【转】https://blog.csdn.net/haozi_rou/article/details/104846914
之前说了很多机器学习,接下来讲下Spark,Spark是为大规模数据处理而设计的快速通用的计算引擎。他有很多的库,例如Spark core、Spark Sql、Spark on Hive、Spark Streaming等。还有机器学习库例如Spark mllib等。
现在有一个场景,有一个list,里面存的是商品实体,现在需要将这些实体中的id提取到另一个list中,现有阶段就是遍历然后把id提取出来,不管是for还是lambda还是别的方式。但是如果这个list里面的数量非常巨大,那么在jvm内存中做这些事情是不现实的,因此,有了Spark core的Map Reduce,可以将复杂的操作封装成RDD的操作,使我们可以很轻易的进行数据转换。
那么它的原理也很简单,假如有十万条数据,那么spark会拆分成若干条,然后分发给对应的机器,map以后再把所有的数据合并,进行计算如max、min、avg等,然后把结果发给目标机器。
那么对于数据库来说,假如分了三个库,每个库里面都有100w条数据,spark有一个spark sql的库,可以根据很简单的语句例如:select sum(price) from shop来去获取三个库的数据并返回结果。
Spark Streaming是指假如有个数据采集的系统,数据是以流式byte[]的形式发送给spark,定义4个为一个数字,那么spark就可以通过流式处理的方案处理数据运算。
ALS算法实现
召回算法
加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.12</artifactId>
<version>2.4.4</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>14.0.1</version>
</dependency>
public class AlsRecall implements Serializable { public static void main(String[] args) throws IOException { //初始化spark运行环境 SparkSession spark = SparkSession.builder() .master("local") .appName("DianpingApp") .getOrCreate(); JavaRDD<String> csvFile = spark.read().textFile("file:///F:/mouseSpace/project/background/behavior.csv").toJavaRDD(); JavaRDD<Rating> ratingJavaRDD = csvFile.map(new Function<String, Rating>() { @Override public Rating call(String s) throws Exception { return Rating.parseRating(s); } }); Dataset<Row> ratings = spark.createDataFrame(ratingJavaRDD, Rating.class); //将所有的rating数据28分,也就是80%数据做训练,20%做测试 Dataset<Row>[] splits = ratings.randomSplit(new double[]{0.8, 0.2}); Dataset<Row> trainingData = splits[0]; Dataset<Row> testData = splits[1]; ALS als = new ALS() .setMaxIter(10) //最大迭代次数 .setRank(5) //分解出5个特征 //正则化系数,防止过拟合,也就是训练出来的数据过分趋近于真实数据,一旦真实数据有误差,模型预测结果反而不尽如人意 //如何防止?增大数据规模,减少特征的维度,增大正则化系数 //欠拟合:增加维度,减少正则化数 .setRegParam(0.01) .setUserCol("userId") .setItemCol("shopId") .setRatingCol("rating"); //模型训练 ALSModel alsModel = als.fit(trainingData); alsModel.save("file:///F:/mouseSpace/project/background/als"); } public static class Rating implements Serializable{ private int userId; private int shopId; private int rating; private static Rating parseRating(String str){ str = str.replace(""" , ""); String[] strArr = str.split(","); int userId = Integer.parseInt(strArr[0]); int shopId = Integer.parseInt(strArr[1]); int rating = Integer.parseInt(strArr[2]); return new Rating(userId , shopId , rating); } public Rating(int userId, int shopId, int rating) { this.userId = userId; this.shopId = shopId; this.rating = rating; } public int getUserId() { return userId; } public int getShopId() { return shopId; } public int getRating() { return rating; } } }
使用spark将数据读取出来,28分,8用于数据训练,2用于测试,再用als进行模型训练,最后生成ALSModel保存起来。接下来加进去模型评测模块:
