KMP算法应该是每一本《数据结构》书都会讲的,算是知名度最高的算法之一了,但很可惜,我大二那年压根就没看懂过~~~
之后也在很多地方也都经常看到讲解KMP算法的文章,看久了好像也知道是怎么一回事,但总感觉有些地方自己还是没有完全懂明白。这两天花了点时间总结一下,有点小体会,我希望可以通过我自己的语言来把这个算法的一些细节梳理清楚,也算是考验一下自己有真正理解这个算法。
什么是KMP算法:
KMP是三位大牛:D.E.Knuth、J.H.Morris和V.R.Pratt同时发现的。其中第一位就是《计算机程序设计艺术》的作者!!
KMP算法要解决的问题就是在字符串(也叫主串)中的模式(pattern)定位问题。说简单点就是我们平时常说的关键字搜索。模式串就是关键字(接下来称它为P),如果它在一个主串(接下来称为T)中出现,就返回它的具体位置,否则返回-1(常用手段)。

首先,对于这个问题有一个很单纯的想法:从左到右一个个匹配,如果这个过程中有某个字符不匹配,就跳回去,将模式串向右移动一位。这有什么难的?
我们可以这样初始化:

之后我们只需要比较i指针指向的字符和j指针指向的字符是否一致。如果一致就都向后移动,如果不一致,如下图:

A和E不相等,那就把i指针移回第1位(假设下标从0开始),j移动到模式串的第0位,然后又重新开始这个步骤:

基于这个想法我们可以得到以下的程序:
1 /**
2
3 * 暴力破解法
4
5 * @param ts 主串
6
7 * @param ps 模式串
8
9 * @return 如果找到,返回在主串中第一个字符出现的下标,否则为-1
10
11 */
12
13 public static int bf(String ts, String ps) {
14
15 char[] t = ts.toCharArray();
16
17 char[] p = ps.toCharArray();
18
19 int i = 0; // 主串的位置
20
21 int j = 0; // 模式串的位置
22
23 while (i < t.length && j < p.length) {
24
25 if (t[i] == p[j]) { // 当两个字符相同,就比较下一个
26
27 i++;
28
29 j++;
30
31 } else {
32
33 i = i - j + 1; // 一旦不匹配,i后退
34
35 j = 0; // j归0
36
37 }
38
39 }
40
41 if (j == p.length) {
42
43 return i - j;
44
45 } else {
46
47 return -1;
48
49 }
50
51 }
上面的程序是没有问题的,但不够好!(想起我高中时候数字老师的一句话:我不能说你错,只能说你不对~~~)
如果是人为来寻找的话,肯定不会再把i移动回第1位,因为主串匹配失败的位置前面除了第一个A之外再也没有A了,我们为什么能知道主串前面只有一个A?因为我们已经知道前面三个字符都是匹配的!(这很重要)。移动过去肯定也是不匹配的!有一个想法,i可以不动,我们只需要移动j即可,如下图:

上面的这种情况还是比较理想的情况,我们最多也就多比较了再次。但假如是在主串“SSSSSSSSSSSSSA”中查找“SSSSB”,比较到最后一个才知道不匹配,然后i回溯,这个的效率是显然是最低的。
大牛们是无法忍受“暴力破解”这种低效的手段的,于是他们三个研究出了KMP算法。其思想就如同我们上边所看到的一样:“利用已经部分匹配这个有效信息,保持i指针不回溯,通过修改j指针,让模式串尽量地移动到有效的位置。”
所以,整个KMP的重点就在于当某一个字符与主串不匹配时,我们应该知道j指针要移动到哪?
接下来我们自己来发现j的移动规律:

如图:C和D不匹配了,我们要把j移动到哪?显然是第1位。为什么?因为前面有一个A相同啊:

如下图也是一样的情况:

可以把j指针移动到第2位,因为前面有两个字母是一样的:

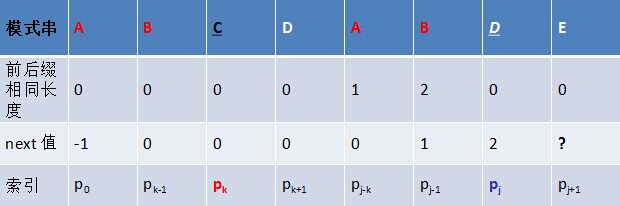
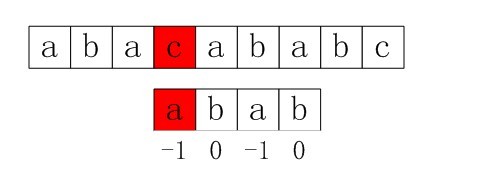
至此我们可以大概看出一点端倪,当匹配失败时,j要移动的下一个位置k。存在着这样的性质:最前面的k个字符和j之前的最后k个字符是一样的。
如果用数学公式来表示是这样的
P[0 ~ k-1] == P[j-k ~ j-1]
这个相当重要,如果觉得不好记的话,可以通过下图来理解:

弄明白了这个就应该可能明白为什么可以直接将j移动到k位置了。
因为:
当T[i] != P[j]时
有T[i-j ~ i-1] == P[0 ~ j-1]
由P[0 ~ k-1] == P[j-k ~ j-1]
必然:T[i-k ~ i-1] == P[0 ~ k-1]
公式很无聊,能看明白就行了,不需要记住。
这一段只是为了证明我们为什么可以直接将j移动到k而无须再比较前面的k个字符。
好,接下来就是重点了,怎么求这个(这些)k呢?因为在P的每一个位置都可能发生不匹配,也就是说我们要计算每一个位置j对应的k,所以用一个数组next来保存,next[j] = k,表示当T[i] != P[j]时,j指针的下一个位置。
很多教材或博文在这个地方都是讲得比较含糊或是根本就一笔带过,甚至就是贴一段代码上来,为什么是这样求?怎么可以这样求?根本就没有说清楚。而这里恰恰是整个算法最关键的地方。
1 public static int[] getNext(String ps) {
2
3 char[] p = ps.toCharArray();
4
5 int[] next = new int[p.length];
6
7 next[0] = -1;
8
9 int j = 0;
10
11 int k = -1;
12
13 while (j < p.length - 1) {
14
15 if (k == -1 || p[j] == p[k]) {
16
17 next[++j] = ++k;
18
19 } else {
20
21 k = next[k];
22
23 }
24
25 }
26
27 return next;
28
29 }
这个版本的求next数组的算法应该是流传最广泛的,代码是很简洁。可是真的很让人摸不到头脑,它这样计算的依据到底是什么?
好,先把这个放一边,我们自己来推导思路,现在要始终记住一点,next[j]的值(也就是k)表示,当P[j] != T[i]时,j指针的下一步移动位置。
先来看第一个:当j为0时,如果这时候不匹配,怎么办?

