现代JVM在执行Java代码的时候,通常都会将解释执行与编译执行两者结合起来
所谓解释执行,就是通过解释器来读取字节码,遇到相应的指令就去执行该指令。
所谓编译执行,就是通过即时编译器(Just In Time,JIT) 将字节码转为本地机器码来执行;现代JVM会根据代码热点来生成相应的本地机器码。
基于栈的指令集与基于寄存器的指令集直接的关系:
1、JVM执行指令时所采取的方式是基于栈的指令集
2、基于栈的指令集主要的操作有入栈与出栈两种。
3、基于栈的指令集的优势在于它可以在不同平台之间进行移植,而基于寄存器的指令集是与硬件架构紧密关联的,无法做到可移植。
4、基于栈的指令集的缺点在于完成相同的操作,指令数量通常要比基于寄存器的指令集数量要多;基于栈的指令集是在内存中完成操作的,
而基于寄存器的指令集是直接由CPU来执行的,它是在高速缓冲区进行执行的,速度要快很多。虽然虚拟机可以采用一些优化手段,
但总体来说,基于栈的指令集的执行速度要慢一些。
如对数字2-1的操作,基于栈和基于寄存器的区别
基于栈的指令
1.iconst_1 //将减数1压入栈顶
2.iconst_2 //将被减数2压入栈顶
3.isub //将栈中最上面的两个元素(2和1)弹出来,执行2-1的操作,将2-1的结果1压入栈顶
4.istore_0 //将1放入局部变量表的第0个位置上。
基于寄存器
mov 将2放入寄存器,
sub 后面跟一个参数1,在现有的寄存器上减去1,在把结果放回寄存器。
JVM指令集实例
创建MyTest8.java类
public class MyTest8 {
public int myCalculate(){
int a = 1;
int b = 2;
int c = 3;
int d = 4;
int result = (a + b - c) * d;
return result;
}
}
使用jclasslib查看myCalculate方法
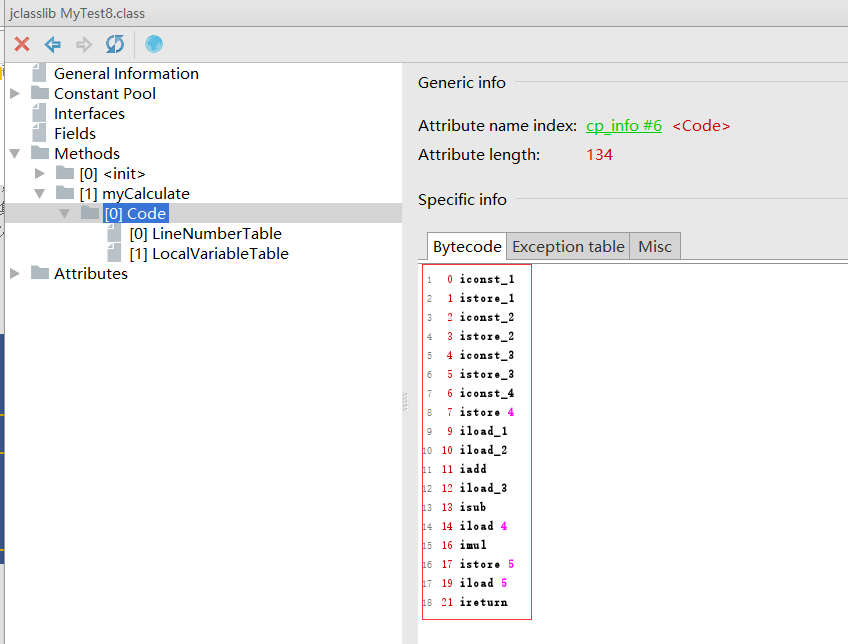
这21条指令就是myCalculat方法的操作步骤
0 iconst_1 //将1放入操作数栈顶
1 istore_1 //弹出操作数栈顶元素,并把元素的值复制到本地变量表索引为1的位置。
2 iconst_2 //将2放入操作数栈顶
3 istore_2 //弹出操作数栈顶元素,并把元素的值复制到本地变量表索引为2的位置。
4 iconst_3 //将3放入操作数栈顶
5 istore_3 //弹出操作数栈顶元素,并把元素的值复制到本地变量表索引为3的位置。
6 iconst_4 //将4放入操作数栈顶
7 istore 4 //弹出操作数栈顶元素,并把元素的值复制到本地变量表索引为4的位置。
9 iload_1 //从本地变量表中索引为1的值压入操作数栈
10 iload_2 //从本地变量表中索引为2的值压入操作数栈
11 iadd //弹出操作数栈最上层的两个元素,进行加操作(1+2),将结果3压入操作数栈
12 iload_3 //从本地变量表中索引为3的值压入操作数栈
13 isub //弹出操作数栈最上层的两个元素,进行减操作(3-3),将结果0压入操作数栈
14 iload 4 //从本地变量表中索引为4的值压入操作数栈
16 imul //弹出操作数栈最上层的两个元素,进行乘法操作(0 * 4),将结果0压入操作数栈
17 istore 5 //弹出操作数栈顶元素,并把元素的值复制到本地变量表索引为5的位置。
19 iload 5 //从本地变量表中索引为5的值压入操作数栈
21 ireturn //弹出当前操作数栈顶元素,将值压到调用者的操作数栈中。当前操作数栈的所有元素都将被丢弃。
本地变量表如下图