禁止码迷,布布扣,豌豆代理,码农教程,爱码网等第三方爬虫网站爬取!
在查找的使用情景中,线性表是最简单的结构,很适合作为查找部分的开始。
顺序查找
查找思想
顺序查找也可以成为线性查找,是最简单粗暴的查找法,这个应该在学习数组的时候就应该很拿手。查找过程为从表的一端开始,依次将记录的关键字和给定值进行比较,若某个记录的关键字和给定值相等则查找成功。反之若扫描整个表后,仍未找到关键字和给定值相等的记录,则查找失败。顺序查找方法对于顺序表和链表都是适用的,其实就是遍历一遍就行了。
代码实现
顺序查找唯一可以优化的地方是设置“哨兵”,这样就可以忽略 for 循环的越界检查。虽然时间复杂度并没有改变,但是这么做可以减少运算次数。
int Sequential_Search(SSTable ST,int key)
{
int idx = ST.length;
ST.data[0] = key; //设置“哨兵”
while(ST.data[idx]! = key)
{ //从后往前查找
idx--;
}
return idx;
}
算法分析
时间复杂度很明显是 O(n),我们也用 ASL 来度量一下,需要一些级数的知识。

这种算法简单粗暴,对表结构无任何要求,无论记录是否按关键字有序均可应用。但是缺点也很明显,它的平均查找长度较大,查找效率较低。
二分查找
还记得猜数字吗?
我们在学 C 语言时都有写过一个小程序叫猜数字,假设数字范围在 0~100 之间,怎么猜用的次数最少呢?

对于给定的范围,很显然是每次折半着去猜快了。
算法思想
每次查找都把查找范围缩小一半,这种手法就称之为二分查找或折半查找,这是一种效率较高的查找方法。二分查找的查找过程为,从表的中间记录开始,如果给定值和中间记录的关键字相等,则查找成功;如果给定值大于或者小于中间记录的关键字,则在表中大于或小于中间记录的那一半中查找,重复操作直到查找成功。若在某一步中查找区间为空,则代表查找失败。虽然效率很高,但是折半查找对存储结构有硬性要求——线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
查找过程
有如图有序表,首先看一下查找成功的查找过程,查找数据 27。

接下来看一下查找失败的例子,查找数据 65。

代码实现
在有序表中查找关键字 key,若找到返回对应的下标,查找失败返回 0,其中有序表的 0 下标元素不使用。
int Binary_Search(SSTable ST,int key)
{
int mid;
int low = 1; //下标 1 为记录首位
int high = ST.length; //定义最高下标为记录末位
while(low <= high) //若 low > high 表示查找区间为空,则结束
{
mid = (low + high) / 2; //去区间的中间元素
if (key < ST.data[mid]) //查找值比中值小
high = mid - 1; //调整上界为中位下标前一位
else if (key > ST.data[mid]) //查找值比中值大
low = mid + 1; //调整上界为中位下标后一位
else
{
return mid; //相等则说明 mid 为查找数据的下标
}
}
return 0;
}
算法分析
ASL 度量
根据二分查找对数组的访问顺序,可以组织成二叉判定树。通过这个二叉判定树,就可以计算 ASL。

ASL(成功):(1 + 2 × 2 + 4 × 3 + 4 × 4) ÷ 11 = 3
ASL(失败):(4 × 4 + 5 × 8) ÷ 12 = 14/3
时间复杂度
借助二叉判断树求平均 ASL,设有序表长度为 n,则 n = 2h - 1 ,其中 h 为树的深度。此时假设每个记录查找的概率相等,就可以得到:

当 n -> ∞ 时,ASL 可以近似得到以下结果:

因此二分查找的时间复杂度为 O(㏒2n),查找的效率还是很高的。
算法特点
相比之下,二分查找的优势很明显,就是比较次数少,查找效率较高。但是对结构的限制较大,只能用于顺序存储的有序表。这就说明了在查找前需要对数据排序,而排序本身是一种费时的运算。同时对有序表进行插人和删除时,为了保持顺序表的有序性,平均比较和移动表中一半元素,也需要很多的开销。
分块查找
所谓分块查找就是通过一个索引表,将数据按照某种特征分为好几部分,查找时就根据这个索引表去表中对应的地址进行查找。这个过程就类似我们查字典,我查字典的时候都是直接翻到对应的字母开始查阅。

