Hadoop
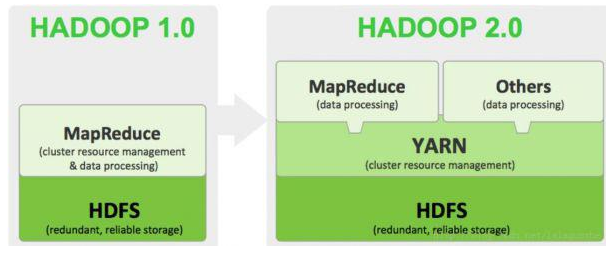
Hadoop是Apache旗下的一个用java语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。它的核心组件有:
- HDFS(分布式文件系统):解决海量数据存储
- YARN(作业调度和集群资源管理的框架):解决资源任务调度
- MAPREDUCE(分布式运算编程框架):解决海量数据计算
广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈
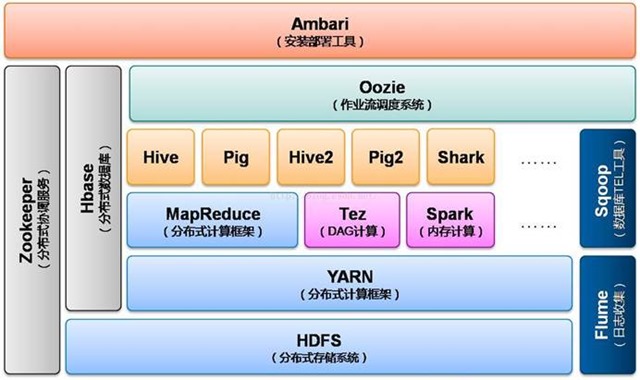
当下的Hadoop已经成长为一个庞大的体系,随着生态系统的成长,新出现的项目越来越多,其中不乏一些非Apache主管的项目,这些项目对HADOOP是很好的补充或者更高层的抽象。比如:
- HDFS:分布式文件系统
- MAPREDUCE:分布式运算程序开发框架
- HIVE:基于HADOOP的分布式数据仓库,提供基于SQL的查询数据操作
- HBASE:基于HADOOP的分布式海量数据库
- ZOOKEEPER:分布式协调服务基础组件
- Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
- OOZIE:工作流调度框架
- Sqoop:数据导入导出工具(比如用于mysql和HDFS之间)
- FLUME:日志数据采集框架
- IMPALA:基于hive的实时sql查询分析
Spark
Spark 只是一个计算框架,它的能力是在现有数据的基础上提供一个高性能的计算引擎,然后提供一些上层的处理工具比如做数据查询的Spark SQL、做机器学习的MLlib等;而hadoop的功能则更加全面,它是包括了数据存储(HDFS)、任务计划和集群资源管理(YARN)以及离线并行计算(MapReduce)的一整套技术栈。
因此可以看出,Spark 其实是依赖于第三方的数据源的,但这也是 Spark 灵活的地方,它能够配合HBase、Hive,以及关系型数据库Oracle、Mysql等多种类型的数据工作。
从上图可以看出,人们现在甚至已经把spark纳入到hadoop的生态之中了(虽然这种说法是否妥当还需验证),足以见证:spark仅仅只是一个计算框架,它不能,也没有必要来替代hadoop,它存在最大的价值就是弥补MapReduce计算性能上的不足,提供超越其数倍甚至数十倍的计算能力。因此,我们可以将spark与MapReduce对标起来。
