Java集合(十)继承Map接口的HashMap
一、HashMap简介(基于JDK1.8)
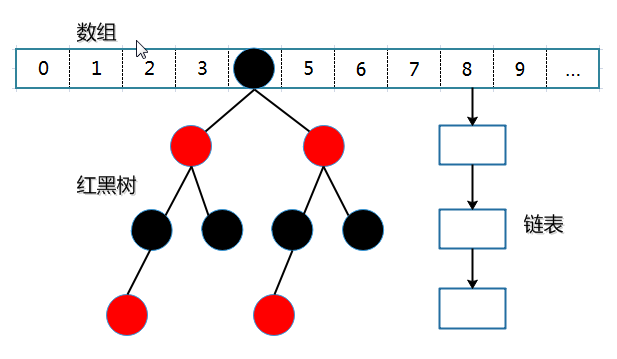
HashMap是基于哈希表(散列表),实现Map接口的双列集合,数据结构是“链表散列”,也就是数组+链表 ,key唯一的value可以重复,允许存储null 键null 值,元素无序。JDK1.8对HashMap进行一个大的优化,底层数据结构有“数组+链表”的形式,变成“数组+链表+红黑树”的形式,当链表长度超过阈值时,将链表转换为红黑树,这样大大减少了查找时间。
HashMap 的实例有两个参数影响其性能:“初始容量” 和 “负载因子”。容量 是哈希表中桶的数量,初始容量 只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认负载因子是 0.75F, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
(一)、HashMap与Map接口的关系
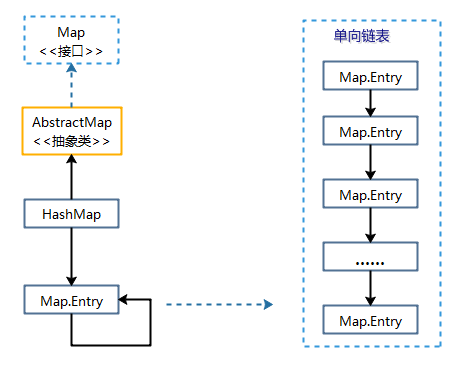
(二)、数据结构
JDK 1.8 的 HashMap 的数据结构如下图所示,当链表节点较少时仍然是以链表存在,当链表节点较多时(大于8)会转为红黑树。
二、HashMap的继承结构
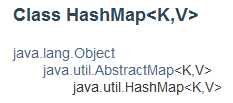

从HashMap继承结构和HashMap与Map接口关系图,可以看出:
-
- HashMap继承于AbstractMap类,实现了Map接口。Map是"key-value键值对"接口,AbstractMap实现了"键值对"的通用函数接口。
- HashMap是通过"拉链法(链地址法)"实现的哈希表。
- HashMap实现了Cloneable接口,即实现了clone()方法。clone()方法的作用很简单,就是克隆一个HashMap对象并返回。
- HashMap实现Serializable接口,分别实现了串行读取、写入功能。
- 串行写入函数是writeObject(),它的作用是将HashMap的“总的容量,实际容量,所有的Entry”都写入到输出流中。
- 而串行读取函数是readObject(),它的作用是将HashMap的“总的容量,实际容量,所有的Entry”依次读出。
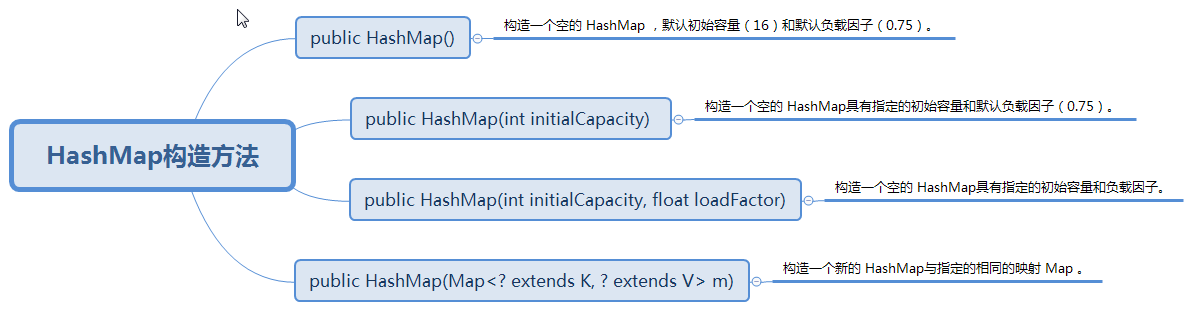
三、HashMap的构造方法
四、HashMap重要成员属性
(一)、table
是一个Node<K,V>[]数组类型,Node<K,V>实现了Map.Entry接口,是链表的节点。哈希表的"key-value键值对"都是存储在Node<K,V>数组中的。
(二)、size
是HashMap的大小,它是HashMap保存的键值对的数量。
(三)、threshold
是HashMap的阈值,用于判断是否需要调整HashMap的容量。threshold的值="容量 * 负载因子",当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
(四)、loadFactor
负载因子。当HashMap达到阈值时,负载因子 * 容量将HashMap扩容。
(五)、modCount
记录HashMap修改的次数,主要用来是用来实现fail-fast机制的。
五、HashMap的遍历
(一)、通过entrySet方法遍历HashMap的键值对