此时在索引表中的数据是有序的,因此在索引表中既可以是顺序查找,也可以是二分查找。但是在表中的数据往往具有一个共性的特征,而不是有序的,那就要用顺序查找。由此我们也可以看出,分块查找的 ASL 有 2 部分构成,分别是在索引表中的平均查找长度 Lb 和表中的查找长度 Lw。
由此可见分块查找在表中插人和删除数据元素时,就可以去找该元素对应的块,由于块内是无序的,因此插入和删除的开销并不是很大。如果线性表既要快速查找又经常动态变化,则可采用分块查找。同时缺点也很明显,对于索引表的组织会变得较为繁琐。
SkipList (跳跃表)
下面介绍一种强大的支持查找操作的线性结构——跳跃表,这种结构可以说集成了二分查找和分块查找的特点,且效率可以和 AVL 树媲美!跳跃表以有序的方式在层次化的链表中保存元素,效率和平衡树媲美:查找、删除、添加等操作都可以在对数期望时间下完成。跳跃表体现了“空间换时间”的思想,从本质上来说,跳跃表是在单链表的基础上在选取部分结点添加索引,这些索引在逻辑关系上构成了一个新的线性表,并且索引的层数可以叠加,生成二级索引、三级索引、多级索引,以实现对结点的跳跃查找的功能。

左转博客SkipList (跳跃表)解析及其实现!
二分查找变形
插值查找
在二分查找中,我们每次都把查找范围缩小到 1/2,但是并不是所有的查找序列都适合这么划分。插值查找的思想就是,根据查找的关键字和查找表中最大记录和最小记录进行比较,以确定更好的缩小范围的方式的查找。
也就是说,二分查找的推导式是基于下标的:

插值查找的推导式是根据关键字,通过插值公式来度量:
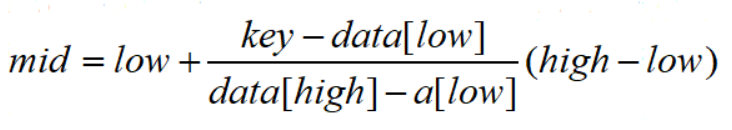
通过这个公式,将会分析关键字的特点,使得范围的缩小更为快速。代码的框架和二分查找一样,只不过 mid 变量的修改代码变为:
mid = low + (high - low) * (key - ST.data[low]) / (ST.data[high] - ST.data[low]);
斐波那契查找
所谓斐波那契查找,就是利用斐波那契数列来度量查找范围的上界和下界。这体现了一种“黄金分割”的思想,当数据量大时可以快速缩小查找范围。和插值查找类似,斐波那契查找的框架和二分查找也一样,只是缩小范围的度量方式换为斐波那契数列而已。
int Fibonacci_Search(SSTable ST, int Fib[], int key)
{ //传入已经计算好了的斐波那契数列 Fib
int mid;
int low = 1; //下标 1 为记录首位
int high = ST.length; //定义最高下标为记录末位
int k = 0;
while(ST.length > Fib[k] - 1)
{
k++; //计算表长 length 在斐波那契数列的位置
}
for (int i = ST.length; i < Fib[k] - 1; i++)
{ //将表中的数据填充至和斐波那契数列对应元素相同
ST.data[i] = ST.data[ST.length];
}
while(low <= high)
{
mid = low + Fib[k-1] - 1; //计算分隔的下标
if (key < ST.data[mid]) //查找记录小于分隔记录
{
high = mid - 1; //最高下标调整至 mid - 1
k = k - 1; //斐波那契数列下标前移 1 位
}
else if (key > ST.data[mid]) //查找记录大于分隔记录
{
low = mid + 1; //最低下标调整至 mid + 1
k = k - 2; //斐波那契数列下标前移 2 位
}
else
{
if (mid <= n)
return mid; //相等则说明 mid 为查找到的元素下表
else
return ST.length; //mid > 表长说明遇到了填充的值,返回表长
}
}
return 0;
}
参考资料
《大话数据结构》—— 程杰 著,清华大学出版社
《数据结构(C语言版|第二版)》—— 严蔚敏 李冬梅 吴伟民 编著,人民邮电出版社
SkipList (跳跃表)解析及其实现