PostgreSQL group by 后取最新的一条
参考:https://www.cnblogs.com/funnyzpc/p/9311281.html,https://www.cnblogs.com/aeolian/p/9359898.html
需求
- 针对 registration_id 和 district 分组(登记编号、区)
- 并且根据时间倒序取最后一条
数据
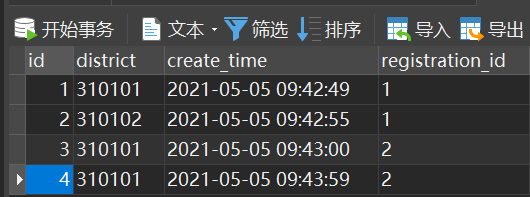
请注意,id=1,2的两条数据经过双重分组查询后的结果应该是两条
CREATE TABLE "public"."application" (
"id" int8 NOT NULL,
"district" varchar(255) COLLATE "pg_catalog"."default",
"registration_id" varchar(255) COLLATE "pg_catalog"."default",
"create_time" timestamp(6),
CONSTRAINT "application_pkey" PRIMARY KEY ("id")
);
ALTER TABLE "public"."application"
OWNER TO "postgres";
COMMENT ON COLUMN "public"."application"."id" IS '主键';
COMMENT ON COLUMN "public"."application"."district" IS '报名区';
COMMENT ON COLUMN "public"."application"."registration_id" IS '登记编号';
COMMENT ON COLUMN "public"."application"."create_time" IS '创建时间';
INSERT INTO "public"."application"("id", "district", "registration_id", "create_time") VALUES (1, '310101', '1', '2021-05-05 09:42:49');
INSERT INTO "public"."application"("id", "district", "registration_id", "create_time") VALUES (2, '310102', '1', '2021-05-05 09:42:55');
INSERT INTO "public"."application"("id", "district", "registration_id", "create_time") VALUES (3, '310101', '2', '2021-05-05 09:43:00');
INSERT INTO "public"."application"("id", "district", "registration_id", "create_time") VALUES (4, '310101', '2', '2021-05-05 09:43:59');
实现1
按照惯性思维:我开始想到了 having create_time = max(cerate_time) 哈哈,这就笨比了。因为 having 是在 group by 之后执行的。
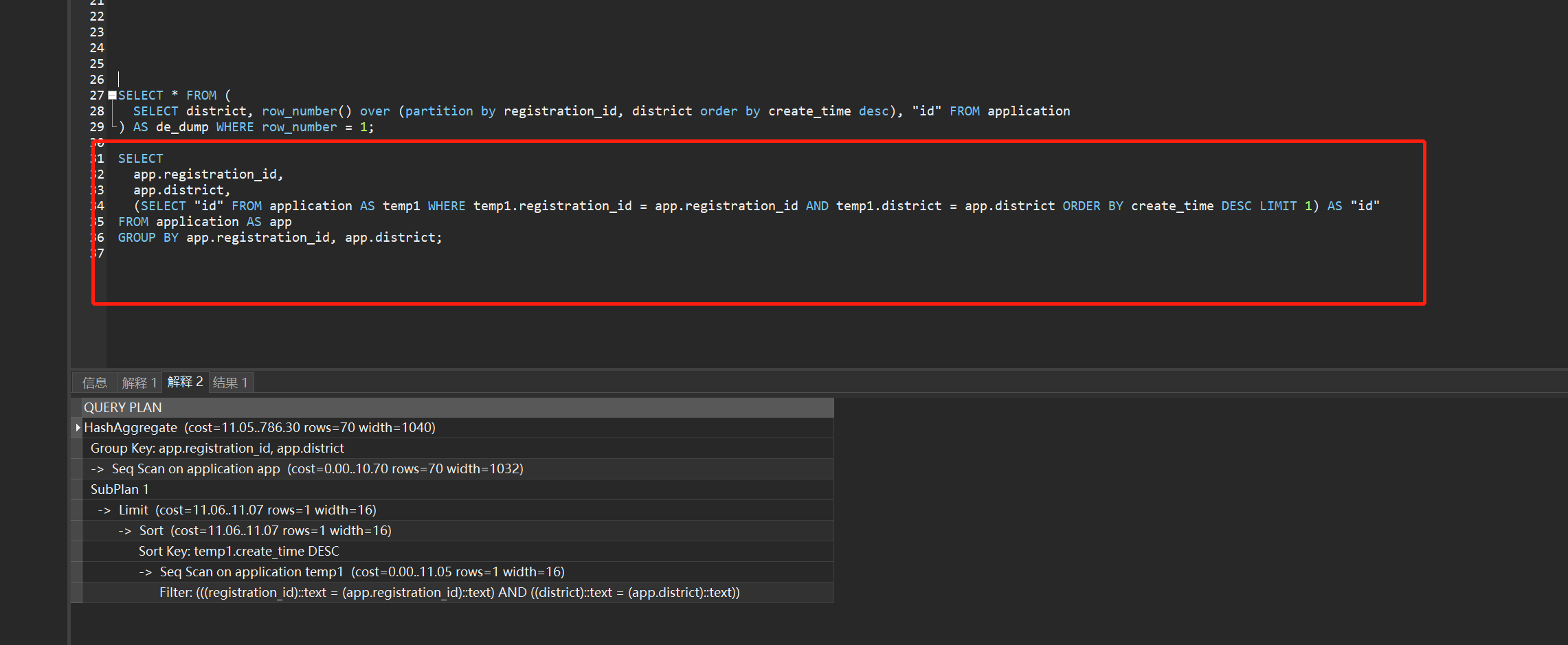
SELECT
app.registration_id,
app.district,
(SELECT "id" FROM application AS temp1 WHERE temp1.registration_id = app.registration_id AND temp1.district = app.district ORDER BY create_time DESC LIMIT 1) AS "id"
FROM application AS app
GROUP BY app.registration_id, app.district
查询结果:正确
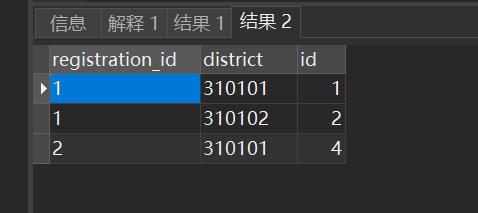
虽然结果正确,但是生产环境几十万数据量的时候并且在除了主键就没索引的情况下会慢到怀疑人生
实现2
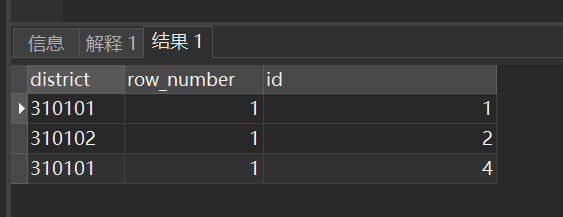
SELECT * FROM (
SELECT district, row_number() over (partition by registration_id, district order by create_time desc), "id" FROM application
) AS de_dump WHERE row_number = 1
查询结果:正确
对比
需求
- 针对 registration_id 和 district 分组(登记编号、区)
- 并且根据时间倒序取最后一条
个人理解下来 partition by 和 group by 比
- 相同点:分组并且是多字段
- 不同点1:partition by 可以更加方便的对组内数据排序以及根据需要取出需要的数据,group by 比较愣头青只能通过聚合函数搞到需要的数据。
- 不同点2:同时group by查询的时候不能出现非聚合字段,这导致想获取其他列只能通过子查询,这就很笨比
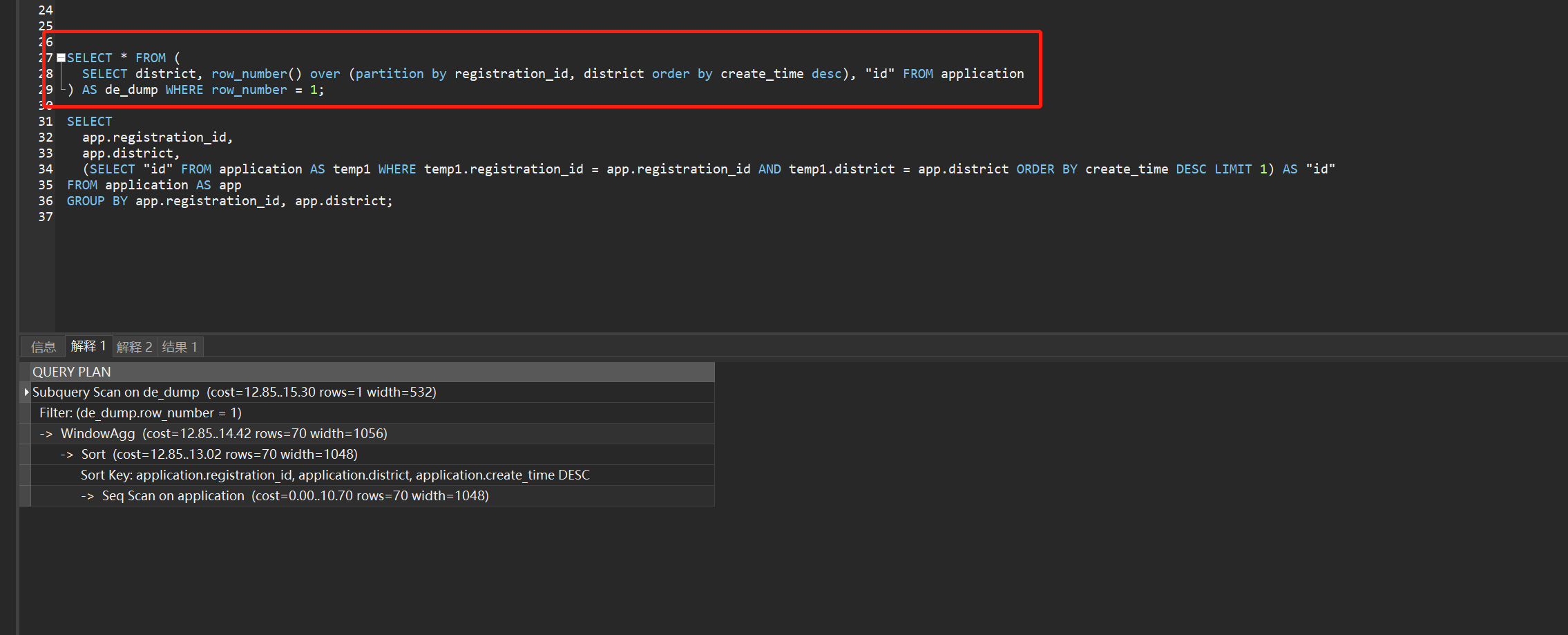
- 针对我这个需求的优劣选择 明显要选择 partition by ,因为我用 QUERY PLAN 跑了下两者光是步骤就有很大的数量差距
QUERY PLAN: 个人数据库水平有限,可这看执行条数以及个人实践采用窗口函数的sql是明显优于传统group by的
小结
虽然个人摸索出 实现2 要优于 实现1,但是实现2为了去重也不可避免的使用了子查询然后通过查询 row_numer = 1 来实现去重。
如果有更好的方法欢迎在评论区留言。