1. 工作机制
- 一个数据块在 DataNode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
- DataNode 启动后向 NameNode 注册,通过后,周期性(1小时)的向 NameNode 上报所有的块信息。
- 心跳是每3秒一次,心跳返回结果带有 NameNode 给该 DataNode 的命令如复制块数据到另一台机器,或删除某个数据块。如果超过 10 分钟没有收到某个 DataNode 的心跳,则认为该节点不可用。

==============================
2. 数据完整性
- 当 DataNode 读取 Block 的时候,它会计算 CheckSum。
- 如果计算后的 CheckSum, 与 Block 创建时值不一样, 说明 Block 已经损坏。
- Client 读取其他 DataNode 上的 Block。
- DataNode 在其他文件创建后周期验证 CheckSum;
- 奇偶校验示例(实际使用的是CRC校验):
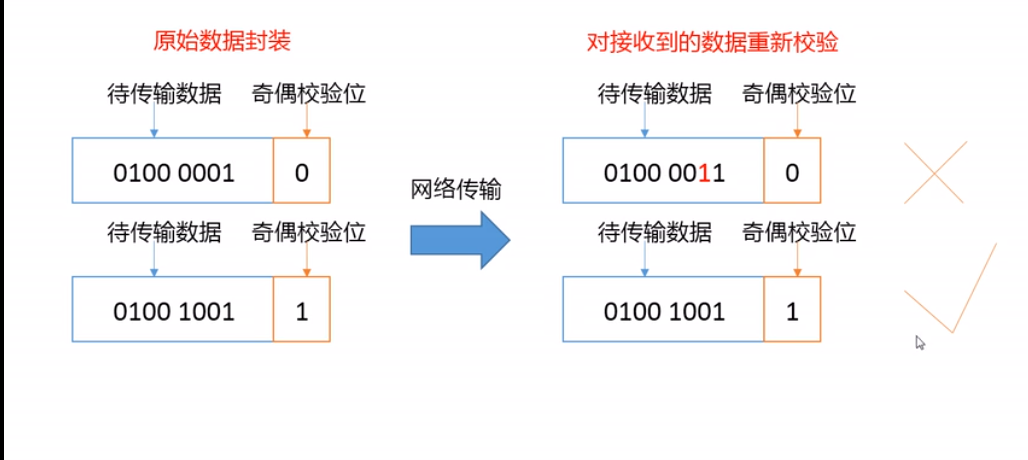
==============================
3. 掉线时限参数设置
- DataNode 进程死亡或者网络故障造成 DataNode 无法与 NameNode 通信;
- NameNode 不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长;
- HDFS 默认的超时时长为10分钟+30秒;
- 如果定义超时时间为 TimeOut, 则超时时长计算公式为:
- TimeOut = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval;
- "dfs.namenode.heartbeat.recheck-interval"默认为5分钟;
- "dfs.heartbeat.interval"默认为3秒;
4. 服役新节点
- 需求:在原有集群基础上,新增加一个节点。
5. 添加白名单
- 添加到白名单的主机节点,都允许访问 NameNode,不在白名单的主机节点,都会被退出。
6. 黑名单设置
- 在黑名单上的主机都会被强制退出。
7. DataNode 多目录配置
- DataNode 也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本。
// hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value>
</property>
8. HDFS 2.X 新特性
8.1 集群间数据拷贝
-
scp 实现两个远程主机之间的文件复制
- 推(push):
scp -r hello.txt root@IP:端口/user/noodles/hello.txt - 拉(pull):
scp -r root@IP:端口/user/noodles/hello.txt hello.txt - 两个远程主机之间:
scp -r root@IP1:端口/user/noodles/hello.txt root@IP2:端口/user/test
- 推(push):
-
采用
distcp命令实现两个 Haoop 集群之间的递归数据复制
bin/hadoop distcp hdfs://IP1:端口1/user/noodles/hello.txt hdfs://IP2:端口2/user/noodles/hello.txt
8.2 小文件存档
- HDFS 存储小文件弊端
- 每个文件均按块存储,每个块的元数据存储在 NameNode 的内存中,因此HDFS存储小文件会非常低效。因为大量的小文件会耗尽 NameNode 中的大部分内存。但注意,存储小文件所需要的磁盘容量和数据块的大小无关。例如,一个1MB的文件设置为128M的块存储,实际使用的是1MB的磁盘空间,而不是128M;
- 解决存储小文件办法之一
- HDFS 存档文件或HAR文件,是一个更高效的文件存档工具。他将文件存入HDFS块,在减少 NameNode 内存使用的同时,允许对文件进行透明的访问。具体说来,HDFS存档文件对内还是一个一个独立文件,对 NameNode 而言却是一个整体,减少了 NameNode 的内存。
- 具体操作步骤:
- 启动YARN进程:
start-yarn.sh - 把"/user/noodles/input"目录里面的所有文件归档成一个名为“input.har”的文件,并把归档后的文件存储到“/user/noodles/output”路径下:
bin/hadoop archive -archiveName input.har -p /user/noodles/input /user/noodles/output
- 启动YARN进程:
8.3 回收站案例
- 开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除,备份等作用。
- 功能参数说明:
- 默认值:
fs.trash.interval=0, 0 表示禁用回收站;其他值表示设置文件的存活时间; - 默认值:
fs.trash.checkpoint.interval=0: 检查回收站的间隔时间。如果该值为0,则该值设置和fs.trash.interval的参数值相等。 - 要求:
fs.trash.checkpoint.interval <= fs.trash.interval
- 默认值:
8.4 快照管理
- 快照相当于对目录做一个备份,并不会立即复制所有文件,而是指向同一个文件。当写入发生时,才会发生新文件。
- 开启指定目录的快照功能:
hdfs dfsadmin in -allowSnapshot 路径 - 禁用指定目录的快照功能,默认是禁用:
hdfs dfsadmin -in disallowSnapshot 路径 - 对目录创建快照:
hdfs dfs -createSnapshot 路径 - 创建指定名称的快照:
hdfs dfs -createSnapshot 路径 名称 - 重命名快照:
hdfs dfs -renameSnapshot 路径 旧名称 新名称 - 列出当前用户所有可快照目录:
hdfs lsSnapshottableDir - 比较两个快照目录的不同之处:
hdfs snapshotDiff 路径1 路径2 - 删除快照:
hdfs dfs -deleteSnapshot 路径
- 开启指定目录的快照功能: