一、准备
1.1 软件版本
- Ubuntu 16.04.6 (ubuntu-16.04.6-server-amd64.iso)
- JDK 1.8 (jdk-8u201-linux-x64.tar.gz)
- Hadoop 2.7.7 (hadoop-2.7.7.tar.gz)
- Spark 2.1.0 (spark-2.1.0-bin-hadoop2.7.tgz)
1.2 网络规划
本文规划搭建3台机器组成集群模式,IP与计算机名分别为, 如果是单台搭建,只需填写一个即可
192.168.241.132 master
192.168.241.133 slave1
192.168.241.134 slave2
1.3 软件包拷贝
可将上述软件包拷贝到3台机器的opt目录下
- JDK 1.8
- Hadoop 2.7.7
- Spark 2.1.0
1.4 SSH设置
修改/etc/ssh/sshd_config文件,将以下三项开启yes状态
PermitRootLogin yes
PermitEmptyPasswords yes
PasswordAuthentication yes
重启ssh服务
service ssh restart
这样root用户可直接登陆,以及为后续ssh无密码登录做准备。
1.5 绑定IP和修改计算机名
1.5.1 修改/etc/hosts,添加IP绑定,并注释127.0.1.1(不注释会影响hadoop集群)
root@master:/opt# cat /etc/hosts
127.0.0.1 localhost
#127.0.1.1 ubuntu
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
192.168.241.132 master
192.168.241.133 slave1
192.168.241.134 slave2
1.5.2 修改/etc/hostname,为绑定计算机名。(计算机名和上面hosts绑定名必须一致)
1.6 SSH无密码登陆(需提前安装ssh)
1.用rsa生成密钥,一路回车。
ssh-keygen -t rsa
2.进到当前用户的隐藏目录(.ssh)
cd ~/.ssh
3.把公钥复制一份,并改名为authorized_keys
cp id_rsa.pub authorized_keys
这步执行完后,在当前机器执行ssh localhost可以无密码登录本机了。
如本机装有ssh-copy-id命令,可以通过
ssh-copy-id root@第二台机器名
然后输入密码,在此之后在登陆第二台机器,可以直接
ssh[空格]第二台机器名
进行登录。初次执行会提示确认,输入yes和登陆密码,之后就没提示了。
1.7 JDK安装(三台机器可同步进行)
下载:jdk-8u201-linux-x64.tar.gz 包,放到/opt下解压
1.7.1 将解压后的文件夹重命名
mv jdk1.8.0_201 jdk
1.7.2 将JDK环境变量配置到/etc/profile中
export JAVA_HOME=/opt/jdk
export JRE_HOME=/opt/jdk/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
1.7.3 检查JDK是否配置好
source /etc/profile
java -version
提示以下信息代表JDK安装完成:
java version "1.8.0_201"
Java(TM) SE Runtime Environment (build 1.8.0_201-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)
1.8 其他配置
1.8.1 网络配置
修改为固定IP ,/etc/network/interfaces
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
auto eth0
#iface eth0 inet dhcp
iface eth0 inet static
address 192.168.241.132
netmask 255.255.255.0
gateway 192.168.20.1
重启网络
service networking restart
1.8.2 DNS配置
第一种方法,永久改
修改/etc/resolvconf/resolv.conf.d/base(这个文件默认是空的)
nameserver 119.6.6.6
保存后执行
resolvconf -u
查看resolv.conf 文件就可以看到我们的设置已经加上
cat /etc/resolv.conf
重启resolv
/etc/init.d/resolvconf restart
第二种方法,临时改
修改 /etc/resolv.conf文件,增加
nameserver 119.6.6.6
重启resolv
/etc/init.d/resolvconf restart
二、Hadoop部署
2.1 Hadoop安装(三台机器可同步进行)
- 下载hadoop2.7.7(hadoop-2.7.7.tar.gz)
- 解压 tar -zxvf hadoop-2.7.7.tar.gz ,并在主目录下创建tmp、dfs、dfs/name、dfs/node、dfs/data
cd /opt/hadoop-2.7.7
mkdir tmp
mkdir dfs
mkdir dfs/name
mkdir dfs/node
mkdir dfs/data
2.2 Hadoop配置
以下操作都在hadoop-2.7.7/etc/hadoop下进行
2.2.1 编辑hadoop-env.sh文件,修改JAVA_HOME配置项为JDK安装目录
export JAVA_HOME=/opt/jdk
2.2.2 编辑core-site.xml文件,添加以下内容
其中master为计算机名,/opt/hadoop-2.7.7/tmp为手动创建的目录
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop-2.7.7/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
</configuration>
2.2.3 编辑hdfs-site.xml文件,添加以下内容
其中master为计算机名,
file:/opt/hadoop-2.7.7/dfs/name和file:/opt/hadoop-2.7.7/dfs/data为手动创建目录
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-2.7.7/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-2.7.7/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
复制mapred-site.xml.template并重命名为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
2.2.4 编辑mapred-site.xml文件,添加以下内容
其中master为计算机名
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
2.2.5 编辑yarn-site.xml文件,添加以下内容
其中master为计算机名
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
2.2.6 修改slaves文件,添加集群节点(多机添加多个)
添加以下
master
slave1
slave2
2.2.7 Hadoop集群搭建
hadoop配置集群,可以将配置文件etc/hadoop下内容同步到其他机器上,既2.2.1-2.2.6无需在一个个配置。
cd /opt/hadoop-2.7.7/etc
scp -r hadoop root@另一台机器名:/opt/hadoop-2.7.7/etc
2.3 Hadoop启动
1.格式化一个新的文件系统,进入到hadoop-2.7.7/bin下执行:
./hadoop namenode -format
2.启动hadoop,进入到hadoop-2.7.7/sbin下执行:
./start-all.sh
看到如下内容说明启动成功
root@master:/opt/hadoop-2.7.7/sbin# ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-namenode-master.out
slave2: starting datanode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-datanode-slave2.out
master: starting datanode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-datanode-master.out
slave1: starting datanode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-datanode-slave1.out
Starting secondary namenodes [master]
master: starting secondarynamenode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.7.7/logs/yarn-root-resourcemanager-master.out
slave2: starting nodemanager, logging to /opt/hadoop-2.7.7/logs/yarn-root-nodemanager-slave2.out
slave1: starting nodemanager, logging to /opt/hadoop-2.7.7/logs/yarn-root-nodemanager-slave1.out
master: starting nodemanager, logging to /opt/hadoop-2.7.7/logs/yarn-root-nodemanager-master.out
2.4 Hadoop集群检查
方法1:检查hadoop集群,进入hadoop-2.7.7/bin下执行
./hdfs dfsadmin -report
查看Live datanodes 节点个数,例如:Live datanodes (3),则表示3台都启动成功
root@master:/opt/hadoop-2.7.7/bin# ./hdfs dfsadmin -report
Configured Capacity: 621051420672 (578.40 GB)
Present Capacity: 577317355520 (537.67 GB)
DFS Remaining: 577317281792 (537.67 GB)
DFS Used: 73728 (72 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
Live datanodes (3):
方法2:访问8088端口,http://192.168.241.132:8088/cluster/nodes
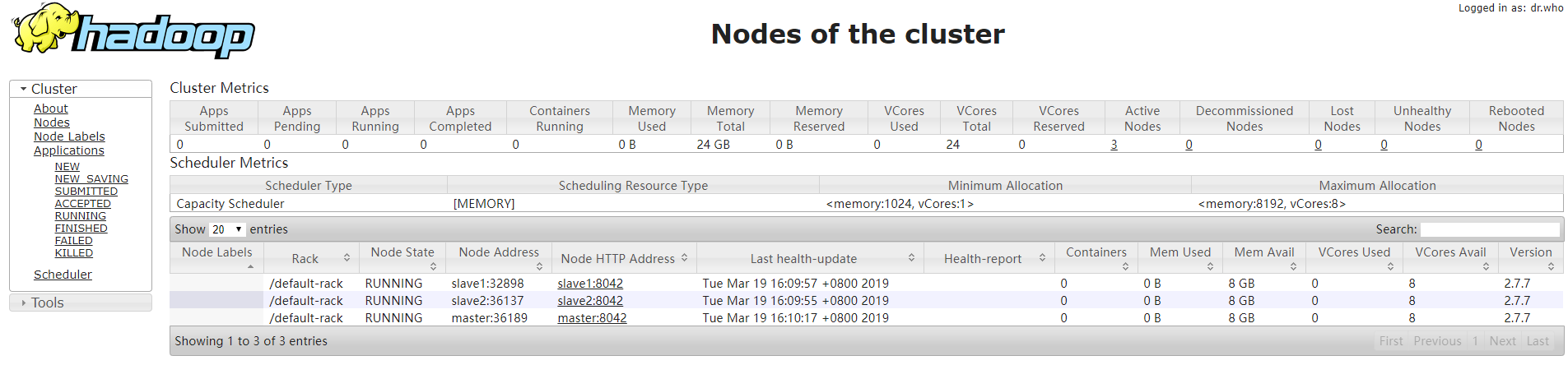
方法3:访问50070端口http://192.168.241.132:50070/
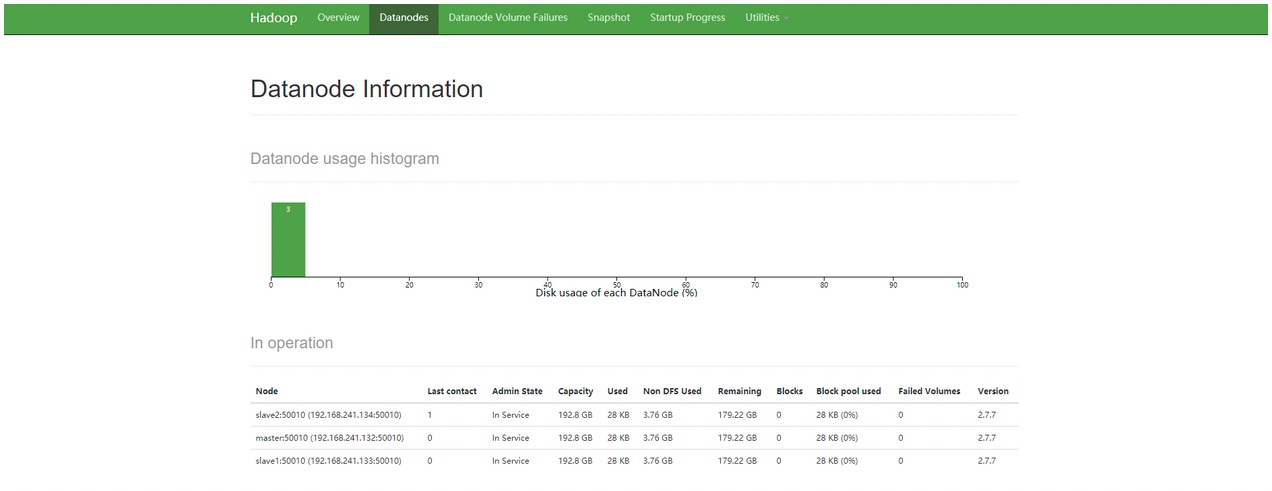
三、Spark部署
3.1 Spark安装(三台机器可同步进行)
- 下载spark-2.1.0-bin-hadoop2.7.tgz,放到opt下解压。
- 将spark环境变量配置到/etc/profile中
export SPARK_HOME=/opt/spark-2.1.0-bin-hadoop2.7
export PATH=$JAVA_HOME/bin:$SPARK_HOME/bin:$PATH
3.2 Spark配置
1.进入spark-2.1.0-bin-hadoop2.7/conf复制spark-env.sh.template并重命名为spark-env.sh
cp spark-env.sh.template spark-env.sh
编辑spark-env.sh文件,添加以下内容
export JAVA_HOME=/opt/jdk
export SPARK_MASTER_IP=192.168.241.132
export SPARK_WORKER_MEMORY=8g
export SPARK_WORKER_CORES=4
export SPARK_EXECUTOR_MEMORY=4g
export HADOOP_HOME=/opt/hadoop-2.7.7/
export HADOOP_CONF_DIR=/opt/hadoop-2.7.7/etc/hadoop
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/jdk/jre/lib/amd64
2.把slaves.template拷贝为slaves,并编辑 slaves文件
cp slaves.template slaves
编辑slaves文件,添加以下内容(多机添加多个)
master
slave1
slave2
3.3 配置Spark集群
可以将配置文件spark-2.1.0-bin-hadoop2.7/conf下内容同步到其他机器上,既3.2无需在一个个配置。
scp -r conf root@另一台机器名:/opt/spark-2.1.0-bin-hadoop2.7
3.4 Spark启动
启动spark,进入spark-2.1.0-bin-hadoop2.7/sbin下执行
./start-all.sh
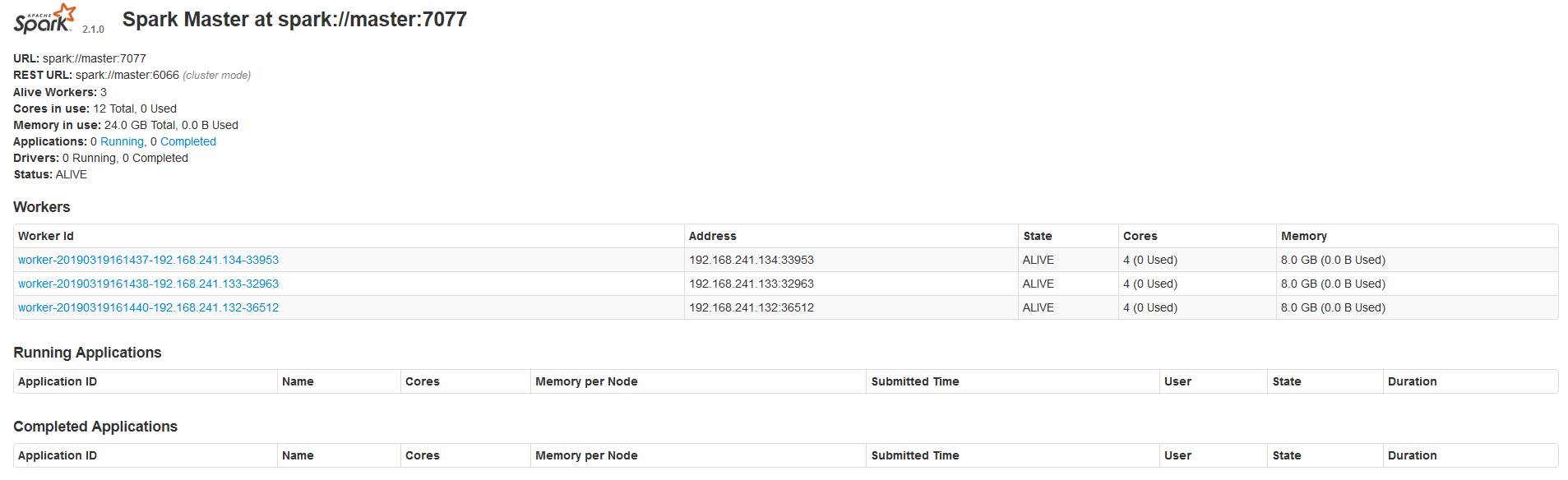
3.5 Spark集群检查
访问http://192.168.241.134:8080/
注意:配置Spark集群,需要保证子节点内容和主节点内容一致。