像上图这种情况,j已经在最左边了,不可能再移动了,这时候要应该是i指针后移。所以在代码中才会有next[0] = -1;这个初始化。
如果是当j为1的时候呢?

显然,j指针一定是后移到0位置的。因为它前面也就只有这一个位置了~~~
下面这个是最重要的,请看如下图:


请仔细对比这两个图。
我们发现一个规律:
当P[k] == P[j]时,
有next[j+1] == next[j] + 1
其实这个是可以证明的:
因为在P[j]之前已经有P[0 ~ k-1] == p[j-k ~ j-1]。(next[j] == k)
这时候现有P[k] == P[j],我们是不是可以得到P[0 ~ k-1] + P[k] == p[j-k ~ j-1] + P[j]。
即:P[0 ~ k] == P[j-k ~ j],即next[j+1] == k + 1 == next[j] + 1。
这里的公式不是很好懂,还是看图会容易理解些。
那如果P[k] != P[j]呢?比如下图所示:

像这种情况,如果你从代码上看应该是这一句:k = next[k];为什么是这样子?你看下面应该就明白了。

现在你应该知道为什么要k = next[k]了吧!像上边的例子,我们已经不可能找到[ A,B,A,B ]这个最长的后缀串了,但我们还是可能找到[ A,B ]、[ B ]这样的前缀串的。所以这个过程像不像在定位[ A,B,A,C ]这个串,当C和主串不一样了(也就是k位置不一样了),那当然是把指针移动到next[k]啦。
有了next数组之后就一切好办了,我们可以动手写KMP算法了:
1 public static int KMP(String ts, String ps) {
2
3 char[] t = ts.toCharArray();
4
5 char[] p = ps.toCharArray();
6
7 int i = 0; // 主串的位置
8
9 int j = 0; // 模式串的位置
10
11 int[] next = getNext(ps);
12
13 while (i < t.length && j < p.length) {
14
15 if (j == -1 || t[i] == p[j]) { // 当j为-1时,要移动的是i,当然j也要归0
16
17 i++;
18
19 j++;
20
21 } else {
22
23 // i不需要回溯了
24
25 // i = i - j + 1;
26
27 j = next[j]; // j回到指定位置
28
29 }
30
31 }
32
33 if (j == p.length) {
34
35 return i - j;
36
37 } else {
38
39 return -1;
40
41 }
42
43 }
和暴力破解相比,就改动了4个地方。其中最主要的一点就是,i不需要回溯了。
最后,来看一下上边的算法存在的缺陷。来看第一个例子:

显然,当我们上边的算法得到的next数组应该是[ -1,0,0,1 ]
所以下一步我们应该是把j移动到第1个元素咯:

不难发现,这一步是完全没有意义的。因为后面的B已经不匹配了,那前面的B也一定是不匹配的,同样的情况其实还发生在第2个元素A上。
显然,发生问题的原因在于P[j] == P[next[j]]。
所以我们也只需要添加一个判断条件即可:
public static int[] getNext(String ps) {
char[] p = ps.toCharArray();
int[] next = new int[p.length];
next[0] = -1;
int j = 0;
int k = -1;
while (j < p.length - 1) {
if (k == -1 || p[j] == p[k]) {
if (p[++j] == p[++k]) { // 当两个字符相等时要跳过
next[j] = next[k];
} else {
next[j] = k;
}
} else {
k = next[k];
}
}
return next;
}
如果没有看懂上面的部分,继续看下去,否则不用看下面。
1. 引言
本KMP原文最初写于2年多前的2011年12月,因当时初次接触KMP,思路混乱导致写也写得混乱。所以一直想找机会重新写下KMP,但苦于一直以来对KMP的理解始终不够,故才迟迟没有修改本文。
然近期因开了个算法班,班上专门讲解数据结构、面试、算法,才再次仔细回顾了这个KMP,在综合了一些网友的理解、以及算法班的两位讲师朋友曹博、邹博的理解之后,写了9张PPT,发在微博上。随后,一不做二不休,索性将PPT上的内容整理到了本文之中(后来文章越写越完整,所含内容早已不再是九张PPT 那样简单了)。
KMP本身不复杂,但网上绝大部分的文章(包括本文的2011年版本)把它讲混乱了。下面,咱们从暴力匹配算法讲起,随后阐述KMP的流程 步骤、next 数组的简单求解 递推原理 代码求解,接着基于next 数组匹配,谈到有限状态自动机,next 数组的优化,KMP的时间复杂度分析,最后简要介绍两个KMP的扩展算法。
全文力图给你一个最为完整最为清晰的KMP,希望更多的人不再被KMP折磨或纠缠,不再被一些混乱的文章所混乱。有何疑问,欢迎随时留言评论,thanks。
2. 最容易想到的匹配算法
假设现在我们面临这样一个问题:有一个文本串S,和一个模式串P,现在要查找P在S中的位置,怎么查找呢?
如果用暴力匹配的思路,并假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置,则有:
- 如果当前字符匹配成功(即S[i] == P[j]),则i++,j++,继续匹配下一个字符;
- 如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0。相当于每次匹配失败时,i 回溯,j 被置为0。
1 int ViolentMatch(char* s, char* p) 2 { 3 int sLen = strlen(s); 4 int pLen = strlen(p); 5 6 int i = 0; 7 int j = 0; 8 while (i < sLen && j < pLen) 9 { 10 if (s[i] == p[j]) 11 { 12 //①如果当前字符匹配成功(即S[i] == P[j]),则i++,j++ 13 i++; 14 j++; 15 } 16 else 17 { 18 //②如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0 19 i = i - j + 1; 20 j = 0; 21 } 22 } 23 //匹配成功,返回模式串p在文本串s中的位置,否则返回-1 24 if (j == pLen) 25 return i - j; 26 else 27 return -1; 28 }
举个例子,如果给定文本串S“BBC ABCDAB ABCDABCDABDE”,和模式串P“ABCDABD”,现在要拿模式串P去跟文本串S匹配,整个过程如下所示:
1. S[0]为B,P[0]为A,不匹配,执行第②条指令:“如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0”,S[1]跟P[0]匹配,相当于模式串要往右移动一位(i=1,j=0)