HIVE
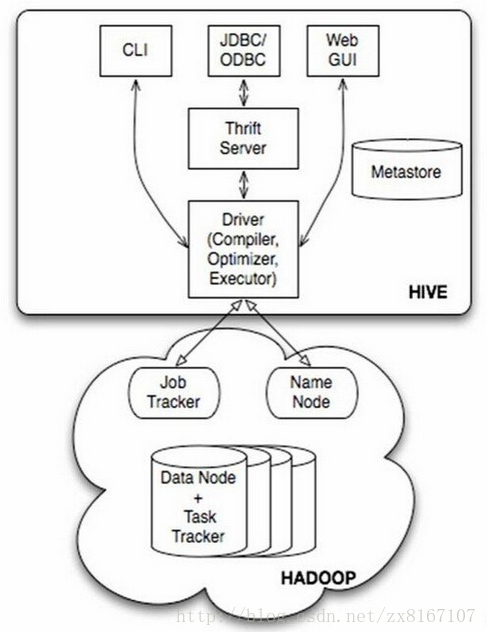
- hive不是数据库,而是数据仓库,主要依赖于hadoop来实现
- 底层文件系统是hadoop的hdfs,实现对hdfs上结构化数据的SQL操作HQL,速度较慢
- 计算引擎是hadoop的mapreduce
- 依靠存储在其他关系型数据库metastore来对hdfs结构化数据进行管理,实现类似数据库的功能
- 不具备数据库的一些主键、索引、update操作等特性,但是提供了分区、块索引、SQL等特性
- 比较适合存储海量的全量(历史+更新)轨迹数据,比对数据进行批量的挖掘、分析等操作
总结一下,hive是基于hadoop实现的数据仓库,适合存储海量全量数据,支持类SQL操作,性能相对较差,数据存储有一定的限制,不支持更新、索引等事务。适合海量数据的挖掘和分析,通俗一点来说,hive其实就是借助mysql等数据库在hadoop上层套了一个壳,来实现对hdfs上结构化数据的映射,为上层提供sql服务。
HBASE
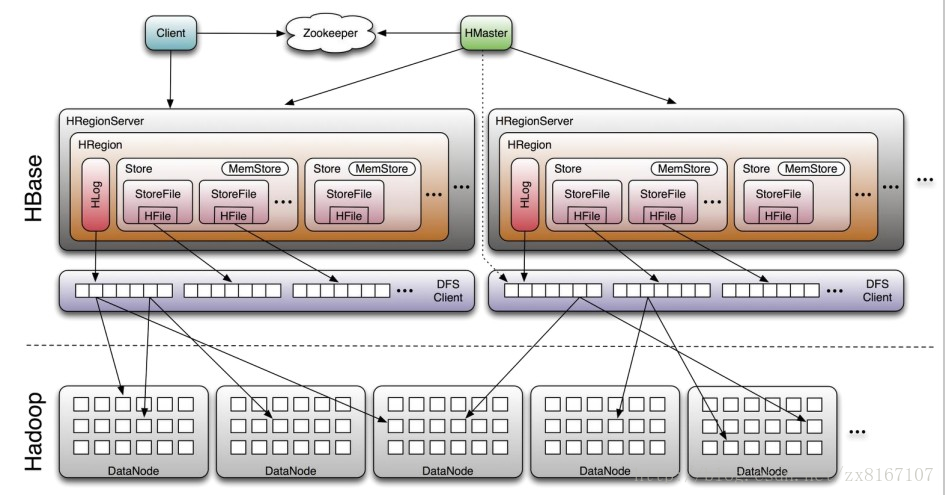
即Hadoop databse,顾名思义就是一个hadoop的数据库
- nosql数据库之一,基于列式存储(列族),适合海量半结构化数据的存储和检索
- 不支持SQL、适合海量、带时间序列的数据的存储和检索、性能较好
- 原生支持基于rowkey的一级索引,rowkey按照字典序进行排序
- 运算执行引擎是hbase自身提供、底层存储基于hdfs
总结一下,hbase是NOSQL数据库的一种,基于分布式列式存储,适合海量半结构化带时间序列的数据的存储和检索,性能较优秀,hbase底层存储依赖于hdfs,与rdbms的区别与其他nosql类似,比如不支持SQL、事务性相对较差等等。
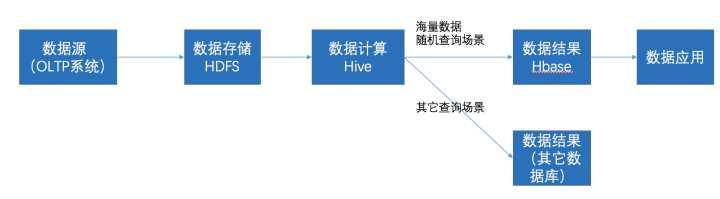
hbase是数据库、hive是数据仓库,而这有很大的区别、也有很多类似的地方比如都属于hadoop生态圈、存储都基于hdfs等。一般来说用hive作为海量结构化全量数据的存储、运算、挖掘、分析;hbase用来作为海量半结构化数据的存储、检索;这二者可以很好协同工作,hive上计算完的结果放在hbase中供检索,也可以将hbase里面的结构化数据和hive相结合,实现对hbase的sql操作等等。在大数据架构中,Hive和HBase是协作关系,数据流一般如下图: