Elasticsearch Jar包准备
所有节点导入elasticsearch-hadoop-5.5.1.jar
/opt/cloudera/parcels/CDH-5.12.0-1.cdh5.12.0.p0.29/lib/hive/lib/elasticsearch-hadoop-5.5.1.jar
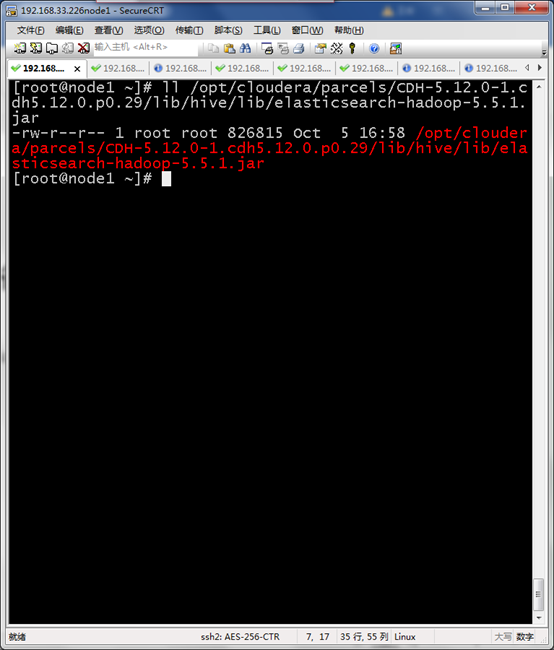
HDFS导入数据准备
hdfs dfs -ls /user/logb/464/part-r-00000
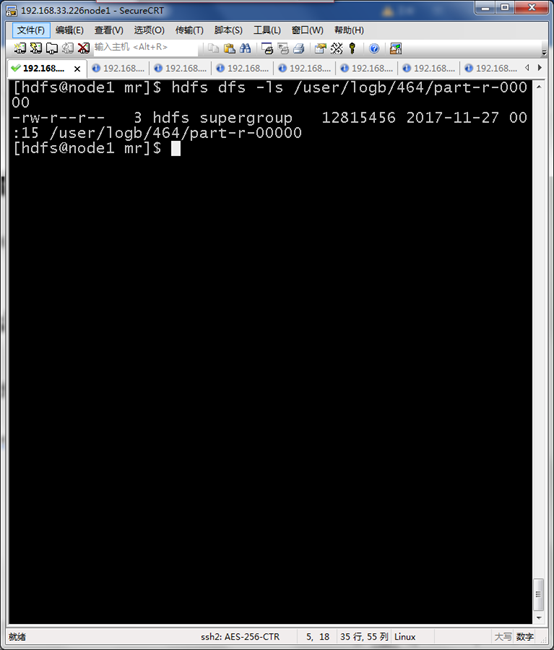
进入HIVE shell 执行
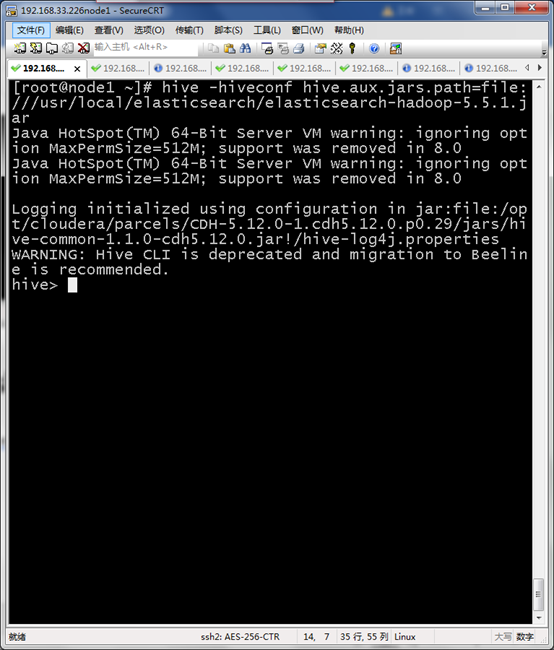
引用Elasticsearch jar包进行hive界面
hive -hiveconf hive.aux.jars.path=file:///usr/local/elasticsearch/elasticsearch-hadoop-5.5.1.jar
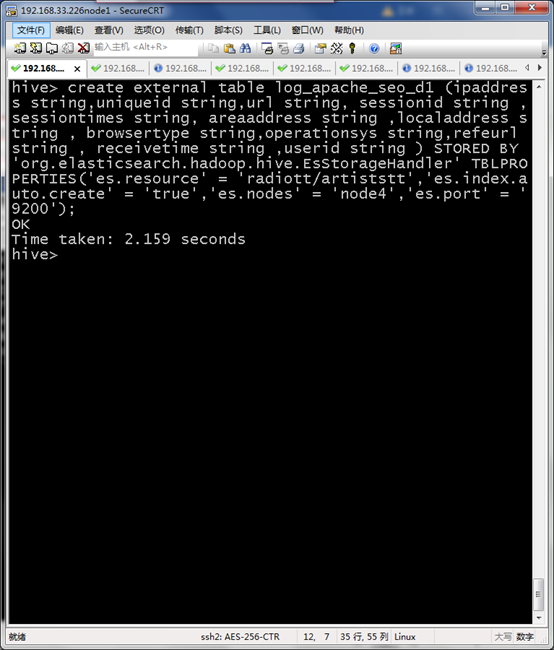
创建与Elasticsearch对接log_apache_seo_d1外部表
create external table log_apache_seo_d1 (ipaddress string,uniqueid string,url string, sessionid string ,sessiontimes string, areaaddress string ,localaddress string , browsertype string,operationsys string,refeurl string , receivetime string ,userid string ) STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES('es.resource' = 'radiott/artiststt','es.index.auto.create' = 'true','es.nodes' = 'node4','es.port' = '9200');
创建源数据表log_apache_seo_source_d1
CREATE TABLE log_apache_seo_source_d1 (ipaddress string,uniqueid string,url string, sessionid string ,sessiontimes string, areaaddress string ,localaddress string , browsertype string,operationsys string,refeurl string , receivetime string ,userid string ) row format delimited fields terminated by ' ' stored as textfile;
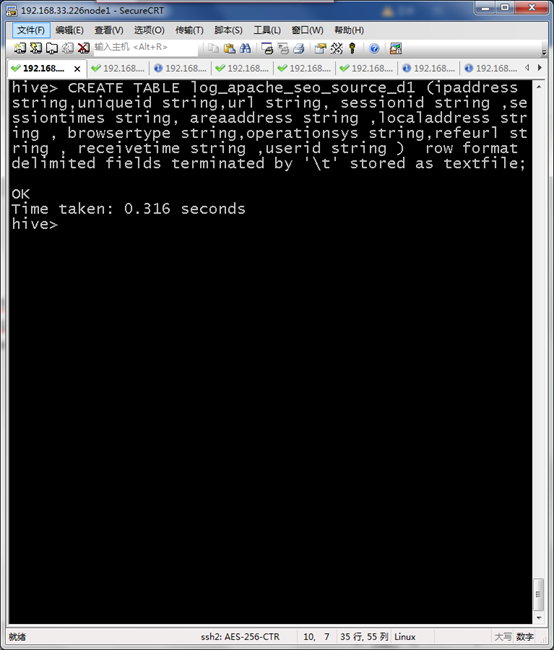
加载MR结果到HIVE
load data inpath '/user/logb/464/part-r-00000' into table log_apache_seo_source_d1 ;

将HIVE数据加载到Elasticsearch所需表中
insert overwrite table log_apache_seo_d1 select s.ipaddress,s.uniqueid,s.url,s.sessionid,s.sessiontimes,s.areaaddress,s.localaddress,s.browsertype,s.operationsys,s.refeurl,s.receivetime,s.userid from log_apache_seo_source_d1 s;
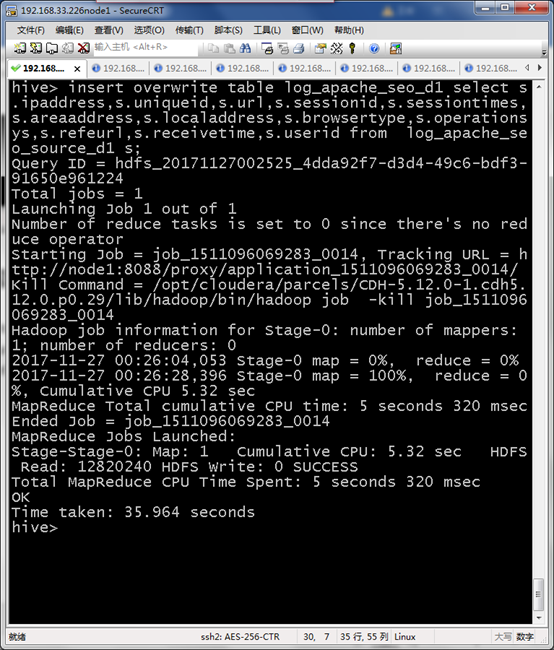
编写shell脚本
#!/bin/sh
# upload logs to hdfs
hive -e "
set hive.enforce.bucketing=true;
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
load data inpath '/user/logb/464/part-r-00000' into table log_apache_seo_source_d1 ;
"
执行脚本任务
0 */2 * * * /opt/bin/hive_opt/crontab_import.sh