2. S[1]跟P[0]还是不匹配,继续执行第②条指令:“如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0”,S[2]跟P[0]匹配(i=2,j=0),从而模式串不断的向右移动一位(不断的执行“令i = i - (j - 1),j = 0”,i从2变到4,j一直为0)

3. 直到S[4]跟P[0]匹配成功(i=4,j=0),此时按照上面的暴力匹配算法的思路,转而执行第①条指令:“如果当前字符匹配成功(即S[i] == P[j]),则i++,j++”,可得S[i]为S[5],P[j]为P[1],即接下来S[5]跟P[1]匹配(i=5,j=1)

4. S[5]跟P[1]匹配成功,继续执行第①条指令:“如果当前字符匹配成功(即S[i] == P[j]),则i++,j++”,得到S[6]跟P[2]匹配(i=6,j=2),如此进行下去

5. 直到S[10]为空格字符,P[6]为字符D(i=10,j=6),因为不匹配,重新执行第②条指令:“如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0”,相当于S[5]跟P[0]匹配(i=5,j=0)

6. 至此,我们可以看到,如果按照暴力匹配算法的思路,尽管之前文本串和模式串已经分别匹配到了S[9]、P[5],但因为S[10]跟P[6]不匹配,所以文本串回溯到S[5],模式串回溯到P[0],从而让S[5]跟P[0]匹配。

而S[5]肯定跟P[0]失配。为什么呢?因为在之前第4步匹配中,我们已经得知S[5] = P[1] = B,而P[0] = A,即P[1] != P[0],故S[5]必定不等于P[0],所以回溯过去必然会导致失配。那有没有一种算法,让i 不往回退,只需要移动j 即可呢?
答案是肯定的。这种算法就是本文的主旨KMP算法,它利用之前已经部分匹配这个有效信息,保持i 不回溯,通过修改j 的位置,让模式串尽量地移动到有效的位置。
3. KMP算法
3.1 定义
- 假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置
- 如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;
- 如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j] 位。
- 换言之,当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值(next 数组的求解会在下文的3.3.3节中详细阐述),即移动的实际位数为:j - next[j],且此值大于等于1。
向右移动4位后,S[10]跟P[2]继续匹配。为什么要向右移动4位呢,因为移动4位后,模式串中又有个“AB”可以继续跟S[8]S[9]对应着,从而不用让i 回溯。相当于在除去字符D的模式串子串中寻找相同的前缀和后缀,然后根据前缀后缀求出next 数组,最后基于next 数组进行匹配(不关心next 数组是怎么求来的,只想看匹配过程是咋样的,可直接跳到下文3.3.4节)。

- ①寻找前缀后缀最长公共元素长度
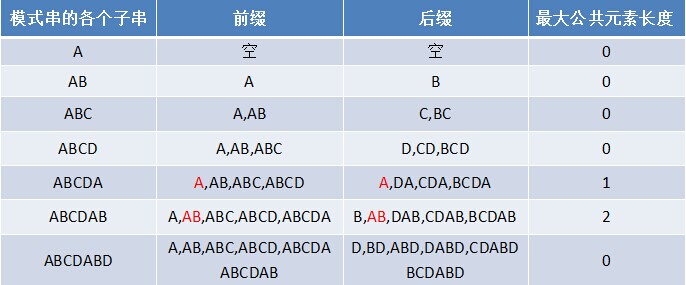
- 对于P = p0 p1 ...pj-1 pj,寻找模式串P中长度最大且相等的前缀和后缀。如果存在p0 p1 ...pk-1 pk = pj- k pj-k+1...pj-1 pj,那么在包含pj的模式串中有最大长度为k+1的相同前缀后缀。举个例子,如果给定的模式串为“abab”,那么它的各个子串的前缀后缀的公共元素的最大长度如下表格所示:
比如对于字符串aba来说,它有长度为1的相同前缀后缀a;而对于字符串abab来说,它有长度为2的相同前缀后缀ab(相同前缀后缀的长度为k + 1,k + 1 = 2)。

- ②求next数组
- next 数组考虑的是除当前字符外的最长相同前缀后缀,所以通过第①步骤求得各个前缀后缀的公共元素的最大长度后,只要稍作变形即可:将第①步骤中求得的值整体右移一位,然后初值赋为-1,如下表格所示:
比如对于aba来说,第3个字符a之前的字符串ab中有长度为0的相同前缀后缀,所以第3个字符a对应的next值为0;而对于abab来说,第4个字符b之前的字符串aba中有长度为1的相同前缀后缀a,所以第4个字符b对应的next值为1(相同前缀后缀的长度为k,k = 1)。

- ③根据next数组进行匹配
- 匹配失配,j = next [j],模式串向右移动的位数为:j - next[j]。换言之,当模式串的后缀pj-k pj-k+1, ..., pj-1 跟文本串si-k si-k+1, ..., si-1匹配成功,但pj 跟si匹配失败时,因为next[j] = k,相当于在不包含pj的模式串中有最大长度为k 的相同前缀后缀,即p0 p1 ...pk-1 = pj-k pj-k+1...pj-1,故令j = next[j],从而让模式串右移j - next[j] 位,使得模式串的前缀p0 p1, ..., pk-1对应着文本串 si-k si-k+1, ..., si-1,而后让pk 跟si 继续匹配。如下图所示:
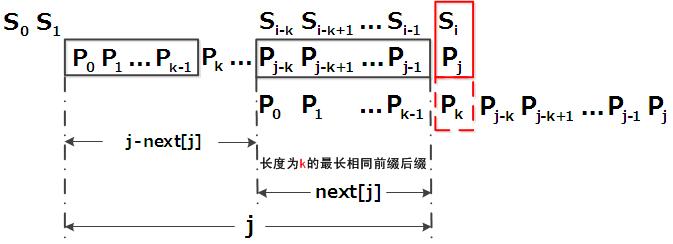
3.3 解释
3.3.1 寻找最长前缀后缀

3.3.2 基于《最大长度表》匹配
失配时,模式串向右移动的位数为:已匹配字符数 - 失配字符的上一位字符所对应的最大长度值
下面,咱们就结合之前的《最大长度表》和上述结论,进行字符串的匹配。如果给定文本串“BBC ABCDAB ABCDABCDABDE”,和模式串“ABCDABD”,现在要拿模式串去跟文本串匹配,如下图所示:
- 1. 因为模式串中的字符A跟文本串中的字符B、B、C、空格一开始就不匹配,所以不必考虑结论,直接将模式串不断的右移一位即可,直到模式串中的字符A跟文本串的第5个字符A匹配成功:
- 2. 继续往后匹配,当模式串最后一个字符D跟文本串匹配时失配,显而易见,模式串需要向右移动。但向右移动多少位呢?因为此时已经匹配的字符数为6个(ABCDAB),然后根据《最大长度表》可得失配字符D的上一位字符B对应的长度值为2,所以根据之前的结论,可知需要向右移动6 - 2 = 4 位。

- 3. 模式串向右移动4位后,发现C处再度失配,因为此时已经匹配了2个字符(AB),且上一位字符B对应的最大长度值为0,所以向右移动:2 - 0 =2 位。
- 4. A与空格失配,向右移动1 位。
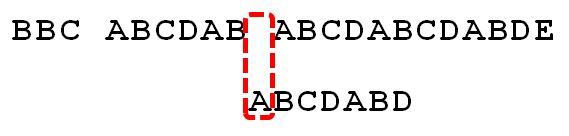
- 5. 继续比较,发现D与C 失配,故向右移动的位数为:已匹配的字符数6减去上一位字符B对应的最大长度2,即向右移动6 - 2 = 4 位。

- 6. 经历第5步后,发现匹配成功,过程结束。

通过上述匹配过程可以看出,问题的关键就是寻找模式串中最大长度的相同前缀和后缀,找到了模式串中每个字符之前的前缀和后缀公共部分的最大长度后,便可基于此匹配。而这个最大长度便正是next 数组要表达的含义。
3.3.3 根据《最大长度表》求next 数组
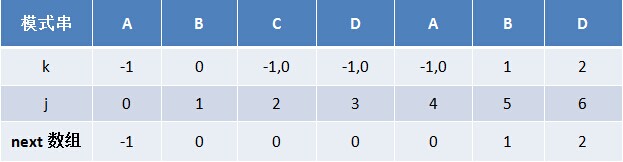
由上文,我们已经知道,字符串“ABCDABD”各个前缀后缀的最大公共元素长度分别为:

而且,根据这个表可以得出下述结论
- 失配时,模式串向右移动的位数为:已匹配字符数 - 失配字符的上一位字符所对应的最大长度值

把next 数组跟之前求得的最大长度表对比后,不难发现,next 数组相当于“最大长度值” 整体向右移动一位,然后初始值赋为-1。意识到了这一点,你会惊呼原来next 数组的求解竟然如此简单:就是找最大对称长度的前缀后缀,然后整体右移一位,初值赋为-1(当然,你也可以直接计算某个字符对应的next值,就是看这个字符之前的字符串中有多大长度的相同前缀后缀)。
换言之,对于给定的模式串:ABCDABD,它的最大长度表及next 数组分别如下:

根据最大长度表求出了next 数组后,从而有
失配时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值
而后,你会发现,无论是基于《最大长度表》的匹配,还是基于next 数组的匹配,两者得出来的向右移动的位数是一样的。为什么呢?因为:
- 根据《最大长度表》,失配时,模式串向右移动的位数 = 已经匹配的字符数 - 失配字符的上一位字符的最大长度值
- 而根据《next 数组》,失配时,模式串向右移动的位数 = 失配字符的位置 - 失配字符对应的next 值
- 其中,从0开始计数时,失配字符的位置 = 已经匹配的字符数(失配字符不计数),而失配字符对应的next 值 = 失配字符的上一位字符的最大长度值,两相比较,结果必然完全一致。
所以,你可以把《最大长度表》看做是next 数组的雏形,甚至就把它当做next 数组也是可以的,区别不过是怎么用的问题。
3.3.4 通过代码递推计算next 数组
接下来,咱们来写代码求下next 数组。
基于之前的理解,可知计算next 数组的方法可以采用递推:
- 1. 如果对于值k,已有p0 p1, ..., pk-1 = pj-k pj-k+1, ..., pj-1,相当于next[j] = k。
- 此意味着什么呢?究其本质,next[j] = k 代表p[j] 之前的模式串子串中,有长度为k 的相同前缀和后缀。有了这个next 数组,在KMP匹配中,当模式串中j 处的字符失配时,下一步用next[j]处的字符继续跟文本串匹配,相当于模式串向右移动j - next[j] 位。
举个例子,如下图,根据模式串“ABCDABD”的next 数组可知失配位置的字符D对应的next 值为2,代表字符D前有长度为2的相同前缀和后缀(这个相同的前缀后缀即为“AB”),失配后,模式串需要向右移动j - next [j] = 6 - 2 =4位。
向右移动4位后,模式串中的字符C继续跟文本串匹配。
- 2. 下面的问题是:已知next [0, ..., j],如何求出next [j + 1]呢?
对于P的前j+1个序列字符:
- 若p[k] == p[j],则next[j + 1 ] = next [j] + 1 = k + 1;
- 若p[k ] ≠ p[j],如果此时p[ next[k] ] == p[j ],则next[ j + 1 ] = next[k] + 1,否则继续递归前缀索引k = next[k],而后重复此过程。 相当于在字符p[j+1]之前不存在长度为k+1的前缀"p0 p1, …, pk-1 pk"跟后缀“pj-k pj-k+1, …, pj-1 pj"相等,那么是否可能存在另一个值t+1 < k+1,使得长度更小的前缀 “p0 p1, …, pt-1 pt” 等于长度更小的后缀 “pj-t pj-t+1, …, pj-1 pj” 呢?如果存在,那么这个t+1 便是next[ j+1]的值,此相当于利用已经求得的next 数组(next [0, ..., k, ..., j])进行P串前缀跟P串后缀的匹配。
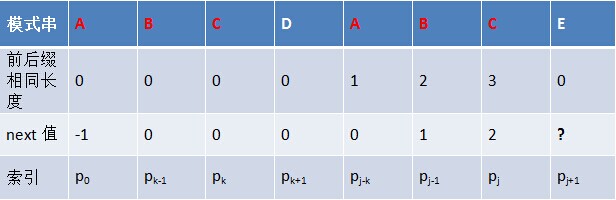
模式串的后缀:ABDE
模式串的前缀:ABC
前缀右移两位: ABC
1 void GetNext(char* p,int next[]) 2 { 3 int pLen = strlen(p); 4 next[0] = -1; 5 int k = -1; 6 int j = 0; 7 while (j < pLen - 1) 8 { 9 //p[k]表示前缀,p[j]表示后缀 10 if (k == -1 || p[j] == p[k]) 11 { 12 ++k; 13 ++j; 14 next[j] = k; 15 } 16 else 17 { 18 k = next[k]; 19 } 20 } 21 }
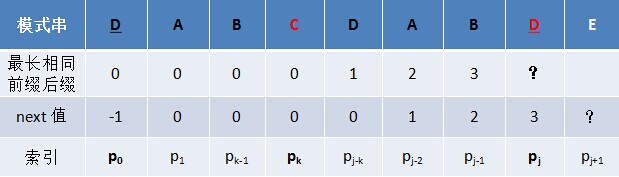
用代码重新计算下“ABCDABD”的next 数组,以验证之前通过“最长相同前缀后缀长度值右移一位,然后初值赋为-1”得到的next 数组是否正确,计算结果如下表格所示:
从上述表格可以看出,无论是之前通过“最长相同前缀后缀长度值右移一位,然后初值赋为-1”得到的next 数组,还是之后通过代码递推计算求得的next 数组,结果是完全一致的。
3.3.5 基于《next 数组》匹配
下面,我们来基于next 数组进行匹配。

还是给定文本串“BBC ABCDAB ABCDABCDABDE”,和模式串“ABCDABD”,现在要拿模式串去跟文本串匹配,如下图所示:
在正式匹配之前,让我们来再次回顾下上文2.1节所述的KMP算法的匹配流程:
- “假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置
- 如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;
- 如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j] 位。
- 换言之,当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值,即移动的实际位数为:j - next[j],且此值大于等于1。”
- 1. 最开始匹配时
- P[0]跟S[0]匹配失败
- 所以执行“如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]”,所以j = -1,故转而执行“如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++”,得到i = 1,j = 0,即P[0]继续跟S[1]匹配。
- P[0]跟S[1]又失配,j再次等于-1,i、j继续自增,从而P[0]跟S[2]匹配。
- P[0]跟S[2]失配后,P[0]又跟S[3]匹配。
- P[0]跟S[3]再失配,直到P[0]跟S[4]匹配成功,开始执行此条指令的后半段:“如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++”。
- P[0]跟S[0]匹配失败
- 2. P[1]跟S[5]匹配成功,P[2]跟S[6]也匹配成功, ...,直到当匹配到P[6]处的字符D时失配(即S[10] != P[6]),由于P[6]处的D对应的next 值为2,所以下一步用P[2]处的字符C继续跟S[10]匹配,相当于向右移动:j - next[j] = 6 - 2 =4 位。
- 3. 向右移动4位后,P[2]处的C再次失配,由于C对应的next值为0,所以下一步用P[0]处的字符继续跟S[10]匹配,相当于向右移动:j - next[j] = 2 - 0 = 2 位。
- 4. 移动两位之后,A 跟空格不匹配,模式串后移1 位。
- 5. P[6]处的D再次失配,因为P[6]对应的next值为2,故下一步用P[2]继续跟文本串匹配,相当于模式串向右移动 j - next[j] = 6 - 2 = 4 位。
- 6. 匹配成功,过程结束。
匹配过程一模一样。也从侧面佐证了,next 数组确实是只要将各个最大前缀后缀的公共元素的长度值右移一位,且把初值赋为-1 即可。
3.3.6 基于《最大长度表》与基于《next 数组》等价
我们已经知道,利用next 数组进行匹配失配时,模式串向右移动 j - next [ j ] 位,等价于已匹配字符数 - 失配字符的上一位字符所对应的最大长度值。原因是:
- j 从0开始计数,那么当数到失配字符时,j 的数值就是已匹配的字符数;
- 由于next 数组是由最大长度值表整体向右移动一位(且初值赋为-1)得到的,那么失配字符的上一位字符所对应的最大长度值,即为当前失配字符的next 值。
但为何本文不直接利用next 数组进行匹配呢?因为next 数组不好求,而一个字符串的前缀后缀的公共元素的最大长度值很容易求。例如若给定模式串“ababa”,要你快速口算出其next 数组,乍一看,每次求对应字符的next值时,还得把该字符排除之外,然后看该字符之前的字符串中有最大长度为多大的相同前缀后缀,此过程不够直接。而如果让你求其前缀后缀公共元素的最大长度,则很容易直接得出结果:0 0 1 2 3,如下表格所示:
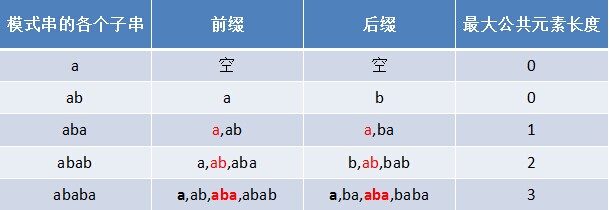
然后这5个数字 全部整体右移一位,且初值赋为-1,即得到其next 数组:-1 0 0 1 2。
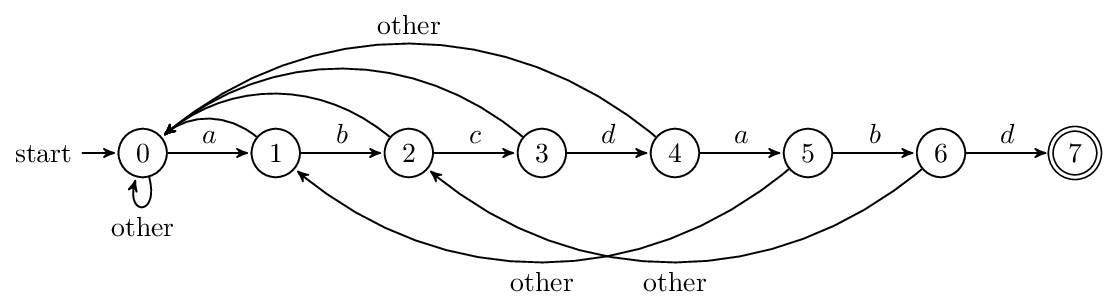
3.3.7 Next 数组与有限状态自动机
next 负责把模式串向前移动,且当第j位不匹配的时候,用第next[j]位和主串匹配,就像打了张“表”。此外,next 也可以看作有限状态自动机的状态,在已经读了多少字符的情况下,失配后,前面读的若干个字符是有用的。
3.3.8 Next 数组的优化
行文至此,咱们全面了解了暴力匹配的思路、KMP算法的原理、流程、流程之间的内在逻辑联系,以及next 数组的简单求解(《最大长度表》整体右移一位,然后初值赋为-1)和代码求解,最后基于《next 数组》的匹配,看似洋洋洒洒,清晰透彻,但以上忽略了一个小问题。
比如,如果用之前的next 数组方法求模式串“abab”的next 数组,可得其next 数组为-1 0 0 1(0 0 1 2整体右移一位,初值赋为-1),当它跟下图中的文本串去匹配的时候,发现b跟c失配,于是模式串右移j - next[j] = 3 - 1 =2位。

右移2位后,b又跟c失配。事实上,因为在上一步的匹配中,已经得知p[3] = b,与s[3] = c失配,而右移两位之后,让p[ next[3] ] = p[1] = b 再跟s[3]匹配时,必然失配。问题出在哪呢?

问题出在不该出现p[j] = p[ next[j] ]。为什么呢?理由是:当p[j] != s[i] 时,下次匹配必然是p[ next [j]] 跟s[i]匹配,如果p[j] = p[ next[j] ],必然导致后一步匹配失败(因为p[j]已经跟s[i]失配,然后你还用跟p[j]等同的值p[next[j]]去跟s[i]匹配,很显然,必然失配),所以不能允许p[j] = p[ next[j ]]。如果出现了p[j] = p[ next[j] ]咋办呢?如果出现了,则需要再次递归,即令next[j] = next[ next[j] ]。
所以,咱们得修改下求next 数组的代码。
1 //优化过后的next 数组求法 2 void GetNextval(char* p, int next[]) 3 { 4 int pLen = strlen(p); 5 next[0] = -1; 6 int k = -1; 7 int j = 0; 8 while (j < pLen - 1) 9 { 10 //p[k]表示前缀,p[j]表示后缀 11 if (k == -1 || p[j] == p[k]) 12 { 13 ++j; 14 ++k; 15 //较之前next数组求法,改动在下面4行 16 if (p[j] != p[k]) 17 next[j] = k; //之前只有这一行 18 else 19 //因为不能出现p[j] = p[ next[j ]],所以当出现时需要继续递归,k = next[k] = next[next[k]] 20 next[j] = next[k]; 21 } 22 else 23 { 24 k = next[k]; 25 } 26 } 27 }
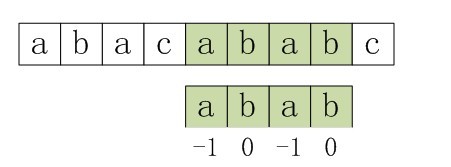
利用优化过后的next 数组求法,可知模式串“abab”的新next数组为:-1 0 -1 0。可能有些读者会问:原始next 数组是前缀后缀最长公共元素长度值右移一位, 然后初值赋为-1而得,那么优化后的next 数组如何快速心算出呢?实际上,只要求出了原始next 数组,便可以根据原始next 数组快速求出优化后的next 数组。还是以abab为例,如下表格所示:
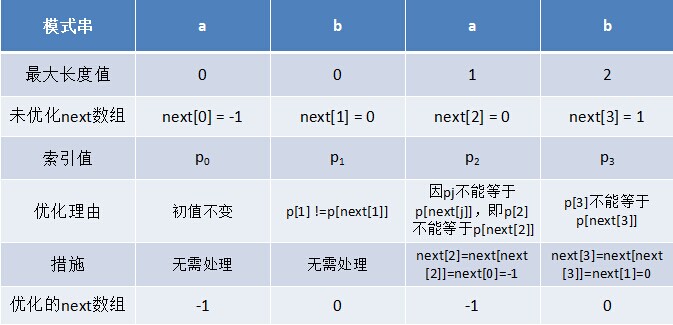
只要出现了p[next[j]] = p[j]的情况,则把next[j]的值再次递归。例如在求模式串“abab”的第2个a的next值时,如果是未优化的next值的话,第2个a对应的next值为0,相当于第2个a失配时,下一步匹配模式串会用p[0]处的a再次跟文本串匹配,必然失配。所以求第2个a的next值时,需要再次递归:next[2] = next[ next[2] ] = next[0] = -1(此后,根据优化后的新next值可知,第2个a失配时,执行“如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符”),同理,第2个b对应的next值为0。
对于优化后的next数组可以发现一点:如果模式串的后缀跟前缀相同,那么它们的next值也是相同的,例如模式串abcabc,它的前缀后缀都是abc,其优化后的next数组为:-1 0 0 -1 0 0,前缀后缀abc的next值都为-1 0 0。
然后引用下之前3.1节的KMP代码:
1 int KmpSearch(char* s, char* p) 2 { 3 int i = 0; 4 int j = 0; 5 int sLen = strlen(s); 6 int pLen = strlen(p); 7 while (i < sLen && j < pLen) 8 { 9 //①如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++ 10 if (j == -1 || s[i] == p[j]) 11 { 12 i++; 13 j++; 14 } 15 else 16 { 17 //②如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j] 18 //next[j]即为j所对应的next值 19 j = next[j]; 20 } 21 } 22 if (j == pLen) 23 return i - j; 24 else 25 return -1; 26 }
接下来,咱们继续拿之前的例子说明,整个匹配过程如下:
1. S[3]与P[3]匹配失败。
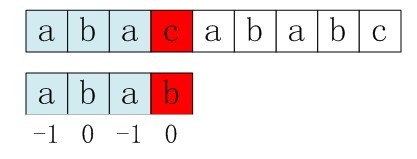
2. S[3]保持不变,P的下一个匹配位置是P[next[3]],而next[3]=0,所以P[next[3]]=P[0]与S[3]匹配。
3. 由于上一步骤中P[0]与S[3]还是不匹配。此时i=3,j=next [0]=-1,由于满足条件j==-1,所以执行“++i, ++j”,即主串指针下移一个位置,P[0]与S[4]开始匹配。最后j==pLen,跳出循环,输出结果i - j = 4(即模式串第一次在文本串中出现的位置),匹配成功,算法结束。
3.4 KMP的时间复杂度分析
- 如果模式串中存在相同前缀和后缀,即pj-k pj-k+1, ..., pj-1 = p0 p1, ..., pk-1,那么在pj跟si失配后,让模式串的前缀p0 p1...pk-1对应着文本串si-k si-k+1...si-1,而后让pk跟si继续匹配。
- 之前本应是pj跟si匹配,结果失配了,失配后,令pk跟si匹配,相当于j 变成了k,模式串向右移动j - k位。
- 因为k 的值是可变的,所以我们用next[j]表示j处字符失配后,下一次匹配模式串应该跳到的位置。换言之,失配前是j,pj跟si失配时,用p[ next[j] ]继续跟si匹配,相当于j变成了next[j],所以,j = next[j],等价于把模式串向右移动j - next [j] 位。
- 而next[j]应该等于多少呢?next[j]的值由j 之前的模式串子串中有多大长度的相同前缀后缀所决定,如果j 之前的模式串子串中(不含j)有最大长度为k的相同前缀后缀,那么next [j] = k。
“KMP的算法流程:
- 假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置
- 如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;
- 如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j] 位。”
我们发现如果某个字符匹配成功,模式串首字符的位置保持不动,仅仅是i++、j++;如果匹配失配,i 不变(即 i 不回溯),模式串会跳过匹配过的next [j]个字符。整个算法最坏的情况是,当模式串首字符位于i - j的位置时才匹配成功,算法结束。
所以,如果文本串的长度为n,模式串的长度为m,那么匹配过程的时间复杂度为O(n),算上计算next的O(m)时间,KMP的整体时间复杂度为O(m + n)。
4. 扩展1:BM算法
KMP的匹配是从模式串的开头开始匹配的,而1977年,德克萨斯大学的Robert S. Boyer教授和J Strother Moore教授发明了一种新的字符串匹配算法:Boyer-Moore算法,简称BM算法。该算法从模式串的尾部开始匹配,且拥有在最坏情况下O(N)的时间复杂度。在实践中,比KMP算法的实际效能高。
BM算法定义了两个规则:
- 坏字符规则:当文本串中的某个字符跟模式串的某个字符不匹配时,我们称文本串中的这个失配字符为坏字符,此时模式串需要向右移动,移动的位数 = 坏字符在模式串中的位置 - 坏字符在模式串中最右出现的位置。此外,如果"坏字符"不包含在模式串之中,则最右出现位置为-1。
- 好后缀规则:当字符失配时,后移位数 = 好后缀在模式串中的位置 - 好后缀在模式串上一次出现的位置,且如果好后缀在模式串中没有再次出现,则为-1。
下面举例说明BM算法。例如,给定文本串“HERE IS A SIMPLE EXAMPLE”,和模式串“EXAMPLE”,现要查找模式串是否在文本串中,如果存在,返回模式串在文本串中的位置。
1. 首先,"文本串"与"模式串"头部对齐,从尾部开始比较。"S"与"E"不匹配。这时,"S"就被称为"坏字符"(bad character),即不匹配的字符,它对应着模式串的第6位。且"S"不包含在模式串"EXAMPLE"之中(相当于最右出现位置是-1),这意味着可以把模式串后移6-(-1)=7位,从而直接移到"S"的后一位。

2. 依然从尾部开始比较,发现"P"与"E"不匹配,所以"P"是"坏字符"。但是,"P"包含在模式串"EXAMPLE"之中。因为“P”这个“坏字符”对应着模式串的第6位(从0开始编号),且在模式串中的最右出现位置为4,所以,将模式串后移6-4=2位,两个"P"对齐。

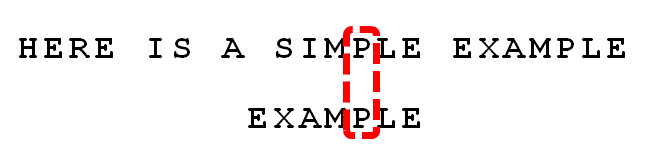
3. 依次比较,得到 “MPLE”匹配,称为"好后缀"(good suffix),即所有尾部匹配的字符串。注意,"MPLE"、"PLE"、"LE"、"E"都是好后缀。

4. 发现“I”与“A”不匹配:“I”是坏字符。如果是根据坏字符规则,此时模式串应该后移2-(-1)=3位。问题是,有没有更优的移法?
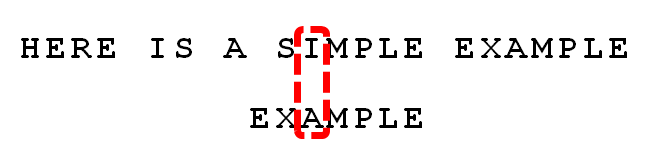
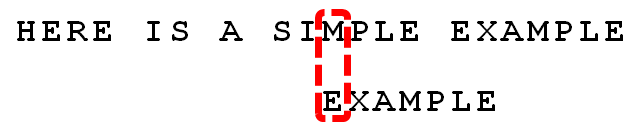
5. 更优的移法是利用好后缀规则:当字符失配时,后移位数 = 好后缀在模式串中的位置 - 好后缀在模式串中上一次出现的位置,且如果好后缀在模式串中没有再次出现,则为-1。
所有的“好后缀”(MPLE、PLE、LE、E)之中,只有“E”在“EXAMPLE”的头部出现,所以后移6-0=6位。
可以看出,“坏字符规则”只能移3位,“好后缀规则”可以移6位。每次后移这两个规则之中的较大值。这两个规则的移动位数,只与模式串有关,与原文本串无关。
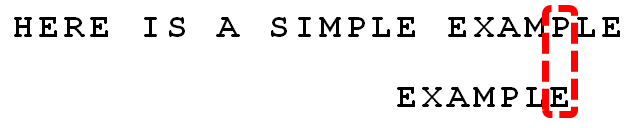
6. 继续从尾部开始比较,“P”与“E”不匹配,因此“P”是“坏字符”,根据“坏字符规则”,后移 6 - 4 = 2位。因为是最后一位就失配,尚未获得好后缀。
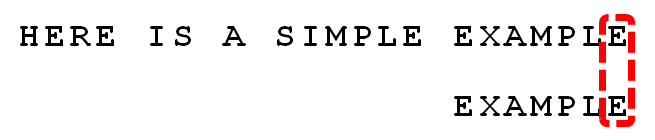
由上可知,BM算法不仅效率高,而且构思巧妙,容易理解。
5. 扩展2:Sunday算法
上文中,我们已经介绍了KMP算法和BM算法,这两个算法在最坏情况下均具有线性的查找时间。但实际上,KMP算法并不比最简单的c库函数strstr()快多少,而BM算法虽然通常比KMP算法快,但BM算法也还不是现有字符串查找算法中最快的算法,本文最后再介绍一种比BM算法更快的查找算法即Sunday算法。
Sunday算法由Daniel M.Sunday在1990年提出,它的思想跟BM算法很相似:
- 只不过Sunday算法是从前往后匹配,在匹配失败时关注的是文本串中参加匹配的最末位字符的下一位字符。
- 如果该字符没有在模式串中出现则直接跳过,即移动位数 = 匹配串长度 + 1;
- 否则,其移动位数 = 模式串中最右端的该字符到末尾的距离+1。
下面举个例子说明下Sunday算法。假定现在要在文本串"substring searching algorithm"中查找模式串"search"。
1. 刚开始时,把模式串与文本串左边对齐:
substring searching algorithm
search
^
2. 结果发现在第2个字符处发现不匹配,不匹配时关注文本串中参加匹配的最末位字符的下一位字符,即标粗的字符 i,因为模式串search中并不存在i,所以模式串直接跳过一大片,向右移动位数 = 匹配串长度 + 1 = 6 + 1 = 7,从 i 之后的那个字符(即字符n)开始下一步的匹配,如下图:
substring searching algorithm
search
^
3. 结果第一个字符就不匹配,再看文本串中参加匹配的最末位字符的下一位字符,是'r',它出现在模式串中的倒数第3位,于是把模式串向右移动3位(r 到模式串末尾的距离 + 1 = 2 + 1 =3),使两个'r'对齐,如下:
substring searching algorithm
search
^
4. 匹配成功。
回顾整个过程,我们只移动了两次模式串就找到了匹配位置,缘于Sunday算法每一步的移动量都比较大,效率很高。完。
6. 参考文献
- 《算法导论》的第十二章:字符串匹配;
- 本文中模式串“ABCDABD”的部分图来自于此文:http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html;
- 本文3.3.7节中有限状态自动机的图由微博网友@龚陆安 绘制:http://d.pr/i/NEiz;
- 北京7月暑假班邹博半小时KMP视频:http://www.julyedu.com/video/play/id/5;
- 北京7月暑假班邹博第二次课的PPT:http://yun.baidu.com/s/1mgFmw7u;
- 理解KMP 的9张PPT:http://weibo.com/1580904460/BeCCYrKz3#_rnd1405957424876;
- 详解KMP算法(多图):http://www.cnblogs.com/yjiyjige/p/3263858.html;
- 本文第4部分的BM算法参考自此文:http://www.ruanyifeng.com/blog/2013/05/boyer-moore_string_search_algorithm.html;
- http://youlvconglin.blog.163.com/blog/static/5232042010530101020857;
- 《数据结构 第二版》,严蔚敏 & 吴伟民编著;
- http://blog.csdn.net/v_JULY_v/article/details/6545192;
- http://blog.csdn.net/v_JULY_v/article/details/6111565;
- Sunday算法的原理与实现:http://blog.chinaunix.net/uid-22237530-id-1781825.html;
- 模式匹配之Sunday算法:http://blog.csdn.net/sunnianzhong/article/details/8820123;
- 一篇KMP的英文介绍:http://www.inf.fh-flensburg.de/lang/algorithmen/pattern/kmpen.htm;
- 我2014年9月3日在西安电子科技大学的面试&算法讲座视频(第36分钟~第94分钟讲KMP):http://www.julyedu.com/video/play/21。
- 一幅图理解KMP next数组的求法:http://v.atob.site/kmp-next.html 。