Python的格式转换太难了。
与其说是难,具体来说应该是“每次都会忘记该怎么处理”。所以于此记录,总的来说是编码+格式转换的记录。
本文记录环境:python3.6
经常见到的格式转换:
bytes-str
socket、网络通信和网站的很多数据传输,都是使用bytes格式在传送消息,而同时很多时候我们也需要把这些信息编程str来试着人工读信息。
此时使用方法:decode([编码格式])来完成bytes到str的转换,而str的货真价实的编码就是utf-8、gbk等等。
str-bytes
反过来,要把对人友好的字符串等转化到对机器友好的字节流,用encode()方法来完成。
bytes-十六进制数
我们通常更常用的其实是字符串转十六进制,但bytes作为桥梁更简单,只要组合一下就行了。
python3需要使用库binascii来完成很多这类在python2中可直接进行的转换,bytes转为十六进制数字文本,只需要使用binascii.b2a_hex()即可,具体更多用法可以在python的cmd模式下使用help(binascii)查看。
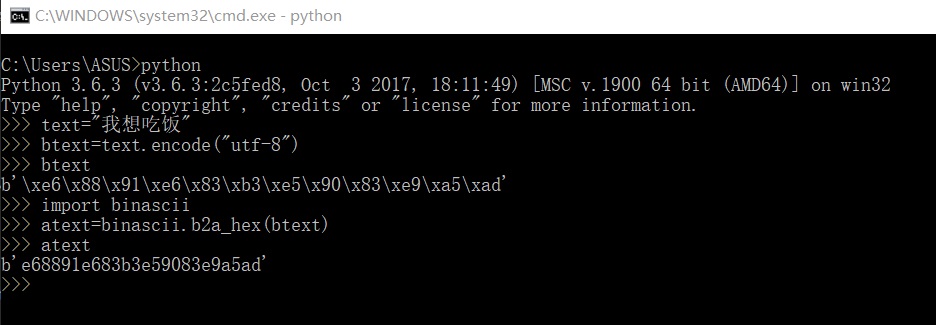
然后就可以拿这个十六进制数文本去加密或者其它处理。
十六进制数-bytes
反过来使用binascii.a2b_hex()即可。
bytes的base64编码/解码
很多网站会进一步把一些信息用base64的方式传输,有的为了节约资源,有的为了让ascii无法显示的乱码不至于被错误处理而产生误差,总之base64是好东西。
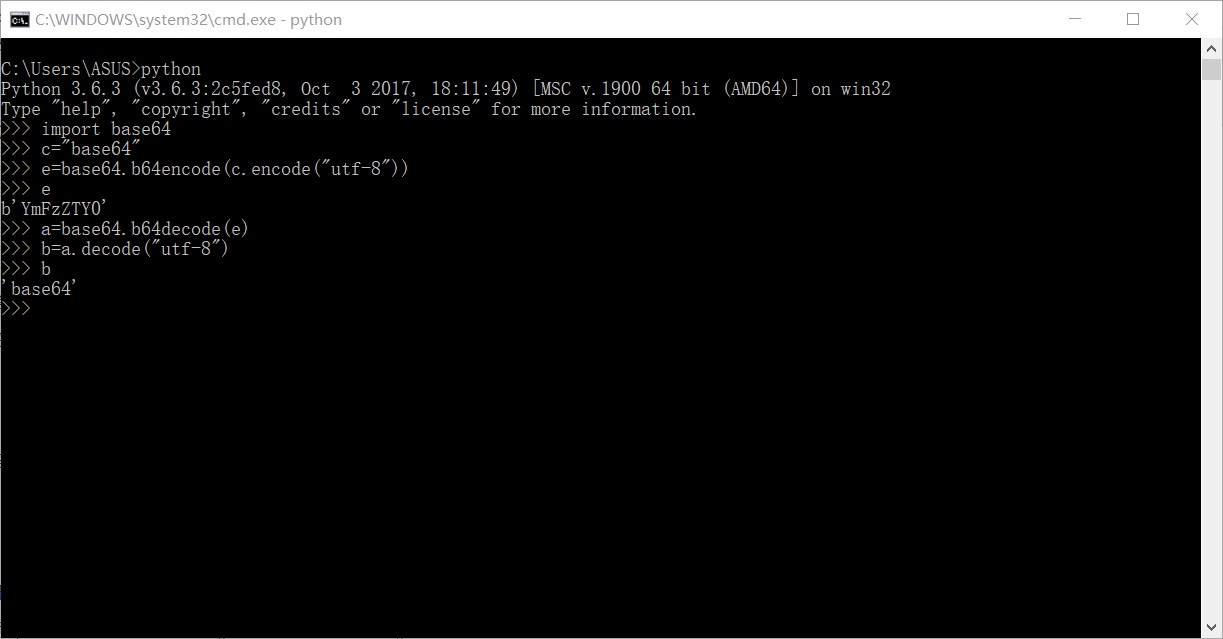
python3自带base64库,import base64后,使用base64.b64encode()或base64.b64decode()来对bytes型量进行base64编码或解码。
一些天坑的东西
1. python打开文件的编码格式
python打开文件很简单,常用的比如open(),with open as之类,然而有时候会出些小问题,比如txt文件,windows写入和读取txt默认都是unicode的方式(毕竟,没记错的话open这类函数是靠操作系统提供的中断函数完成的),这时候,如果要写入的文本是utf-8编码的,就有可能报错,有时候不报错,但是会产生乱码。(特别是用爬虫爬些稀奇古怪的网站的源代码时候,写入文件很容易变成乱码。)
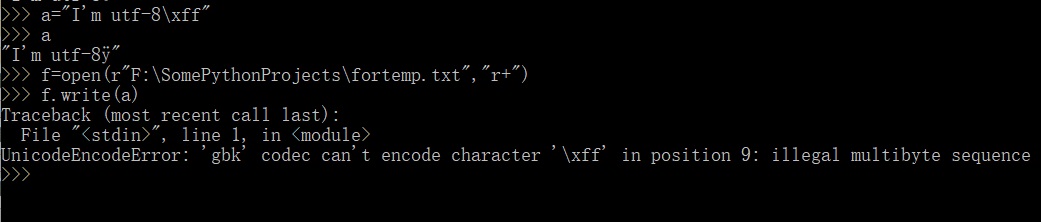
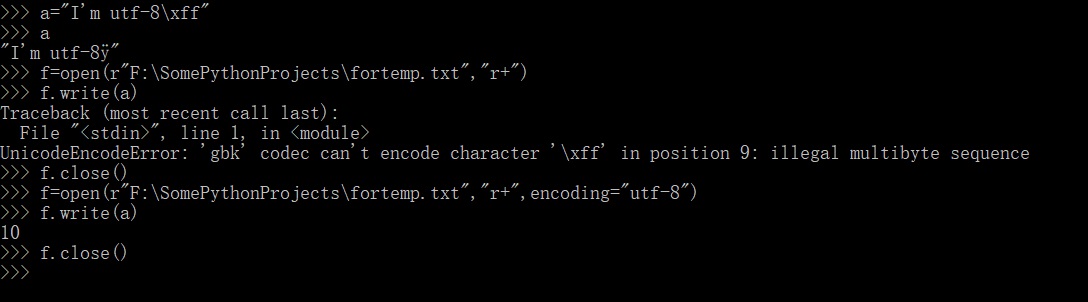
所以要设置open()的编码,在最后加上,encoding="utf-8"。可以看到成功写入10个字符。

2.request.get时候的编码
写爬虫的时候,有时候需要获取当前网页的源代码然后进行一些其他操作,比如找其它页面,对于一些能用偏静态手段处理的网页,request库仍然是最合适的选择,使用result=request.get(html)得到目标网页的应答信息,要查看源代码时,有两种方式:一是result.text,一种是result.content。这两种的区别在于,result.text会自动对网页应答进行unicode编码,这极有可能导致信息错误或乱码,而result.content则直接返回网页应答的bytes类型信息。在必要情况下,就算是要得到网页某部分的文本,也应该用content获取原始bytes信息再自行转为utf-8等编码文本来使用。