在熟知的GBK,GB2312等国标都是那个时期的产物。
由于字符编码的各自为政,使得不同国家之间的交流变得很不顺畅,一不小心就踩到乱码了. 于是ISO集全球之力量,经过充分调研和科学设计,制定了可以包罗万象、能搞定世界上基本所有语言编码问题的Unicode,人称万国码。
请注意,Unicode本身并不是一种字符编码,而是一种字符集。如果直接使用 “字符串↔️字符↔️二进制表示(编码)”,会增加不同类型编码之间转换的复杂性。所以引入了一个抽象层,“字符串↔️字符↔️与存储无关的表示↔️二进制表示(编码)” ,这样,可以用一种与存储无关的形式表示字符,不同的编码之间转换时可以先转换到这个抽象层,然后再转换为其他编码形式。在这里,unicode 就是 “与存储无关的表示”,是一种字符集,而ASCII、UTF-8、GBK等就是字符串对应的“二进制表示”。
Unicode与UTF-8的关系
很多地方会很简单地讲UTF-8就是Unicode的压缩和优化版,经过前面章节的分析我们发现这种说法不严谨。还是先复习下通信理论,unicode是信源编码,对字符集数字化;utf8是信道编码,为更好的存储和传输。Unicode是一张字符与数字的映射,但是这里的数字被称为代码点(code point), 实际上就是十六进制的数字。Python官方文档中对Unicode字符串、字节串与编码之间的关系有这样一段描述:
Unicode字符串是一个代码点(code point)序列,代码点取值范围为0到0x10FFFF(对应的十进制为1114111)。这个代码点序列在存储(包括内存和物理磁盘)中需要被表示为一组字节(0到255之间的值),而将Unicode字符串转换为字节序列的规则称为编码。
简单来讲,Unicode字符集可以将字符用一定范围的数字来进行数字化,至于怎么把数字化表示为二进制,一千个人眼里有一千个哈姆雷特,这个过程就交给字符编码来显神通了,UTF-8刚好是其中一种且通用性很强的一种。因此可以讲utf8是对unicode字符集进行编码的一种编码方式,是对unicode字符集的二进制体现;Unicode是解决如何向人类展现可被识别的字符问题,而UTF-8是解决如何将人类可识别的字符转换为可被机器识别的字节码问题。
三、Python中的字符编码
- 默认字符编码
设想一个问题,如果我们在编写Python代码文件时没有指定编码格式,程序在执行时解释器又怎么把字节码转换成Unicode呢?这里由Python中默认的字符编码来决定。当我们的默认字符编码与编辑器里设置的字符编码不一致时,可通过文件头来进行字符编码格式的声明来解决,而如果此时没有文件头里面的声明,则会直接导致解码失败。Python2中解释器默认的字符编码是ASCII,Python3中解释器默认的字符编码是UTF-8。这就是Python2里默认情况下不支持中文字符的原因(没有通过文件头申明文件编码就调用默认的ASCII进行解码,显然ASCII码里没有中文对应的字符)。
Python解释器的默认编码可通过以下方式确认:
[root@node1 ~]# python Python 2.6.6 (r266:84292, Aug 18 2016, 15:13:37) [GCC 4.4.7 20120313 (Red Hat 4.4.7-17)] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> sys.getdefaultencoding() 'ascii' >>> C:UsersBeyondi>python Python 3.5.2 (v3.5.2:4def2a2901a5, Jun 25 2016, 22:18:55) [MSC v.1900 64 bit (AM D64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> sys.getdefaultencoding() 'utf-8' >>>
Python2下未声明字符编码情况下对中文字符的支持情况:
1 [root@node1 python]# cat test.py 2 #! /usr/bin/env python 3 s='你好,世界!' 4 print(s) 5 [root@node1 python]# python test.py 6 File "test.py", line 2 7 SyntaxError: Non-ASCII character 'xe4' in file test.py on line 2, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
上面的报错很明显了,第2行中需要打印的字符串ASCII不支持,并且也没有对字符编码进行显示声明。
现在在文件头增加字符编码的显示声明:
1 [root@node1 python]# cat test.py 2 # -*- coding:utf-8 -*- 3 #! /usr/bin/env python 4 s='你好,世界!' 5 print(s) 6 [root@node1 python]# python test.py 7 你好,世界!
增加正确的字符编码声明后,程序在执行时解释器会通过指定的字符编码UTF-8来对保存的字节码进行解码,然后进行后续的print处理,由于Linux环境下默认的字符编码也是UTF-8,所以中文字符就能正常显示了。如果把这段程序放到windows下运行(Python3解释器),情况又是怎样的呢?
