先啰嗦两句
最近在看Qlearning和Sarsa的机器强化学习算法,两个都看了之后突然很蒙,昨天差不多有一整天吧,一直被标题这两个问题所困扰着,在这里记录下自己的心得,以及希望给和我一样有过困扰或者正在有困扰的同学做出令人满意的回答。
再啰嗦两句
本文将会一语道破似的讲出以上两个问题的答案,伴随着少量解析,如果对以上这两个算法存在其他疑惑或者不是很了解的同学,这里给出两个链接,希望对大家有所帮助,这两篇文章也是良心制作,点赞!
正文开始
Qlearning和Sarsa真的很像,如果已经有了其中一个代码,只需稍作修改就可以得到另一个。
实际使用时我们会更多的使用Sarsa,因为我们不会有那么多次机会给我们犯错(Qlearning勇敢,为了到达目标什么都敢尝试不怕出错的性格造成了他会在学习时出错会多一些)
接下来解答问题
说到底的区别
更新Q表的方式不同(这里暂时将二者的表格都称作Q表)
Qlearning:

Sarsa:

这里可以看到,Qlearning的更新方式是强制性的,或者可以说是人为的,偏置的,虎头虎脑的,在衰减的后面乘上了一个Q的最大值。
而Sarsa是通过greedy的方式选择下一次的行动。
这个就是说到底的区别
那么为啥Sarsa胆小呢
这里首先给大家缕清一个概念,他们两个虽然在更新Q表上的方式不一样,但是在实际操作时,都会选择那个Q表中比较大的Q值作为下一个Action。
说Sarsa胆小的原因,说到底是因为两个人的Q表中,Q值最大的位置不一样,也就是二者更新Q表的方式不同导致的。
接下来更形象具体的说明一下
这里引用我开头第一个引用的的文章的图片
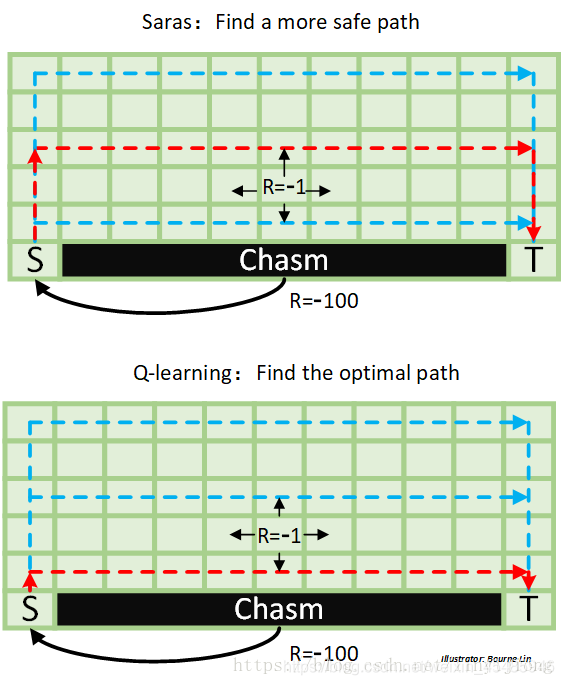
先说Qlearning:
更新Q表时,Qlearning只知道奔Q值最大的方向去,其他的一律不管不顾。。。因此造成了在他的Q表中,红色的线上的Q值是最大的。
在更新Q表时,如果选择了其他的路,最后虽然到达了终点,但是因为绕了多余的路(每多走一步R值为-1,掉悬崖了R值为-100),导致当前选择的这条绕远的路,在更新Q表时,是一步接一步的被降低Q值,虽说红色的那条路也降低Q值,但是相比之下,红色那条路降低的Q值更少,因此最后Qlearning就选择了那条红色的路。
再说Sarsa:
由于Sarsa不是被人为的强行加上必须选择Qmax,而是以greedy的方式选择下一个步骤,因此它考虑的特别全面,因为不是认死理的选择最大的嘛,而是都有可能选到,所以会考虑各个动作。
所以,对于Sarsa来说,靠近悬崖的那一侧,很有可能选择往下(掉下悬崖),Qlearning则不太会(注意,这里不是一定不会,因为有一定概率会选择随机行为,具体参照开头引用的两篇文章),因此对于Sarsa来说那条路太危险,Sarsa不太愿意走,反映到数字上就是那一行的Q值相对小。
那你说挨着靠近悬崖的那一侧呢,在那一侧也很有可能选择一步往下,直接到靠近悬崖的一侧了,又危险了,所以这一行的Q值也相对来说小一些,但是会比挨着悬崖一侧的Q值大一些。
那接下来就又有问题了,既然Sarsa那么胆小,它咋不走最上面那条路呢?
那是因为绕太多路。我们认为悬崖那一侧危险的原因是R值太小,而绕太远的路也会减小R值(之前说过每走一步R值都为-1),因此绕太多路了,导致在Q表中,红色路上面的那两条路的Q值也相对(红色)来说小一些。
总个破结
综上就是我们标题问题的答案,Qlearning一般给出的是最优解,但是会危险一些,Sarsa给出的一般是次优解,但是会相对安全。
最后有想看代码上的区别的还是欢迎看我引用的两篇文章给出的代码。这里给出一部分让大家感受一下。
Qlearning
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, :].max()
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
注意 .max
Sarsa
def learn(self, s, a, r, s_, a_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, a_]
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict)
这里没有 .max了
好了就到这里。