1、通过entrySet()方法获取HashMap“键值对”集合Set;
2、通过Iterator迭代器遍历获取的HashMap的“键值对”集合Set。


1 Set<Map.Entry<K,V>> set = map.entrySet(); 2 Iterator iterator = set.iterator(); 3 while(iterator.hasNext()) { 4 Object obj = iterator.next(); 5 }
(二)、通过keySet方法遍历HashMap的键
1、通过keySet()方法获取HashMap“键”的Set集合;
2、通过Iterator迭代器遍历获取的HashMap的“键”集合Set。
1 Set<Map.Entry<K, V>> set = map.keySet(); 2 Iterator iterator = set.iterator(); 3 while(iterator.hasNext()) { 4 Object obj = iterator.next(); 5 }
(三)、通过value方法遍历HashMap的值
1、通过value()方法获取HashMap“值”的Set集合;
2、通过Iterator迭代器遍历获取的HashMap的“值”集合Set。
1 Collection coll = map.values(); 2 Iterator iterator = coll.iterator(); 3 while(iterator.hasNext()) { 4 Object obj = iterator.next(); 5 }
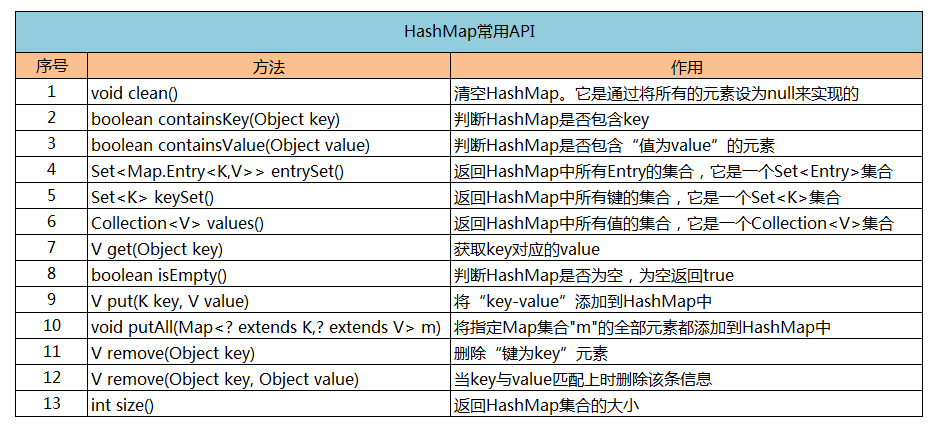
六、HashMap常用API
七、总结
1、HashMap 的底层是个 Node 数组(Node<K,V>[] table),在数组的具体索引位置,如果存在多个节点,则可能是以链表或红黑树的形式存在。
2、HashMap 的默认初始容量(capacity)是 16,capacity 必须为 2 的幂次方;默认负载因子(load factor)是 0.75;实际能存放的节点个数(threshold,即触发扩容的阈值)= capacity * load factor。
3、HashMap 有 threshold 属性和 loadFactor 属性,但是没有 capacity 属性。初始化时,如果传了初始化容量值,该值是存在 threshold 变量,并且 Node 数组是在第一次 put 时才会进行初始化,初始化时会将此时的 threshold 值作为新表的 capacity 值,然后用 capacity 和 loadFactor 计算新表的真正 threshold 值。
4、当同一个索引位置的节点在增加后达到 9 个时,并且此时数组的长度大于等于 64,则会触发链表节点(Node)转红黑树节点(TreeNode),转成红黑树节点后,其实链表的结构还存在,通过 next 属性维持。链表节点转红黑树节点的具体方法为源码中的 treeifyBin 方法。而如果数组长度小于64,则不会触发链表转红黑树,而是会进行扩容。
5、当同一个索引位置的节点在移除后达到 6 个时,并且该索引位置的节点为红黑树节点,会触发红黑树节点转链表节点。红黑树节点转链表节点的具体方法为源码中的 untreeify 方法。
6、HashMap 是非线程安全的,在并发场景下使用 ConcurrentHashMap 来代替。