1、最简单的consumer使用(工作中不推荐使用)
每次启动,都会重新收到一次。解决方法,业务处理成功后收到提交。
private static void helloWorld(){
Properties prop = new Properties();
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"118.xx.xx.101:9092");
prop.put("group.id","test");
prop.put("enable.auto.commit","true");
prop.put("auto.commit.interval.ms","1000");
prop.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
prop.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(prop);
// 消费订阅哪个Topic或者几个Topic
consumer.subscribe(Arrays.asList(TOPIC_NAME));
while (true){
ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(1000));
for( ConsumerRecord<String,String> record: records){
System.out.printf("partition - %d, offset - %d, key - %s, value - %s%n",
record.partition(),record.offset(), record.key(), record.value());
}
}
}
2、Consumer手动提交。
/**
* 手动提交offset
*/
private static void commitedOffset(){
Properties prop = new Properties();
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"118.xx.xx.101:9092");
prop.put("group.id","test");
prop.put("enable.auto.commit","false");
prop.put("auto.commit.interval.ms","1000");
prop.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
prop.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(prop);
// 消费订阅哪个Topic或者几个Topic
consumer.subscribe(Arrays.asList(TOPIC_NAME));
while (true){
ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(1000));
for( ConsumerRecord<String,String> record: records){
System.out.printf("partition - %d, offset - %d, key - %s, value - %s%n",
record.partition(),record.offset(), record.key(), record.value());
//把数据保存到数据库。
if(mockInsertDb()){
}
}
//如果手动通知offset提交
// consumer.commitAsync();
}
}
private static boolean mockInsertDb(){
return true;
}
这样就达到了,成功了就消费成功。失败了还能再次消费。
三、consumer配置文件
Properties prop = new Properties();
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"118.xx.xx.101:9092");
// 对consumer进行分组
prop.put("group.id","test");
prop.put("enable.auto.commit","true");
prop.put("auto.commit.interval.ms","1000");
prop.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
prop.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
1、consumer分组注意事项
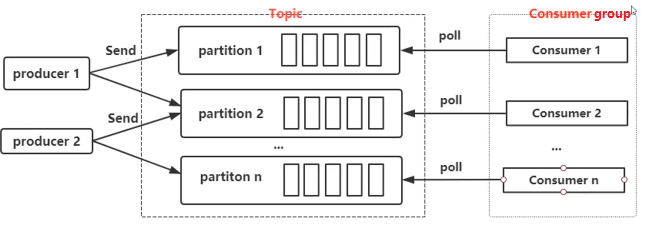
1) 单个分区的消息只能由ConsumerGroup中的某个Conumer消费。
consumer group中的consumer与partition是1:1或者 n:1的关系
以下1:1关系
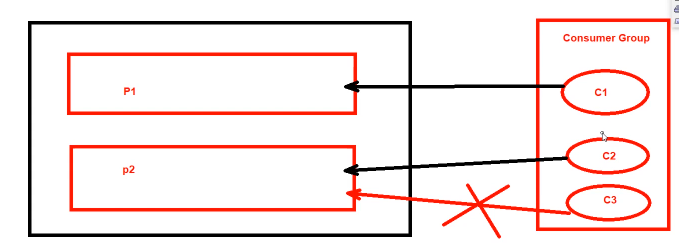
以下红色的连线时禁止的。
2) Consumer从Partition中消费消息时顺序,默认从头开始消费。
3) 单个ConsumerGroup会消费所有Partition中的消息。如只有一个consumer,可以消费所有有Partition中的消息。
四、Consumer单Partition提交offset
poll后,在多线程的情况下,对每个partition进行处理。有的partition处理成功,有的partition处理失败,则不需要提交。假设三个partition,两个成功,一个失败,下一次就不需要重新检查这三个partition重新消费,针对失败的partition重新消费一次就好了。
/**
* 手动提交offset,并且手动控制partition
*/
private static void commitedOffsetWithPartition(){
Properties prop = new Properties();
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"118.xx.xx.101:9092");
prop.put("group.id","test");
prop.put("enable.auto.commit","false");
prop.put("auto.commit.interval.ms","1000");
prop.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
prop.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(prop);
// 消费订阅哪个Topic或者几个Topic
consumer.subscribe(Arrays.asList(TOPIC_NAME));
while (true){
ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(10000));
//每个partition单独获取
for(TopicPartition partition : records.partitions()){
List<ConsumerRecord<String,String>> pRecord = records.records(partition);
for( ConsumerRecord<String,String> record: pRecord){
System.out.printf("partition - %d, offset - %d, key - %s, value - %s%n",
record.partition(),record.offset(), record.key(), record.value());
}
long lastOffset = pRecord.get(pRecord.size() - 1).offset();
//单个partition中的offset,并且进行提交
Map<TopicPartition, OffsetAndMetadata> offset = new HashMap<>();
offset.put(partition,new OffsetAndMetadata(lastOffset + 1));
//提交offset
consumer.commitSync(offset);
System.out.println("===============partition =" + partition + " end ==============");
}
}
}
这里的弊端时拉去后进行处理,只是减少了处理逻辑。
五、 手动订阅某个或某些分区,并提交offset
/**
* 手动提交offset,并且手动控制partition.
* 手动订阅某个或某些分区,并提交offset
*/
private static void commitedOffsetWithPartition(){
Properties prop = new Properties();
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"118.xx.xx.101:9092");
prop.put("group.id","test");
prop.put("enable.auto.commit","false");
prop.put("auto.commit.interval.ms","1000");
prop.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
prop.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(prop);
// 消费订阅哪个Topic或者几个Topic
consumer.subscribe(Arrays.asList(TOPIC_NAME));
while (true){
ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(10000));
//每个partition单独获取
for(TopicPartition partition : records.partitions()){
List<ConsumerRecord<String,String>> pRecord = records.records(partition);
for( ConsumerRecord<String,String> record: pRecord){
System.out.printf("partition - %d, offset - %d, key - %s, value - %s%n",
record.partition(),record.offset(), record.key(), record.value());
}
long lastOffset = pRecord.get(pRecord.size() - 1).offset();
//单个partition中的offset,并且进行提交
Map<TopicPartition, OffsetAndMetadata> offset = new HashMap<>();
offset.put(partition,new OffsetAndMetadata(lastOffset + 1));
//提交offset
consumer.commitSync(offset);
System.out.println("===============partition =" + partition + " end ==============");
}
}
}
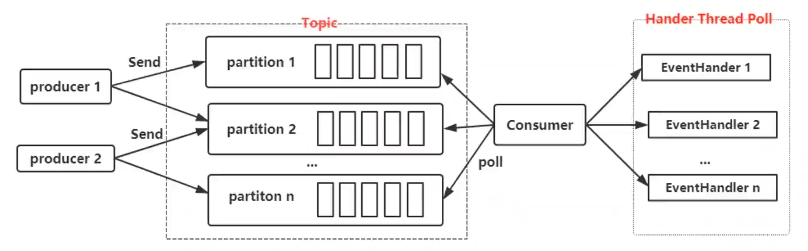
六、Consumer多线程并发处理
方式1:每一个线程单独创建一个KafkaConsumer,用于保证线程安全
代码如下:
public class ConsumerThreadSample {
private final static String TOPIC_NAME="test5";
/*
这种类型是经典模式,每一个线程单独创建一个KafkaConsumer,用于保证线程安全
*/
public static void main(String[] args) throws InterruptedException {
KafkaConsumerRunner r1 = new KafkaConsumerRunner();
Thread t1 = new Thread(r1);
t1.start();
Thread.sleep(15000);
r1.shutdown();
}
public static class KafkaConsumerRunner implements Runnable{
private final AtomicBoolean closed = new AtomicBoolean(false);
private final KafkaConsumer consumer;
public KafkaConsumerRunner() {
Properties props = new Properties();
props.put("bootstrap.servers", "118.xx.xx.101:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "false");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<>(props);
TopicPartition p0 = new TopicPartition(TOPIC_NAME, 0);
TopicPartition p1 = new TopicPartition(TOPIC_NAME, 1);
consumer.assign(Arrays.asList(p0,p1));
}
public void run() {
try {
while(!closed.get()) {
//处理消息
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(10000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> pRecord = records.records(partition);
// 处理每个分区的消息
for (ConsumerRecord<String, String> record : pRecord) {
System.out.printf("patition = %d , offset = %d, key = %s, value = %s%n",
record.partition(),record.offset(), record.key(), record.value());
}
// 返回去告诉kafka新的offset
long lastOffset = pRecord.get(pRecord.size() - 1).offset();
// 注意加1
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
}catch(WakeupException e) {
if(!closed.get()) {
throw e;
}
}finally {
consumer.close();
}
}
public void shutdown() {
closed.set(true);
consumer.wakeup();
}
}
}
方式2:使用线程池
无法记录offset,不能再次消费失败的。
代码如下:
public class ConsumerRecordThreadSample {
private final static String TOPIC_NAME = "test5";
public static void main(String[] args) throws InterruptedException {
String brokerList = "118.xx.xx.101:9092";
String groupId = "test";
int workerNum = 5;
CunsumerExecutor consumers = new CunsumerExecutor(brokerList, groupId, TOPIC_NAME);
consumers.execute(workerNum);
Thread.sleep(1000000);
consumers.shutdown();
}
// Consumer处理
public static class CunsumerExecutor{
private final KafkaConsumer<String, String> consumer;
private ExecutorService executors;
public CunsumerExecutor(String brokerList, String groupId, String topic) {
Properties props = new Properties();
props.put("bootstrap.servers", brokerList);
props.put("group.id", groupId);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
}
public void execute(int workerNum) {
executors = new ThreadPoolExecutor(workerNum, workerNum, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(1000), new ThreadPoolExecutor.CallerRunsPolicy());
while (true) {
ConsumerRecords<String, String> records = consumer.poll(200);
for (final ConsumerRecord record : records) {
executors.submit(new ConsumerRecordWorker(record));
}
}
}
public void shutdown() {
if (consumer != null) {
consumer.close();
}
if (executors != null) {
executors.shutdown();
}
try {
if (!executors.awaitTermination(10, TimeUnit.SECONDS)) {
System.out.println("Timeout.... Ignore for this case");
}
} catch (InterruptedException ignored) {
System.out.println("Other thread interrupted this shutdown, ignore for this case.");
Thread.currentThread().interrupt();
}
}
}
// 记录处理
public static class ConsumerRecordWorker implements Runnable {
private ConsumerRecord<String, String> record;
public ConsumerRecordWorker(ConsumerRecord record) {
this.record = record;
}
@Override
public void run() {
// 假如说数据入库操作
System.out.println("Thread - "+ Thread.currentThread().getName());
System.err.printf("patition = %d , offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());
}
}
}
七、手动控制起始位置
//动指定offset的起始位置
consumer.seek(p0, 700);
/**
* 手动指定offset的起始位置,以及手动提交offset
*/
private static void controllOffset(){
Properties prop = new Properties();
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"118.xx.xx.101:9092");
prop.put("group.id","test");
prop.put("enable.auto.commit","false");
prop.put("auto.commit.interval.ms","1000");
prop.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
prop.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(prop);
// 创建了两个partition,分别为test5-0,test5-1, test5为topic name
TopicPartition p0 = new TopicPartition(TOPIC_NAME, 0);
// 消费订阅哪个Topic或者几个Topic
//consumer.subscribe(Arrays.asList(TOPIC_NAME));
//消费订阅某个topic的某个分区
consumer.assign(Arrays.asList(p0));
while (true){
//动指定offset的起始位置
consumer.seek(p0, 700);
ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(10000));
//每个partition单独获取
for(TopicPartition partition : records.partitions()){
List<ConsumerRecord<String,String>> pRecord = records.records(partition);
for( ConsumerRecord<String,String> record: pRecord){
System.out.printf("partition - %d, offset - %d, key - %s, value - %s%n",
record.partition(),record.offset(), record.key(), record.value());
}
long lastOffset = pRecord.get(pRecord.size() - 1).offset();
//单个partition中的offset,并且进行提交
Map<TopicPartition, OffsetAndMetadata> offset = new HashMap<>();
offset.put(partition,new OffsetAndMetadata(lastOffset + 1));
//提交offset
consumer.commitSync(offset);
System.out.println("===============partition =" + partition + " end ==============");
}
}
}