public class AlsRecall implements Serializable { public static void main(String[] args) throws IOException { //初始化spark运行环境 SparkSession spark = SparkSession.builder() .master("local") .appName("DianpingApp") .getOrCreate(); JavaRDD<String> csvFile = spark.read().textFile("file:///F:/mouseSpace/project/background/behavior.csv").toJavaRDD(); JavaRDD<Rating> ratingJavaRDD = csvFile.map(new Function<String, Rating>() { @Override public Rating call(String s) throws Exception { return Rating.parseRating(s); } }); Dataset<Row> ratings = spark.createDataFrame(ratingJavaRDD, Rating.class); //将所有的rating数据28分,也就是80%数据做训练,20%做测试 Dataset<Row>[] splits = ratings.randomSplit(new double[]{0.8, 0.2}); Dataset<Row> trainingData = splits[0]; Dataset<Row> testData = splits[1]; ALS als = new ALS() .setMaxIter(10) //最大迭代次数 .setRank(5) //分解出5个特征 //正则化系数,防止过拟合,也就是训练出来的数据过分趋近于真实数据,一旦真实数据有误差,模型预测结果反而不尽如人意 //如何防止?增大数据规模,减少特征的维度,增大正则化系数 //欠拟合:增加维度,减少正则化数 .setRegParam(0.01) .setUserCol("userId") .setItemCol("shopId") .setRatingCol("rating"); //模型训练 ALSModel alsModel = als.fit(trainingData); //模型评测 Dataset<Row> predictions = alsModel.transform(testData); //rmse均方根误差,预测值与真实值的偏差的平方除以观测次数,再开根号 //所以rmse值越小,也就代表训练数据越准确 RegressionEvaluator evaluator = new RegressionEvaluator() .setMetricName("rmse") .setLabelCol("rating") .setPredictionCol("prediction"); double rmse = evaluator.evaluate(predictions); System.out.println("rmse = " + rmse); alsModel.save("file:///F:/mouseSpace/project/background/als"); } public static class Rating implements Serializable{ private int userId; private int shopId; private int rating; private static Rating parseRating(String str){ str = str.replace(""" , ""); String[] strArr = str.split(","); int userId = Integer.parseInt(strArr[0]); int shopId = Integer.parseInt(strArr[1]); int rating = Integer.parseInt(strArr[2]); return new Rating(userId , shopId , rating); } public Rating(int userId, int shopId, int rating) { this.userId = userId; this.shopId = shopId; this.rating = rating; } public int getUserId() { return userId; } public int getShopId() { return shopId; } public int getRating() { return rating; } } }
模型评测就是用剩下的2的数据,用推出来的模型进行测试,然后再用真实数据,用rmse算法算出一个值,这个值越小代表模型准确度越高,可以通过调整迭代次数和rank或是正则化系数来调试rmse的分数。
如果报错,可以在main方法中加:

ALS算法预测
public class AlsRecallPredict { public static void main(String[] args) { System.setProperty("hadoop.home.dir", "F:\spark\hadoop-2.7.1\hadoop-2.7.1"); //初始化spark运行环境 SparkSession spark = SparkSession.builder() .master("local") .appName("DianpingApp") .getOrCreate(); //加载模型进内存 ALSModel alsModel = ALSModel.load("F:/mouseSpace/project/background/als/alsmodel/"); JavaRDD<String> csvFile = spark.read().textFile("file:///F:/mouseSpace/project/background/als/behavior.csv").toJavaRDD(); JavaRDD<Rating> ratingJavaRDD = csvFile.map(new Function<String, Rating>() { @Override public Rating call(String s) throws Exception { return Rating.parseRating(s); } }); Dataset<Row> ratings = spark.createDataFrame(ratingJavaRDD, Rating.class); //给5个用户做离线的召回结果预测 Dataset<Row> users = ratings.select(alsModel.getUserCol()).distinct().limit(5); Dataset<Row> userRecs = alsModel.recommendForUserSubset(users , 20); userRecs.foreachPartition(new ForeachPartitionFunction<Row>() { @Override public void call(Iterator<Row> iterator) throws Exception { //新建数据库连接 Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/dianpingdb?user=root&password=root&useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&nullCatalogMeansCurrent=true"); PreparedStatement preparedStatement = connection.prepareStatement("insert