通过记事本复制代码后保存为test.py,然后在cmd下运行:
1 D:pythonS13Day3>type test.py 2 # -*- coding:utf-8 -*- 3 #! /usr/bin/env python 4 s='你好,世界!' 5 print(s) 6 D:pythonS13Day3>python test.py 7 File "test.py", line 3 8 SyntaxError: (unicode error) 'utf-8' codec can't decode byte 0xc4 in position 0: 9 invalid continuation byte
从输出结果来看程序还是报错了,何故?我们不是在文件头中声明了字符编码了吗?这里的问题在于我们通过记事本保存代码文件时默认的字符编码是windows中文版下的GBK,而程序执行时Python解释器会用我们在文件头中声明的UTF-8去解码成Unicode来进行后续的处理,用UTF-8去解码GBK编码,当然不能解了。所以要注意的是,需要保持解释器的字符编码与编辑器的字符编码一致。所以强烈建议在Pycharm中把默认的字符编码设置为UTF-8,免得给自己挖坑。
实际测试表明Pycharm是一个比较智能的IDE,如果通过页面右下角的按钮改变了文件编码,运行程序时文件头部的编码声明会自动调整以保持两者一致,此时你会发现右下角的改变文件编码按钮会有如下提示:
此时我们需要把声明的字符编码改成与编辑器一致的字符编码GBK即可(或者修改编辑器保存文件时的字符编码也OK,总之要保持一致):
1 D:pythonS13Day3>type test.py 2 # -*- coding:GBK -*- 3 #! /usr/bin/env python 4 s='你好,世界!' 5 print(s) 6 D:pythonS13Day3> 7 D:pythonS13Day3> 8 D:pythonS13Day3>python test.py 9 你好,世界! 10 11 D:pythonS13Day3>
补充一点,这里如果把需要打印输出的字符串内容改为英文字符,那么不修改文件头部的字符编码也可以正常输出:
1 D:pythonS13Day3>type test.py 2 __author__ = 'Maxwell' 3 #!/usr/bin/env python 4 # -*- coding: utf-8 -*- 5 s = 'Hello, world!' 6 print(s) 7 D:pythonS13Day3> 8 D:pythonS13Day3> 9 D:pythonS13Day3>python test.py 10 Hello, world!
这是因为英文字符在UTF-8和GBK下的二进制码是相同的。
1 __author__ = 'Maxwell' 2 #!/usr/bin/env python 3 # -*- coding: utf-8 -*- 4 s = 'Hello, world!' 5 print(s.encode('utf-8')) 6 print(s.encode('GBK')) 7 print(type(s.encode('utf-8'))) 8 print(type(s.encode('GBK'))) 9 10 11 输出: 12 b'Hello, world!' 13 b'Hello, world!' 14 <class 'bytes'> #注意encode后类型变为二进制了 15 <class 'bytes'>
所以,除非特别需要,强烈建议在代码一贯保持用英文字符。
- 将IDE的字符编码设置为UTF-8
- 习惯性地在代码文件头部分明确声明使用UTF-8字符编码 -*- coding:utf-8 –*-
这样可以保持程序对Python2解释器的良好兼容性。
综上所述,强烈建议遵循以下原则进行Python开发:
- Python 2 VS Python 3
从事Python开发一定要了解Python2与Python3的差异性,在此从字符编码相关的角度略微展开。
首先,Python2的默认编码是ASCII,而Python3的默认编码是UTF-8。
其次,Python2和Python3在字符串与字节码的处理上截然不同:
Python2中字符串有str和Unicode两种类型,但str表示的是经过各种字符编码编码后的二进制字节码,Unicode则是没有编码的标准文本。Unicode经过编码转换为为str,str经过解码后还原成Unicode。这里把字符串和字节码混在一起了。
Python3中str类型即为Unicode字符串,单独设立的bytes表示经过编码处理后的二进制字节码。因此Python3中对字符串和字节码作了严格的区分。str经过编码后转换为bytes类型的字节码,反过来bytes类型的字节码经过解码则可以还原为Unicode字符串。
还是来一张形象的图示吧:")
通过上图可看出,Python3中的str类似于Python2中的Unicode,而Python3中的bytes则类似于Python2中的str,但请注意仅仅是类似而不是等同于,因为还存在其他层面的区别:
(1)Python2中可直接查看str的Unicode字节序列
1 [root@node1 python]# python 2 Python 2.6.6 (r266:84292, Aug 18 2016, 15:13:37) 3 [GCC 4.4.7 20120313 (Red Hat 4.4.7-17)] on linux2 4 Type "help", "copyright", "credits" or "license" for more information. 5 >>> s=u'你好,世界!' 6 >>> s 7 u'u4f60u597duff0cu4e16u754c!'
(2)Python3中open函数加上了encoding参数,默认传递的字符编码是UTF-8,对文件进行read或write时,只接受包含Unicode的字符串。对于二进制文件,则需要以rb,wb或ab模式打开。
借用大神的一张形象展示一下(引用自 http://www.cnblogs.com/yuanchenqi/articles/5956943.html):
")

四、实战字符编码转码
经过前面章节的理论铺垫,是时候来展开字符编码与转码的重点了。
先从Python3开始:
前面章节阐述过,Unicode是一个抽象层,与存储无关的表示,同时又包罗万象,可以很方便地与其他字符编码进行转换,因此它可以作为中间代理人来进行不同编码之间的转换,以简化不同编码之间直接转换的复杂度。实际应用中正是这样:
通过例子来实战一下:
1 __author__ = 'Maxwell'
2 #!/usr/bin/env python
3 # -*- coding: utf-8 -*-
4 s = '你好,世界!'
5 print(s.encode('utf-8'))
6 print(s.encode('GBK'))
7 s_to_gbk = s.encode('GBK')
8 print(s_to_gbk.decode('GBK').encode('utf-8'))
9 print(s_to_gbk.decode('GBK').encode('utf-8').decode('utf-8')) #连续转码处理,GBK解码后以utf-8方式编码,最后解码还原成Unicode
10
11 输出:
12 b'xe4xbdxa0xe5xa5xbdxefxbcx8cxe4xb8x96xe7x95x8cxefxbcx81'
13 b'xc4xe3xbaxc3xa3xacxcaxc0xbdxe7xa3xa1'
14 b'xe4xbdxa0xe5xa5xbdxefxbcx8cxe4xb8x96xe7x95x8cxefxbcx81'
15 你好,世界!
先从Python3开始:
前面章节阐述过,Unicode是一个抽象层,与存储无关的表示,同时又包罗万象,可以很方便地与其他字符编码进行转换,因此它可以作为中间代理人来进行不同编码之间的转换,以简化不同编码之间直接转换的复杂度。实际应用中正是这样:
通过例子来实战一下:
1 __author__ = 'Maxwell' 2 #!/usr/bin/env python 3 # -*- coding: utf-8 -*- 4 s = '你好,世界!' 5 print(s.encode('utf-8')) 6 print(s.encode('GBK')) 7 s_to_gbk = s.encode('GBK') 8 print(s_to_gbk.decode('GBK').encode('utf-8')) 9 print(s_to_gbk.decode('GBK').encode('utf-8').decode('utf-8')) #连续转码处理,GBK解码后以utf-8方式编码,最后解码还原成Unicode 10 11 输出: 12 b'xe4xbdxa0xe5xa5xbdxefxbcx8cxe4xb8x96xe7x95x8cxefxbcx81' 13 b'xc4xe3xbaxc3xa3xacxcaxc0xbdxe7xa3xa1' 14 b'xe4xbdxa0xe5xa5xbdxefxbcx8cxe4xb8x96xe7x95x8cxefxbcx81' 15 你好,世界!
注意:
1. 以上程序输出表明,Unicode字符串经过编码处理后立即变成bytes类型(输出结果以b开头,当然也可以通过type函数来验证确定),需要打印时必须解码转换为Unicode字符串;
2. 文件头部的显式字符编码声明仅仅决定了Python解释器在执行程序的开始阶段,会通过什么字符编码去打开解码保存的二进制字节码代码文件,它不改变程序代码中定义的str类型是Unicode字符串这一事实(此时定义的字符串s仍然可以被各种encode)。Python3中内嵌原生地支持Unicode,定义的str类型默认就是Unicode字符串。
Python2版本下的情况:
1 [root@node1 python]# python 2 Python 2.6.6 (r266:84292, Aug 18 2016, 15:13:37) 3 [GCC 4.4.7 20120313 (Red Hat 4.4.7-17)] on linux2 4 Type "help", "copyright", "credits" or "license" for more information. 5 >>> s='你好,世界!' 6 >>> s_to_unicode=s.decode('utf-8') 7 >>> s_to_gbk=s_to_unicode.encode('GBK') 8 >>> print(type(s)) 9 <type 'str'> 10 >>> print(type(s_to_unicode)) 11 <type 'unicode'> 12 >>> s 13 'xe4xbdxa0xe5xa5xbdxefxbcx8cxe4xb8x96xe7x95x8c!' 14 >>> s_to_gbk 15 'xc4xe3xbaxc3xa3xacxcaxc0xbdxe7!' 16 >>> print(s) 17 你好,世界! 18 >>> print(s_to_gbk.decode('GBK')) 19 你好,世界! 20 >>> print(type(s_to_gbk.decode('GBK'))) # decode之后类型变为Unicode 21 <type 'unicode'>
Python2下的字符串是二进制字节码形式,可以通过str= u’Hello,world!’直接转换为Unicode。打印时可以对str本身打印,也可以对其转换后的Unicode打印,因为Python2下没有对字节和字符作严格区分。
1 >>> s='你好,世界!' 2 >>> print(s) 3 你好,世界! 4 >>> h=u'你好,世界!' 5 >>> print(h) 6 你好,世界! 7 >>> h 8 u'u4f60u597duff0cu4e16u754c!' 9 >>> s 10 'xe4xbdxa0xe5xa5xbdxefxbcx8cxe4xb8x96xe7x95x8c!' 11 >>> print(s.decode('utf-8')) 12 你好,世界!