into recommend(id,recommend) values (?,?)"); List<Map<String , Object>> data = new ArrayList<>(); iterator.forEachRemaining(action ->{ int userId = action.getInt(0); List<GenericRowWithSchema> recommendationList = action.getList(1); List<Integer> shopList = new ArrayList<>(); recommendationList.forEach(row -> { Integer shopId = row.getInt(0); shopList.add(shopId); }); String recommendData = StringUtils.join(shopList , ","); Map<String , Object> map = new HashMap<>(); map.put("userId" , userId); map.put("recommend" , recommendData); data.add(map); }); data.forEach(stringObjectMap -> { try { preparedStatement.setInt(1 , (Integer) stringObjectMap.get("userId")); preparedStatement.setString(2 , (String) stringObjectMap.get("recommend")); preparedStatement.addBatch(); } catch (SQLException e) { e.printStackTrace(); } }); preparedStatement.executeBatch(); connection.close(); } }); } public static class Rating implements Serializable { private int userId; private int shopId; private int rating; private static Rating parseRating(String str){ str = str.replace(""" , ""); String[] strArr = str.split(","); int userId = Integer.parseInt(strArr[0]); int shopId = Integer.parseInt(strArr[1]); int rating = Integer.parseInt(strArr[2]); return new Rating(userId , shopId , rating); } public Rating(int userId, int shopId, int rating) { this.userId = userId; this.shopId = shopId; this.rating = rating; } public int getUserId() { return userId; } public int getShopId() { return shopId; } public int getRating() { return rating; } } }
整个过程就是说,spark读取用户数据csv文件,ALS读取模型,根据文件随即选出5个用户做预测,并将预测结果存数据库中。
结果数据库中:
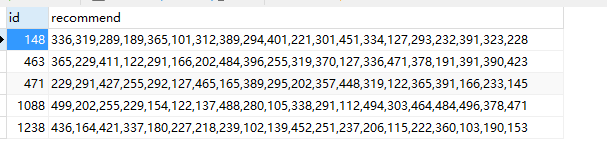
在真实环境中,我们不可能对每个用户都做预测,我们可以选出例如三个月之内上线过的活跃用户来预测。之所以用jdbc存表,是因为是在分布式环境中。当然,避免数据库读取压力,还可以放一份到redis中。
关于代码中的csv中是什么?
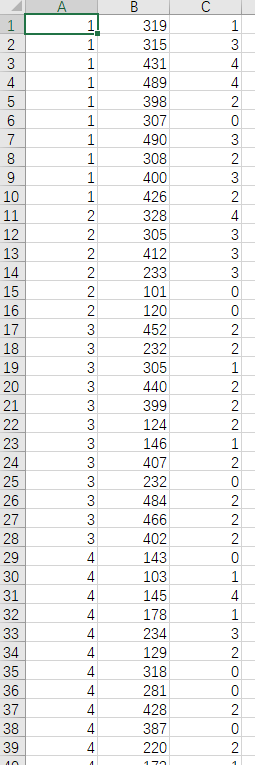
每一列分别是:userid,门店id,打分。
LR算法实现
在我们使用ALS召回算法算出门店以后,接下来我们要使用LR算法来进行排序。对于逻辑回归必要的当然是特征,接下来我们来看以下样例:

关于LR算法之前介绍过,这里就不详细解释了。中间有很多特征,我们只需要把特征放进模型中,去训练就好,但是不同的价格,不同的年龄的特征对于点击率来说都会有影响,而且模型中也不支持字符串,所以我们需要把特征预处理。那特征的处理可以分为离散特征和连续特征。连续特征例如年龄,1-100岁就是连续特征,价格也属于连续特征。离散特征例如性别。评分也可以是连续特征,也可以是离散特征。那两种特征也有不同处理的方法:
离散特征:one-hot编码 ,就是这个特征是1,其他的都是0
连续特征:z-score标准化(x-mean)/std,例如价格,我们可以算出一个平均数和标准差,用公式就可以把数值压缩在0-1之间
连续特征:max-min标准化 (x-min)/(max-min)
连续特征离散化:bucket编码,例如年龄,虽然1-100岁这样的属于连续特征,但是我们可以分类,比如1-10岁,10-20岁等等,也就有了离散化特征
再看下面文件:

A-D是年龄的分类,EF是性别分类,G是评分,用max-min的方式,H-K人均价格使用bucket的方式, L是点击率
接下来上代码:
public class LRTrain { public static void main(String[] args) throws IOException { //初始化spark运行环境 SparkSession spark = SparkSession.builder() .master("local") .appName("DianpingApp") .getOrCreate(); //加载特征及label训练文件 JavaRDD<String> csvFile = spark.read().textFile("file:///F:/mouseSpace/project/background/lr/feature.csv").toJavaRDD(); //做转化 JavaRDD<Row> rowJavaRDD = csvFile.map(new Function<String, Row>() { @Override public Row call(String s) throws Exception { s = s.replace(""" , ""); String[] strArr = s.split(","); return RowFactory.create(new Double(strArr[11]), Vectors.dense( Double.valueOf(strArr[0]), Double.valueOf(strArr[1]), Double.valueOf(strArr[2]), Double.valueOf(strArr[3]), Double.valueOf(strArr[4]), Double.valueOf(strArr[5]), Double.valueOf(strArr[6]), Double.valueOf(strArr[7]), Double.valueOf(strArr[8]), Double.valueOf(strArr[9]), Double.valueOf(strArr[10]))); } }); StructType schema = new StructType( new StructField[]{ new StructField("label" , DataTypes.DoubleType , false , Metadata.empty()), new StructField("features" , new VectorUDT(), false , Metadata.empty()) } ); Dataset<Row> data = spark.createDataFrame(rowJavaRDD , schema); //分开训练和测试 Dataset<Row>[] splits = data.randomSplit(new double[]{0.8, 0.2}); Dataset<Row> trainingData = splits[0]; Dataset<Row> testData = splits[1]; LogisticRegression lr = new LogisticRegression() .setMaxIter(10) .setRegParam(0.3) .setElasticNetParam(0.8) .setFamily("multinomial"); //多分类 //训练 LogisticRegressionModel lrModel = lr.fit(trainingData); lrModel.save("file:///F:/mouseSpace/project/background/lr/lrmodel"); //测试评估 Dataset<Row> predictions = lrModel.transform(testData); //评价指标 MulticlassClassificationEvaluator evaluator = new MulticlassClassificationEvaluator(); double accuracy = evaluator.setMetricName("accuracy").evaluate(predictions); System.out.println("auc = " + accuracy); } }
过程跟als很像,就不多说了。
GBDT算法实现
public class GBDTTrain { public static void main(String[] args) throws IOException { System.setProperty("hadoop.home.dir", "F:\spark\hadoop-2.7.1\hadoop-2.7.1"); //初始化spark运行环境 SparkSession spark = SparkSession.builder() .master("local") .appName("DianpingApp") .getOrCreate(); //加载特征及label训练模型 JavaRDD<String> csvFile = spark.read().textFile("file:///F:/mouseSpace/project/background/lr/feature.csv").toJavaRDD(); //特征转化 JavaRDD<Row> rowJavaRDD = csvFile.map(new Function<String, Row>() { @Override public Row call(String s) throws Exception { s = s.replace(""" , ""); String[] strArr = s.split(","); return RowFactory.create(new Double(strArr[11]), Vectors.dense( Double.valueOf(strArr[0]), Double.valueOf(strArr[1]), Double.valueOf(strArr[2]), Double.valueOf(strArr[3]), Double.valueOf(strArr[4]), Double.valueOf(strArr[5]), Double.valueOf(strArr[6]), Double.valueOf(strArr[7]), Double.valueOf(strArr[8]), Double.valueOf(strArr[9]), Double.valueOf(strArr[10]))); } }); StructType schema = new StructType( new StructField[]{ new StructField("label" , DataTypes.DoubleType , false , Metadata.empty()), new StructField("features" , new VectorUDT(), false , Metadata.empty()) } ); Dataset<Row> data = spark.createDataFrame(rowJavaRDD , schema); //分开训练和测试 Dataset<Row>[] splits = data.randomSplit(new double[]{0.8, 0.2}); Dataset<Row> trainingData = splits[0]; Dataset<Row> testData = splits[1]; GBTClassifier classifier = new GBTClassifier() .setLabelCol("label") .setFeaturesCol("features") .setMaxIter(10); GBTClassificationModel gbtClassificationModel = classifier.train(trainingData); gbtClassificationModel.save("file:///F:/mouseSpace/project/background/lr/gbdtmodel"); //测试评估 Dataset<Row> predictions = gbtClassificationModel.transform(testData); //评价指标 MulticlassClassificationEvaluator evaluator = new MulticlassClassificationEvaluator(); double accuracy = evaluator.setMetricName("accuracy").evaluate(predictions); System.out.println("auc = " + accuracy); } }
跟lr算法非常像,spark部分完全一样,只是在加载算法器的时候不一样而已。